关键词:
背景
缓存的主要作用是暂时在内存中保存业务系统的数据处理结果,并且等待下次访问使用。在日长开发有很多场合,有一些数据量不是很大,不会经常改动,并且访问非常频繁。但是由于受限于硬盘IO的性能或者远程网络等原因获取可能非常的费时。会导致我们的程序非常缓慢,这在某些业务上是不能忍的!而缓存正是解决这类问题的神器!
当然也并不是说你用了缓存你的系统就一定会变快,建议在用之前看一下使用缓存的9大误区(上) 使用缓存的9大误区(下)
缓存在很多系统和架构中都用广泛的应用,例如:
- CPU缓存
- 操作系统缓存
- HTTP缓存
- 数据库缓存
- 静态文件缓存
- 本地缓存
- 分布式缓存
可以说在计算机和网络领域,缓存是无处不在的。可以这么说,只要有硬件性能不对等,涉及到网络传输的地方都会有缓存的身影。
缓存总体可分为两种 集中式缓存 和 分布式缓存
“集中式缓存"与"分布式缓存"的区别其实就在于“集中”与"非集中"的概念,其对象可能是服务器、内存条、硬盘等。比如:
1.服务器版本:
- 缓存集中在一台服务器上,为集中式缓存。
- 缓存分散在不同的服务器上,为分布式缓存。
2.内存条版本:
- 缓存集中在一台服务器的一条内存条上,为集中式缓存。
- 缓存分散在一台服务器的不同内存条上,为分布式缓存。
3.硬盘版本:
- 缓存集中在一台服务器的一个硬盘上,为集中式缓存。
- 缓存分散在一台服务器的不同硬盘上,为分布式缓存。
想了解分布式缓存可以看一下浅谈分布式缓存那些事儿。
这是几个当前比较流行的java 分布式缓存框架5个强大的Java分布式缓存框架推荐。
而我们今天要讲的是集中式内存缓存guava cache,这是当前我们项目正在用的缓存工具,研究一下感觉还蛮好用的。当然也有很多其他工具,还是看个人喜欢。oschina上面也有很多类似开源的java缓存框架
正文
Guava Cache与ConcurrentMap很相似,但也不完全一样。最基本的区别是ConcurrentMap会一直保存所有添加的元素,直到显式地移除。相对地,Guava Cache为了限制内存占用,通常都设定为自动回收元素。在某些场景下,尽管LoadingCache 不回收元素,它也是很有用的,因为它会自动加载缓存。
Guava Cache是在内存中缓存数据,相比较于数据库或redis存储,访问内存中的数据会更加高效。Guava官网介绍,下面的这几种情况可以考虑使用Guava Cache:
-
愿意消耗一些内存空间来提升速度。
-
预料到某些键会被多次查询。
-
缓存中存放的数据总量不会超出内存容量。
所以,可以将程序频繁用到的少量数据存储到Guava Cache中,以改善程序性能。下面对Guava Cache的用法进行详细的介绍。
构建缓存对象
接口Cache代表一块缓存,它有如下方法:
1 public interface Cache<K, V>
2 V get(K key, Callable<? extends V> valueLoader) throws ExecutionException;
3
4 ImmutableMap<K, V> getAllPresent(Iterable<?> keys);
5
6 void put(K key, V value);
7
8 void putAll(Map<? extends K, ? extends V> m);
9
10 void invalidate(Object key);
11
12 void invalidateAll(Iterable<?> keys);
13
14 void invalidateAll();
15
16 long size();
17
18 CacheStats stats();
19
20 ConcurrentMap<K, V> asMap();
21
22 void cleanUp();
23
可以通过CacheBuilder类构建一个缓存对象,CacheBuilder类采用builder设计模式,它的每个方法都返回CacheBuilder本身,直到build方法被调用。构建一个缓存对象代码如下。
1 public class StudyGuavaCache
2 public static void main(String[] args)
3 Cache<String,String> cache = CacheBuilder.newBuilder().build();
4 cache.put("word","Hello Guava Cache");
5 System.out.println(cache.getIfPresent("word"));
6
7
上面的代码通过CacheBuilder.newBuilder().build()这句代码创建了一个Cache缓存对象,并在缓存对象中存储了key为word,value为Hello Guava Cache的一条记录。可以看到Cache非常类似于JDK中的Map,但是相比于Map,Guava Cache提供了很多更强大的功能。
从LoadingCache查询的正规方式是使用get(K)方法。这个方法要么返回已经缓存的值,要么使用CacheLoader向缓存原子地加载新值(通过load(String key) 方法加载)。由于CacheLoader可能抛出异常,LoadingCache.get(K)也声明抛出ExecutionException异常。如果你定义的CacheLoader没有声明任何检查型异常,则可以通过getUnchecked(K)查找缓存;但必须注意,一旦CacheLoader声明了检查型异常,就不可以调用getUnchecked(K)。
1 LoadingCache<Key, Value> cache = CacheBuilder.newBuilder()
2 .build(
3 new CacheLoader<Key, Value>()
4 public Value load(Key key) throws AnyException
5 return createValue(key);
6
7 );
8 ...
9 try
10 return cache.get(key);
11 catch (ExecutionException e)
12 throw new OtherException(e.getCause());
13
设置最大存储
Guava Cache可以在构建缓存对象时指定缓存所能够存储的最大记录数量。当Cache中的记录数量达到最大值后再调用put方法向其中添加对象,Guava会先从当前缓存的对象记录中选择一条删除掉,腾出空间后再将新的对象存储到Cache中。
1 public class StudyGuavaCache
2 public static void main(String[] args)
3 Cache<String,String> cache = CacheBuilder.newBuilder()
4 .maximumSize(2)
5 .build();
6 cache.put("key1","value1");
7 cache.put("key2","value2");
8 cache.put("key3","value3");
9 System.out.println("第一个值:" + cache.getIfPresent("key1"));
10 System.out.println("第二个值:" + cache.getIfPresent("key2"));
11 System.out.println("第三个值:" + cache.getIfPresent("key3"));
12
13
上面代码在构造缓存对象时,通过CacheBuilder类的maximumSize方法指定Cache最多可以存储两个对象,然后调用Cache的put方法向其中添加了三个对象。程序执行结果如下图所示,可以看到第三条对象记录的插入,导致了第一条对象记录被删除。

设置过期时间
在构建Cache对象时,可以通过CacheBuilder类的expireAfterAccess和expireAfterWrite两个方法为缓存中的对象指定过期时间,使用`CacheBuilder`构建的缓存不会“自动”执行清理和逐出值,也不会在值到期后立即执行或逐出任何类型。相反,它在写入操作期间执行少量维护,或者在写入很少的情况下偶尔执行读取操作。其中,expireAfterWrite方法指定对象被写入到缓存后多久过期,expireAfterAccess指定对象多久没有被访问后过期。
1 public class StudyGuavaCache
2 public static void main(String[] args) throws InterruptedException
3 Cache<String,String> cache = CacheBuilder.newBuilder()
4 .maximumSize(2)
5 .expireAfterWrite(3,TimeUnit.SECONDS)
6 .build();
7 cache.put("key1","value1");
8 int time = 1;
9 while(true)
10 System.out.println("第" + time++ + "次取到key1的值为:" + cache.getIfPresent("key1"));
11 Thread.sleep(1000);
12
13
14
上面的代码在构造Cache对象时,通过CacheBuilder的expireAfterWrite方法指定put到Cache中的对象在3秒后会过期。在Cache对象中存储一条对象记录后,每隔1秒读取一次这条记录。程序运行结果如下图所示,可以看到,前三秒可以从Cache中获取到对象,超过三秒后,对象从Cache中被自动删除。

下面代码是expireAfterAccess的例子。
1 public class StudyGuavaCache
2 public static void main(String[] args) throws InterruptedException
3 Cache<String,String> cache = CacheBuilder.newBuilder()
4 .maximumSize(2)
5 .expireAfterAccess(3,TimeUnit.SECONDS)
6 .build();
7 cache.put("key1","value1");
8 int time = 1;
9 while(true)
10 Thread.sleep(time*1000);
11 System.out.println("睡眠" + time++ + "秒后取到key1的值为:" + cache.getIfPresent("key1"));
12
13
14
通过CacheBuilder的expireAfterAccess方法指定Cache中存储的对象如果超过3秒没有被访问就会过期。while中的代码每sleep一段时间就会访问一次Cache中存储的对象key1,每次访问key1之后下次sleep的时间会加长一秒。程序运行结果如下图所示,从结果中可以看出,当超过3秒没有读取key1对象之后,该对象会自动被Cache删除。

也可以同时用expireAfterAccess和expireAfterWrite方法指定过期时间,这时只要对象满足两者中的一个条件就会被自动过期删除。
Guava Cache缓存过期后不一定会立马被清理,一般会在Cache整体被读取一定次数后清理。这中策略对性能是有好处的,如果想强制清理可以手动调用`Cache.cleanup()`或者使用`ScheduledExecutorService`来完成定期清理
弱引用
可以通过weakKeys和weakValues方法指定Cache只保存对缓存记录key和value的弱引用。这样当没有其他强引用指向key和value时,key和value对象就会被垃圾回收器回收。
1 public class StudyGuavaCache
2 public static void main(String[] args) throws InterruptedException
3 Cache<String,Object> cache = CacheBuilder.newBuilder()
4 .maximumSize(2)
5 .weakValues()
6 .build();
7 Object value = new Object();
8 cache.put("key1",value);
9
10 value = new Object();//原对象不再有强引用
11 System.gc();
12 System.out.println(cache.getIfPresent("key1"));
13
14
上面代码的打印结果是null。构建Cache时通过weakValues方法指定Cache只保存记录值的一个弱引用。当给value引用赋值一个新的对象之后,就不再有任何一个强引用指向原对象。System.gc()触发垃圾回收后,原对象就被清除了。
显示清除
可以调用Cache的invalidateAll或invalidate方法显示删除Cache中的记录。invalidate方法一次只能删除Cache中一个记录,接收的参数是要删除记录的key。invalidateAll方法可以批量删除Cache中的记录,当没有传任何参数时,invalidateAll方法将清除Cache中的全部记录。invalidateAll也可以接收一个Iterable类型的参数,参数中包含要删除记录的所有key值。下面代码对此做了示例。
1 public class StudyGuavaCache
2 public static void main(String[] args) throws InterruptedException
3 Cache<String,String> cache = CacheBuilder.newBuilder().build();
4 Object value = new Object();
5 cache.put("key1","value1");
6 cache.put("key2","value2");
7 cache.put("key3","value3");
8
9 List<String> list = new ArrayList<String>();
10 list.add("key1");
11 list.add("key2");
12
13 cache.invalidateAll(list);//批量清除list中全部key对应的记录
14 System.out.println(cache.getIfPresent("key1"));
15 System.out.println(cache.getIfPresent("key2"));
16 System.out.println(cache.getIfPresent("key3"));
17
18
代码中构造了一个集合list用于保存要删除记录的key值,然后调用invalidateAll方法批量删除key1和key2对应的记录,只剩下key3对应的记录没有被删除。
移除监听器
可以为Cache对象添加一个移除监听器,这样当有记录被删除时可以感知到这个事件。
1 public class StudyGuavaCache
2 public static void main(String[] args) throws InterruptedException
3 RemovalListener<String, String> listener = new RemovalListener<String, String>()
4 public void onRemoval(RemovalNotification<String, String> notification)
5 System.out.println("[" + notification.getKey() + ":" + notification.getValue() + "] is removed!");
6
7 ;
8 Cache<String,String> cache = CacheBuilder.newBuilder()
9 .maximumSize(3)
10 .removalListener(listener)
11 .build();
12 Object value = new Object();
13 cache.put("key1","value1");
14 cache.put("key2","value2");
15 cache.put("key3","value3");
16 cache.put("key4","value3");
17 cache.put("key5","value3");
18 cache.put("key6","value3");
19 cache.put("key7","value3");
20 cache.put("key8","value3");
21
22
removalListener方法为Cache指定了一个移除监听器,这样当有记录从Cache中被删除时,监听器listener就会感知到这个事件。程序运行结果如下图所示。

自动加载
Cache的get方法有两个参数,第一个参数是要从Cache中获取记录的key,第二个记录是一个Callable对象。当缓存中已经存在key对应的记录时,get方法直接返回key对应的记录。如果缓存中不包含key对应的记录,Guava会启动一个线程执行Callable对象中的call方法,call方法的返回值会作为key对应的值被存储到缓存中,并且被get方法返回。下面是一个多线程的例子:
1 public class StudyGuavaCache
2
3 private static Cache<String,String> cache = CacheBuilder.newBuilder()
4 .maximumSize(3)
5 .build();
6
7 public static void main(String[] args) throws InterruptedException
8
9 new Thread(new Runnable()
10 public void run()
11 System.out.println("thread1");
12 try
13 String value = cache.get("key", new Callable<String>()
14 public String call() throws Exception
15 System.out.println("load1"); //加载数据线程执行标志
16 Thread.sleep(1000); //模拟加载时间
17 return "auto load by Callable";
18
19 );
20 System.out.println("thread1 " + value);
21 catch (ExecutionException e)
22 e.printStackTrace();
23
24
25 ).start();
26
27 new Thread(new Runnable()
28 public void run()
29 System.out.println("thread2");
30 try
31 String value = cache.get("key", new Callable<String>()
32 public String call() throws Exception
33 System.out.println("load2"); //加载数据线程执行标志
34 Thread.sleep(1000); //模拟加载时间
35 return "auto load by Callable";
36
37 );
38 System.out.println("thread2 " + value);
39 catch (ExecutionException e)
40 e.printStackTrace();
41
42
43 ).start();
44
45
这段代码中有两个线程共享同一个Cache对象,两个线程同时调用get方法获取同一个key对应的记录。由于key对应的记录不存在,所以两个线程都在get方法处阻塞。此处在call方法中调用Thread.sleep(1000)模拟程序从外存加载数据的时间消耗。代码的执行结果如下图:

从结果中可以看出,虽然是两个线程同时调用get方法,但只有一个get方法中的Callable会被执行(没有打印出load2)。Guava可以保证当有多个线程同时访问Cache中的一个key时,如果key对应的记录不存在,Guava只会启动一个线程执行get方法中Callable参数对应的任务加载数据存到缓存。当加载完数据后,任何线程中的get方法都会获取到key对应的值。
统计信息
可以对Cache的命中率、加载数据时间等信息进行统计。在构建Cache对象时,可以通过CacheBuilder的recordStats方法开启统计信息的开关。开关开启后Cache会自动对缓存的各种操作进行统计,调用Cache的stats方法可以查看统计后的信息。
1 public class StudyGuavaCache
2 public static void main(String[] args) throws InterruptedException
3 Cache<String,String> cache = CacheBuilder.newBuilder()
4 .maximumSize(3)
5 .recordStats() //开启统计信息开关
6 .build();
7 cache.put("key1","value1");
8 cache.put("key2","value2");
9 cache.put("key3","value3");
10 cache.put("key4","value4");
11
12 cache.getIfPresent("key1");
13 cache.getIfPresent("key2");
14 cache.getIfPresent("key3");
15 cache.getIfPresent("key4");
16 cache.getIfPresent("key5");
17 cache.getIfPresent("key6");
18
19 System.out.println(cache.stats()); //获取统计信息
20
21
程序执行结果如下图所示:

这些统计信息对于调整缓存设置是至关重要的,在性能要求高的应用中应该密切关注这些数据
LoadingCache
LoadingCache是Cache的子接口,相比较于Cache,当从LoadingCache中读取一个指定key的记录时,如果该记录不存在,则LoadingCache可以自动执行加载数据到缓存的操作。LoadingCache接口的定义如下:
1 public interface LoadingCache<K, V> extends Cache<K, V>, Function<K, V>
2
3 V get(K key) throws ExecutionException;
4
5 V getUnchecked(K key);
6
7 ImmutableMap<K, V> getAll(Iterable<? extends K> keys) throws ExecutionException;
8
9 V apply(K key);
10
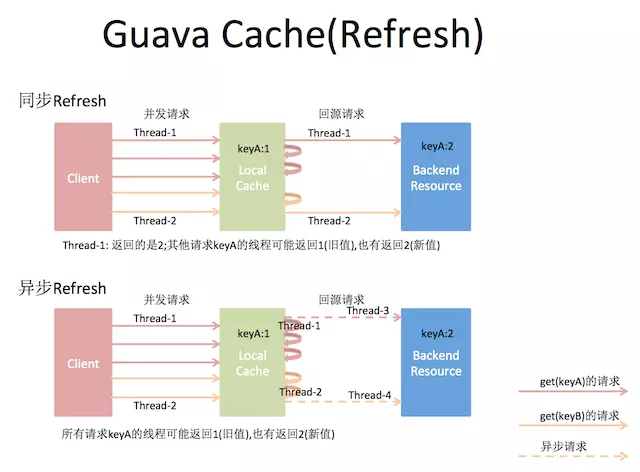
11 void refresh(K key);
12
13 @Override
14 ConcurrentMap<K, V> asMap();
15
与构建Cache类型的对象类似,LoadingCache类型的对象也是通过CacheBuilder进行构建,不同的是,在调用CacheBuilder的build方法时,必须传递一个CacheLoader类型的参数,CacheLoader的load方法需要我们提供实现。当调用LoadingCache的get方法时,如果缓存不存在对应key的记录,则CacheLoader中的load方法会被自动调用从外存加载数据,load方法的返回值会作为key对应的value存储到LoadingCache中,并从get方法返回。
1 public class StudyGuavaCache
2 public static void main(String[] args) throws ExecutionException
3 CacheLoader<String, String> loader = new CacheLoader<String, String> ()
4 public String load(String key) throws Exception
5 Thread.sleep(1000); //休眠1s,模拟加载数据
6 System.out.println(key + " is loaded from a cacheLoader!");
7 return key + "‘s value";
8
9 ;
10
11 LoadingCache<String,String> loadingCache = CacheBuilder.newBuilder()
12 .maximumSize(3)
13 .build(loader);//在构建时指定自动加载器
14
15 loadingCache.get("key1");
16 loadingCache.get("key2");
17 loadingCache.get("key3");
18
19
程序执行结果如下图所示:

转自:
https://segmentfault.com/a/1190000011105644
https://www.jianshu.com/p/64b0df87e51b



 8.png
8.png
 2.png
2.png
 3.png
3.png
 4.png
4.png
 5.png
5.png
 6.png
6.png
 7.png
7.png