关键词:
1.4.2之后官方并没有做功能的改动,1.4.2在word复制这块没有bug,其他版本会出现手动无法转存的情况
本文使用的后台是Java。前端为Jsp(前端都一样,后台如果语言不通得自己做 Base64编码解码)
因为公司业务需要支持IE8 ,网上其实有很多富文本框,效果都很好。
例如www.wangEditor.com 但试了一圈都不支持IE8 。
所以回到Ueditor,由于官方没有维护,新的neuditor 也不知道什么时候能支持word自动转存,只能自己想办法。
如果没有必要,不建议使用ueditor。我也是没有办法。
改动过后的插件只适合IE8。
这里要说明的一点是百度官方的编辑器不支持word图片批量转存,粘贴word后需要手动选择图片再进行上传一次操作。网上找到的大部分的示例都是这个操作。如果需要自动批量上传word图片的话可以使用WordPaster这个控件。
1.IE设置
在受信任站点里添加信任网站。
这里本机测试使用的直接是 http://localhost
因为需要读取客户端的文件,所以需要设置允许访问数据源。
ActiveXObject设置可以去网上参考,这里不列举了。
前面的
到这里 IE 的准备工作完成了。
修改ueditor.all.js关键代码
14006行附近,如果是其他版本的ueditor,在功能正常的情况下,可以拷贝下面代码。
var imgPath = attrs.src;
var imgUrl = attrs.src;
if (navigator.appName === ‘Microsoft Internet Explorer‘) //判断是否是IE浏览器
if (navigator.userAgent.match(/Trident/i) && navigator.userAgent.match(/MSIE 8.0/i)) //判断浏览器内核是否为Trident内核IE8.0
var realPath = imgPath.substring(8, imgPath.length);
var filename = imgPath.substring(imgPath.lastIndexOf(‘/‘) + 1, imgPath.length);
var result = UploadForIE.saveAttachment(filename, realPath);
if (result)
var json = eval(‘(‘ + result + ‘)‘);
imgUrl = json.url;
img.setAttr(
width: attrs.width,
height: attrs.height,
alt: attrs.alt,
word_img: attrs.src,
src: imgUrl,
‘style‘: ‘background:url(‘ + (flag ? opt.themePath + opt.theme + ‘/images/word.gif‘: opt.langPath + opt.lang + ‘/images/localimage.png‘) + ‘) no-repeat center center;border:1px solid #ddd‘
)
uploadForIE.js。
var UploadForIE =
// 保存到xml附件,并且通过ajax 上传
saveAttachment: function(upload_filename, localFilePath)
//后台接受图片保存的方法。
var upload_target_url = "uploadImg";
var strTempFile = localFilePath;
// 创建XML对象,组合XML文档数据
var xml_dom = UploadForIE.createDocument();
xml_dom.loadXML(‘<?xml version="1.0" encoding="GBK" ?> <root/>‘);
// 创建ADODB.Stream对象
var ado_stream = new ActiveXObject("adodb.stream");
// 设置流数据类型为二进制类型
ado_stream.Type = 1; // adTypeBinary
// 打开ADODB.Stream对象
ado_stream.Open();
// 将本地文件装载到ADODB.Stream对象中
ado_stream.LoadFromFile(strTempFile);
// 获取文件大小(以字节为单位)
var byte_size = ado_stream.Size;
// 设置数据传输单元大小为1KB
var byte_unit = 1024;
// 获取文件分割数据单元的数量
var read_count = parseInt((byte_size / byte_unit).toString()) + parseInt(((byte_size % byte_unit) == 0) ? 0 : 1);
// 创建XML元素节点,保存上传文件名称
var node = xml_dom.createElement("uploadFilename");
node.text = upload_filename.toString();
var root = xml_dom.documentElement;
root.appendChild(node);
// 创建XML元素节点,保存上传文件大小
var node = xml_dom.createElement("uploadFileSize");
node.text = byte_size.toString();
root.appendChild(node);
// 创建XML元素节点,保存上传文件内容
for (var i = 0; i < read_count; i++)
var node = xml_dom.createElement("uploadContent");
// 文件内容编码方式为Base64
node.dataType = "bin.base64";
// 判断当前保存的数据节点大小,根据条件进行分类操作
if ((parseInt(byte_size % byte_unit) != 0) && (i == parseInt(read_count - 1)))
// 当数据包大小不是数据单元的整数倍时,读取最后剩余的小于数据单元的所有数据
node.nodeTypedValue = ado_stream.Read();
else
// 读取一个完整数据单元的数据
node.nodeTypedValue = ado_stream.Read(byte_unit);
root.appendChild(node);
// 关闭ADODB.Stream对象
ado_stream.Close();
delete ado_stream;
// 创建Microsoft.XMLHTTP对象
// var xmlhttp = new ActiveXObject("microsoft.xmlhttp");
var xmlhttp = window.XMLHttpRequest ? new XMLHttpRequest() : new ActiveXObject("Microsoft.XMLHttp");
// 打开Microsoft.XMLHTP对象
xmlhttp.open("post", upload_target_url, false);
// 使用Microsoft.XMLHTP对象上传文件
xmlhttp.send(xml_dom);
var state = xmlhttp.readyState;
var success_state = true;
if (state != 4)
success_state = false;
var result = xmlhttp.responseText;
delete xmlhttp;
return result;
,
// 创建DOMdocuemnt
createDocument: function()
var xmldom;
var versions = ["MSXML2.DOMDocument.6.0", "MSXML2.DOMDocument.5.0", "MSXML2.DOMDocument.4.0", "MSXML2.DOMDocument.3.0", "MSXML2.DOMDocument"],
i,
len;
for (i = 0, len = versions.length; i < len; i++)
try
xmldom = new ActiveXObject(versions[i]);
if (xmldom != null) break;
catch(ex)
//跳过
alert("创建document对象失败!");
return xmldom;
UEditorAction保存图片方法
@RequestMapping("/uploadImg")
public void uploadADO(HttpServletRequest request, HttpServletResponse response)
String path1 = request.getContextPath();
String basePath = request.getScheme() + "://" + request.getServerName() + ":" + request.getServerPort() +path1;
String rootPath = request.getServletContext().getRealPath("/");
// 设置数据传输单元大小为1KB
int unit_size = 1024;
// 初始化xml文件大小(以字节为单位)
int xmlFileSize = 0;
// 初始化上传文件名称(完整文件名)
String xmlFilename = "";
// 初始化上传文件保存路径(绝对物理路径)
String xmlFilepath = "";
// 声明文件存储字节数组
byte[] xmlFileBytes = null;
try
// 初始化 SAX 串行xml文件解析器
SAXBuilder builder = new SAXBuilder();
Document doc = builder.build(request.getInputStream());
Element eRoot = doc.getRootElement();
// 获取上传文件的完整名称
Iterator it_name = eRoot.getChildren("uploadFilename").iterator();
if (it_name.hasNext())
xmlFilename = ((Element) it_name.next()).getText();
//存放的相对路径目录
String relativePath = "/temp/"+EditorUtil.getToday()+"/";
xmlFilepath = rootPath+ relativePath;
// 获取上传文件的大小
Iterator it_size = eRoot.getChildren("uploadFileSize").iterator();
if (it_size.hasNext())
xmlFileSize = Integer.parseInt(((Element) it_size.next())
.getText());
if (xmlFileSize > 0)
int unit_count = 0;
// 为存储文件内容的字节数组分配存储空间
xmlFileBytes = new byte[xmlFileSize];
// 循环读取文件内容,并保存到字节数组中
Iterator it_content = eRoot.getChildren("uploadContent")
.iterator();
while (it_content.hasNext())
// 初始化Base64编码解码器
BASE64Decoder base64 = new BASE64Decoder();
byte[] xmlNodeByteArray = base64
.decodeBuffer(((Element) it_content.next())
.getText());
if (xmlNodeByteArray.length >= unit_size)
// 读取一个完整数据单元的数据
System.arraycopy(xmlNodeByteArray, 0, xmlFileBytes,
unit_count * unit_size, unit_size);
else
// 读取小于一个数据单元的所有数据
System.arraycopy(xmlNodeByteArray, 0, xmlFileBytes,
unit_count * unit_size, xmlFileSize
% unit_size);
// 继续向下读取文件内容
unit_count++;
// 保存路径
File path = new File(xmlFilepath);
if(!path.exists())
path.mkdirs();
// 保存文件 word粘贴图片的名称
File file = new File(path,xmlFilename);
// 创建文件输入输出流
FileOutputStream fos = new FileOutputStream(file);
// 写入文件内容
fos.write(xmlFileBytes);
fos.flush();
// 关闭文件输入输出流
fos.close();
ReturnUploadImage rui = new ReturnUploadImage();
rui.setTitle(xmlFilename);//这里需要设置文件名称如:xxx.jpg
rui.setOriginal(xmlFilename);//这里需要设置文件名称如:xxx.jpg
rui.setState("SUCCESS");
rui.setUrl(basePath +relativePath+xmlFilename);
JSONObject json = new JSONObject(rui);
String result = json.toString();//这边就是为了返回给UEditor做的格式转换
response.getWriter().write(result);
catch (Exception e)
e.printStackTrace();
优化后的代码:
upload.jsp
<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%>
<%@ page contentType="text/html;charset=utf-8"%>
<%@ page import = "Xproer.*" %>
<%@ page import="org.apache.commons.lang.StringUtils" %>
<%@ page import="org.apache.commons.fileupload.*" %>
<%@ page import="org.apache.commons.fileupload.disk.*" %>
<%@ page import="org.apache.commons.fileupload.servlet.*" %>
<%out.clear();
/*
更新记录:
2013-01-25 取消对SmartUpload的使用,改用commons-fileupload组件。因为测试发现SmartUpload有内存泄露的问题。
*/
//String path = request.getContextPath();
//String basePath = request.getScheme()+"://"+request.getServerName()+":"+request.getServerPort()+path+"/";
String uname = "";// = request.getParameter("uid");
String upass = "";// = request.getParameter("fid");
// Check that we have a file upload request
boolean isMultipart = ServletFileUpload.isMultipartContent(request);
FileItemFactory factory = new DiskFileItemFactory();
ServletFileUpload upload = new ServletFileUpload(factory);
//upload.setSizeMax(262144);//256KB
List files = null;
try
files = upload.parseRequest(request);
catch (FileUploadException e)
// 处理文件尺寸过大异常
out.println("上传文件异常:"+e.toString());
return;
FileItem imgFile = null;
// 得到所有上传的文件
Iterator fileItr = files.iterator();
// 循环处理所有文件
while (fileItr.hasNext())
// 得到当前文件
imgFile = (FileItem) fileItr.next();
// 忽略简单form字段而不是上传域的文件域(<input type="text" />等)
if(imgFile.isFormField())
String fn = imgFile.getFieldName();
String fv = imgFile.getString();
if(fn.equals("uname")) uname = fv;
if(fn.equals("upass")) upass = fv;
else
break;
Uploader up = new Uploader(pageContext,request);
up.SaveFile(imgFile);
String url = up.GetFilePathRel();
out.write(url);
response.setHeader("Content-Length",url.length()+"");//返回Content-length标记,以便控件正确读取返回地址。
%>
剩下的后台功能和js参考下载文件中的UEditorAction 和 uploadForIE.js。
下面是我安装的依赖pom结构,可以根据自己的进行调整。
<dependency>
<groupId>com.baidu</groupId>
<artifactId>ueditor</artifactId>
<version>1.1.0</version>
</dependency>
基于springboot 和idea ,这里只提取了自动转存功能出来,功能还没测试,git代码没做公开,等后续测试好了再公开。
可以先使用csdn下载查看代码。
pom里引用了ueditor.jar
需要根据各自情况安装jar包
1.4.2中的jar包版本是1.1.0
mvn install:install-file -DgroupId=com.baidu -DartifactId=ueditor -Dversion=1.1.0 -Dpackaging=jar -Dfile=ueditorjsplibueditor-1.1.0.jar
运行
UeditorApplication的main方法
然后访问http://localhost:8088/ueditor/ 就可以测试了。
完成后的效果:
图片自动批量上传,不需要手动一张张选择图片上传,用户体验比百度ueditor自带的更好,传图效率更高。
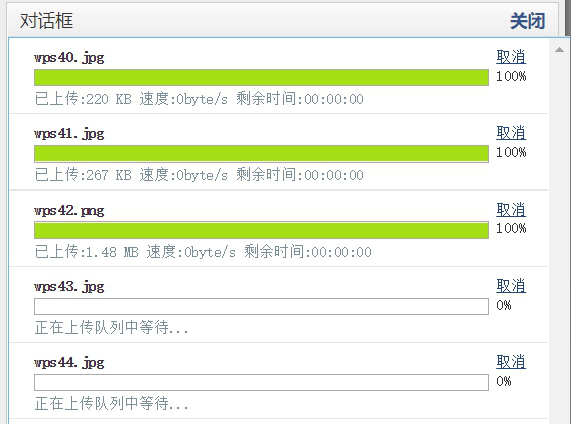
上传成功后,图片地址自动替换成服务器地址
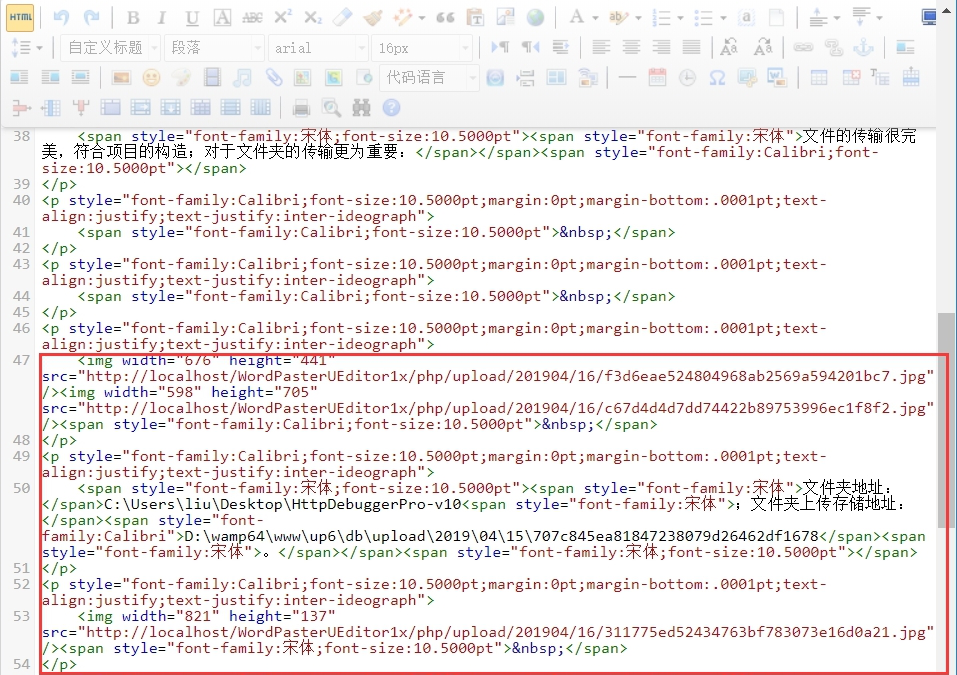
图片自动保存在服务器中

详细资料可以参考这篇文章:
讨论群:223813913
百度ueditor实现word粘贴公式自动上传
图片的复制无非有两种方法,一种是图片直接上传到服务器,另外一种转换成二进制流的base64码目前限chrome浏览器使用首先以um-editor的二进制流保存为例:打开umeditor.js,找到UM.plugins[‘autoupload‘],然后找到autoUploadHandler方法,... 查看详情
kindeditor实现word粘贴图片自动上传
tinymce是很优秀的一款富文本编辑器,可以去官网下载。https://www.tiny.cloud这里分享的是它官网的一个收费插件powerpaste的旧版本源码,但也不影响功能使用。http://blog.ncmem.com/wordpress/2019/08/07/umeditor%E7%B2%98%E8%B4%B4word%E5%9B%BE%E7%89%87/以v... 查看详情
xheditor实现ctrl+v粘贴图片并上传word粘贴带图片
tinymce是很优秀的一款富文本编辑器,可以去官网下载。https://www.tiny.cloud这里分享的是它官网的一个收费插件powerpaste的旧版本源码,但也不影响功能使用。http://blog.ncmem.com/wordpress/2019/08/07/umeditor%E7%B2%98%E8%B4%B4word%E5%9B%BE%E7%89%87/以v... 查看详情
xheditor实现ctrl+v粘贴word图片并上传
tinymce是很优秀的一款富文本编辑器,可以去官网下载。https://www.tiny.cloud这里分享的是它官网的一个收费插件powerpaste的旧版本源码,但也不影响功能使用。http://blog.ncmem.com/wordpress/2019/08/07/umeditor%E7%B2%98%E8%B4%B4word%E5%9B%BE%E7%8... 查看详情
tinymce编辑器复制粘贴图片上传
tinymce是很优秀的一款富文本编辑器,可以去官网下载。https://www.tiny.cloud这里分享的是它官网的一个收费插件powerpaste的旧版本源码,但也不影响功能使用。http://blog.ncmem.com/wordpress/2019/08/07/umeditor%E7%B2%98%E8%B4%B4word%E5%9B%BE%E7%89%87/以v... 查看详情
使用在线编辑器tinymce,将word中的图片粘贴进来时,图片却无法显示!
把word中的内容复制后,粘贴到tinyce编辑器中时,word中的图片却无法显示出来。一些特殊符号也会变成乱码,如:格式-项目符号和编号-项目符号。另外在将粘贴后的源码进行处理后(我的方法是将里面的imagedata替换成img,这一... 查看详情
怎么实现将word中的公式导入(或粘贴)到编辑中wangeditor
这种方法是servlet,编写好在web.xml里配置servlet-class和servlet-mapping即可使用后台(服务端)java服务代码:(上传至ROOT/lqxcPics文件夹下)<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%><%@&n 查看详情
富文本编辑器能够直接从word中复制粘贴公式
tinymce是很优秀的一款富文本编辑器,可以去官网下载。https://www.tiny.cloud这里分享的是它官网的一个收费插件powerpaste的旧版本源码,但也不影响功能使用。http://blog.ncmem.com/wordpress/2019/08/07/umeditor%E7%B2%98%E8%B4%B4word%E5%9B%BE%E7%89%87/以v... 查看详情
tinymce粘贴word文档,粘贴上去后word文档的样式全被取消了。请求帮助一下。嘉缘人才系统的程序
粘贴到tinyMCE在线编辑器上后要保持word文档的样式字体的颜色和大小那些。tinymce没有word的字处理那么多的功能,可以说是不支持格式,就像你把word中加粗的字粘贴到txt中一样,不会再有加粗效果了。如果非要支持的话,只能找... 查看详情
tinymce编辑支持word内容和截图的复制黏贴
由于工作需要必须将word文档内容粘贴到编辑器中使用但发现word中的图片粘贴后变成了file:///xxxx.jpg这种内容,如果上传到服务器后其他人也访问不了,网上找了很多编辑器发现没有一个能直接解决这个问题考虑到自己除了工作其... 查看详情
怎么实现将word中的公式导入(或粘贴)到编辑中ckeditor
Chrome+IE默认支持粘贴剪切板中的图片,但是我要发布的文章存在word里面,图片多达数十张,我总不能一张一张复制吧?Chrome高版本提供了可以将单张图片转换在BASE64字符串的功能。但是无法处理多张图片。而且转换成BASE64后是... 查看详情
umeditor实现ctrl+v粘贴word图片并上传
这种方法是servlet,编写好在web.xml里配置servlet-class和servlet-mapping即可使用后台(服务端)java服务代码:(上传至ROOT/lqxcPics文件夹下)<%@ page language="java" import="java.util.*" pageEncoding="utf-8"%><%@& 查看详情
怎样在word中快速输入复杂的公式(数学、物理或化学公式)?
...公式的部分。2)打开网站:www.gongshi996.com,直接按Ctrl+V粘贴,左边方框会显示截取的公式图片。3)点击“识别公式”。4)复制MathML格式的公式。5)在word文件中,右键选择“粘贴”-“只保留文本”粘贴即可。下面几种快速输入... 查看详情
tinymce - 如何禁用智能粘贴
】tinymce-如何禁用智能粘贴【英文标题】:tinymce-howtodisablesmartpaste【发布时间】:2012-12-2607:04:49【问题描述】:当我在tinymce编辑器中粘贴某些内容并将其保存到db时,它会自动保存与该副本相关的所有样式。我只想保留html标签而... 查看详情
关于xheditor粘贴图片自动上传
Chrome+IE默认支持粘贴剪切板中的图片,但是我要发布的文章存在word里面,图片多达数十张,我总不能一张一张复制吧?Chrome高版本提供了可以将单张图片转换在BASE64字符串的功能。但是无法处理多张图片。而且转换成BASE64后是... 查看详情
关于umeditor粘贴图片自动上传
Chrome+IE默认支持粘贴剪切板中的图片,但是我要发布的文章存在word里面,图片多达数十张,我总不能一张一张复制吧?Chrome高版本提供了可以将单张图片转换在BASE64字符串的功能。但是无法处理多张图片。而且转换成BASE64后是... 查看详情
将粘贴内容复制到 TinyMCE 输入会导致 HTML 臃肿
】将粘贴内容复制到TinyMCE输入会导致HTML臃肿【英文标题】:Copy&PastecontentintoTinyMCEinputresultsinbloatedHTML【发布时间】:2011-07-2314:14:30【问题描述】:我将TinyMCE用于各种项目。我遇到的问题是ATM是很多用户复制并粘贴来自Word或Op... 查看详情
word图片粘贴上传控件,直接粘贴图片到编辑器-dede
...出来。减少排版复杂的工作量。下面是借用百度doc来快速实现这个word粘贴到富文本编辑器里面方法一:工具/原料百度doc任意富文本编辑器,以UEDdito为例方法/步骤登录,http://word.baidu.com点击右上角导入文档,如图所示导入后,... 查看详情