关键词:
版权声明:本文由文智原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/92
来源:腾云阁 https://www.qcloud.com/community
情感分类是对带有感情色彩的主观性文本进行分析、推理的过程,即分析对说话人的态度,倾向正面,还是反面。它与传统的文本主题分类又不相同,传统主题分类是分析文本讨论的客观内容,而情感分类是要从文本中得到它是否支持某种观点的信息。比如,“日媒:认为歼-31能够抗衡F-35,这种说法颇具恭维的意味。”传统主题分类是要将其归为类别为“军事”主题,而情感分类则要挖掘出日媒对于“歼-31能够抗衡F-35”这个观点,持反面态度。这是一项具有较大实用价值的分类技术,可以在一定程度上解决网络评论信息杂乱的现象,方便用户准确定位所需信息。按照处理文本的粒度不同,情感分析可分为词语级、短语级、句子级、篇章级以及多篇章级等几个研究层次。按照处理文本的类别不同,可分为基于新闻评论的情感分析和基于产品评论的情感分析。
文智系统提供了一套情感分类的流程,可以对句子极别的评论进行分析,判断情感的正负倾向。接入业务的用户只需要将待分析文本按照规定的协议上传,就能实时得到情感分析的反馈。如果持续上传不同时间段的评论、综合分析,还能得到事件的发展趋势,或者产品的情感走势等。
一.常用分类方法介绍
文本分类方法一般包含如下几个步骤:训练语料准备、文本预处理、特征挖掘、分类算法选择、分类应用。具体的分类流程可以参考另一篇KM文章《文智背后的奥秘—自动文本分类》。这里,对一些常用的特征挖掘和分类算法做简单的介绍。
1.1特征挖掘方法
常见的特征选择方法有:TF-IDF、卡方、互信息、信息增益、X2统计量、交叉熵、Fisher判别式等方法,这里介绍一下工业上常用的两种方法。
1.1.1 TF-IDF
TF-IDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。这里介绍一种对 TF-IDF 的傻瓜理解法:
TF:词频,表示特征t在文档D中出现的次数,比如一篇谈论乔布斯的文章,可预期“iphone”、“苹果”的TF值为较高。
DF:包含特征t的文档数,DF越高,表示特征X对于衡量文档之间的区别作用低。比如“我”、“的”这样的词,DF一般最高。
IDF:定义为IDF =log(|D|/DF),|D|为所有文档数。与DF成反比,IDF值越高,表示特征t对区别文档的意义越大。最终定义:TF-IDF=TF*IDF
1.1.2 信息增益
信息增益 (IG) 是公认较好的特征选择方法,它刻画了一个词语在文本中出现与否对文本情感分类的影响,即一个词语在文本中出现前后的信息嫡之差。傻瓜式理解下信息增益: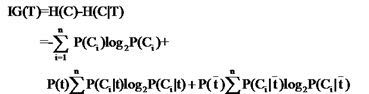
其中,n是总类别数,P(Ci)是第i类出现的概率,若每类平均出现,则P(Ci)=1/n.
P(t)是出现词语t的文档数除以总文档数,p(t否)=1-p(t).
P(Ci|t)即t出现时,Ci出现的概率,等于出现t且属于Ci的文档数除以所有出现t的文档总数。
p(Ci|t否)即t不出现但属于Ci的概率,等于未出现t但属于Ci的文档总数除以未出现t的所有文档数。
1.2分类算法
常见的分类算法有,基于统计的Rocchio算法、贝叶斯算法、KNN算法、支持向量机方法,基于规则的决策树方法,和较为复杂的神经网络。这里我们介绍两种用到的分类算法:朴素贝叶斯和支持向量机。
1.2.1朴素贝叶斯
贝叶斯公式:P(C|X)=P(X|C)P(C)/P(X)
先验概率P(C)通过计算训练集中属于每一个类的训练样本所占的比例,类条件概率P(X|C)的估计—朴素贝叶斯,假设事物属性之间相互条件独立,P(X|C)=∏P(xi|ci)。
朴素贝叶斯有两用常用的模型,概率定义略有不同,如下:设某文档d=(t1,t2,…,tk),tk是该文档中出现过的单词,允许重复。
- 多项式模型:
先验概率P(c)= 类c下单词总数/整个训练样本的单词总数。
条件概率P(tk|c)=(类c下单词tk在各个文档中出现过的次数之和+1)/( 类c下单词总数+|V|)
- 伯努利模型:
先验概率P(c)= 类c下文件总数/整个训练样本的文件总数。
条件概率P(tk|c)=(类c下包含单词tk的文件数+1)/(类c下单词总数+2)
通俗点解释两种模型不同点在于:计算后验概率时,对于一个文档d,多项式模型中,只有在d中出现过的单词,才会参与后验概率计算,伯努利模型中,没有在d中出现,但是在全局单词表中出现的单词,也会参与计算,不过是作为“反例”参与的。
1.2.2 支持向量机模型SVM
SVM展开来说较为复杂,这里借助两张图帮助概念性地解释一下。对于线性可分的数据,可以用一超平面f(x)=w*x+b将这两类数据分开。如何确定这个超平面呢?从直观上而言,这个超平面应该是最适合分开两类数据的直线。而判定“最适合”的标准就是这条直线离直线两边的数据的间隔最大。
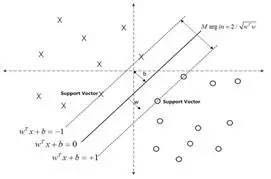
而对于线性不可分的数据,则将其映射到一个更高维的空间里,在这个空间里建立寻找一个最大间隔的超平面。怎么映射呢?这就是SVM的关键:核函数。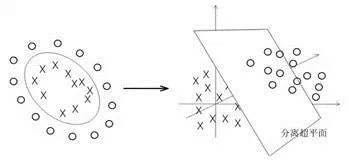
现在常用的核函数有:线性核,多项式核,径向基核,高斯核,Sigmoid核。如果想对SVM有更深入的了解,请参考《支持向量机通俗导论(理解SVM的三层境界)》一文。
二.情感分类系统实现
情感分类与主题分类除了第一章提到的挖掘信息不同外,处理的文本也大不相同。情感分类主要处理一些类似评论的文本,这类文本有以下几个特点:时新性、短文本、不规则表达、信息量大。我们在系统设计、算法选择时都会充分考虑到这些因素。情感分灰系统分为在线、离线两大流程,在线流程将用户输出的语句进行特征挖掘、情感分类、并返回结果。离线流程则负责语料下载、特征挖掘、模型训练等工作,系统结构如图3-1所示: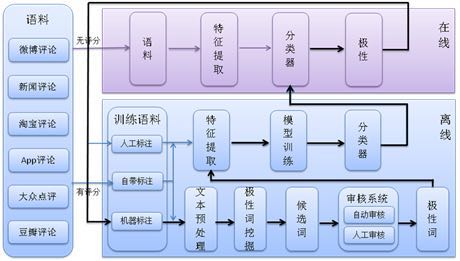
2.1 语料库建设
语料的积累是情感分类的基石,特征挖掘、模型分类都要以语料为材料。而语料又分为已标注的语料和未标注的语料,已标注的语料如对商家的评论、对产品的评论等,这些语料可通过星级确定客户的情感倾向;而未标注的语料如新闻的评论等,这些语料在使用前则需要分类模型或人工进行标注,而人工对语料的正负倾向,又是仁者见仁、智者见智,所以一定要与标注的同学有充分的沟通,使标注的语料达到基本可用的程度。
迄今,我们已对涵盖电商、新闻、影视、音乐、APP等类别的20多个站点评论进行抓取,累计已有4亿标注语料,每天新增标注语料200多万。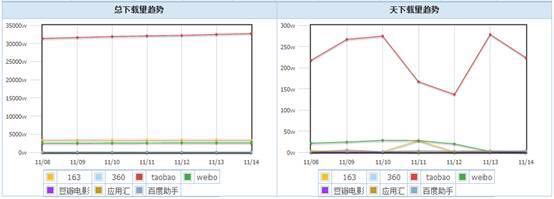
2.2极性词挖掘
情感分类中的极性词挖掘,有一种方法是“全词表法”,即将所有的词都作为极性词,这样的好处是单词被全面保留,但会导致特征维度大,计算复杂性高。我们采用的是“极性词表法”,就是要从文档中挖掘出一些能够代表正负极性的词或短语。如已知正面语料“@jjhuang:微信电话本太赞了!能免费打电话,推荐你使用哦~”,这句话中我们需要挖掘出“赞”、“推荐”这些正极性词。分为以下两步:
1)文本预处理 语料中的有太多的噪音,我们在极性词挖掘之前要先对文本预处理。文本预处理包含了分词、去噪、最佳匹配等相关技术。分词功能向大家推荐腾讯TE199的分词系统,功能强大且全面,拥有短语分词、词性标注等强大功能。去噪需要去掉文档中的无关信息如“@jjhuang”、html标签等,和一些不具有分类意义的虚词、代词如“的”、“啊”、“我”等,以起到降维的作用。最佳匹配则是为了确保提出的特征能够正确地反映正负倾向,如“逍遥法外”一词,如果提取出的是“逍遥”一词,则会被误认为是正面情感特征,而“逍遥法外”本身是一个负面情感词,这里一般可以采用最长匹配的方法。
2)极性词选择 文本预处理之后,我们要从众多词语中选出一些词作为极性词,用以训练模型。我们对之前介绍的TF-IDF方法略作变化,用以降维。因为我们训练和处理的文本都太短,DF和TF值大致相同,我们用一个TF值就可以。另外,我们也计算极性词在反例中出现的频率,如正极性词“赞”必然在正极性语料中的TF值大于在负极性语料中的TF值,如果二者的差值大于某个域值,我们就将该特征纳入极性词候选集,经过人工审核后,就可以正式作为极性词使用。
目前,我们已挖掘出12w+ 极性词,通过人工审核的有 8w+ 个,每天仍会从语料中挖掘出100+ 个极性词。
2.3极性判断
极性判断的任务是判断语料的正、负、中极性,这是一个复杂的三分类问题。为了将该问题简化,我们首先对语料做一个主客观判断,客观语料即为中性语料,主观语料再进行正、负极性的判断。这样,我们就将一个复杂三分类问题,简化成了两个二分类问题。如下: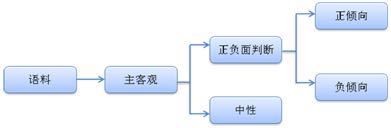
在分类器选择中,主客观判断我们使用了上节介绍的支持向量机模型。而极性判断中,我们同时使用了朴素贝叶斯和支持向量机模型。其中朴素贝叶斯使用人工审核过的极性词作特征,而支持向量机模型则使用全词表作为特征。两个模型会对输入的语料分别判断,给出正、负极性的概率,最后由决策模块给出语料的极性。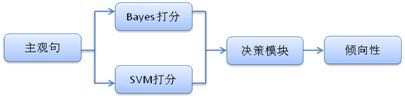
在朴素贝叶斯模型中,我们比较了多项式模型和伯努力模型的效果。伯努力模型将全语料中的单词做为反例计算,因为评测文本大多是短文本,导致反例太多。进而伯努力模型效果稍差于多项式模型,所以我们选择了多项式模型。
支持向量机模型中,我们使用的是台湾大学林智仁开发的SVM工具包LIBSVM,这是一个开源的软件包,可以解决模式识别、函数逼近和概率密度估计等机器学习基本问题,提供了线性、多项式、径向基和S形函数四种常用的核函数供选择。LIBSVM 使用的一般步骤是:
- 按照LIBSVM软件包所要求的格式准备数据集;
- 对数据进行简单的缩放操作;
- 考虑选用RBF 核函数;
- 采用交叉验证选择最佳参数C与g;
- 采用最佳参数C与g 对整个训练集进行训练获取支持向量机模型;
- 利用获取的模型进行测试与预测。
在我们的模型中,经过几次试验,选用的高斯核,自己调的参数C。文智平台当前情感分类效果:

业界效果:2014 COAE 中文倾向性分析评测
备注:
- 语料来主要源于3个领域(手机、翡翠、保险)的微博数据;
- 针对观点句进行情感判断;
- 测试集是7000篇人工标注微博评论。
- 垂直领域的情感分类
上述介绍的是我们通用的情感分类系统,面对的是通用的主观评论语料。但在一些领域中,某些非极性词也充分表达了用户的情感倾向,比如下载使用APP时,“卡死了”、“下载太慢了”就表达了用户的负面情感倾向;股票领域中,“看涨”、“牛市”表达的就是用户的正面情感倾向。所以我们要在垂直领域中,挖掘出一些特殊的表达,作为极性词给情感分类系统使用:
垂直极性词 = 通用极性词 + 领域特有极性词
该系统即为垂直领域的情感分类系统。目前,我们已对社会事件、APP、电影几个领域建立了垂直情感分类系统。领域的覆盖正在不断扩大……
2.5页面展示
情感分类系统已于线上正常运行,并为兄弟部门服务每天会对当日热门事件进行舆论分析统计,并给出主流正负面代表评论。移动端展示请观注文智公共号tencentwenzhi,pc页展示请获得权限后登录http://tdata.oa.com 查看。页面效果如下: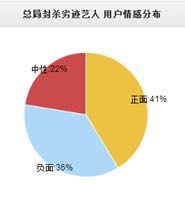
2.6 系统优化
情感分类的工作,我们还在继续。我们在现在和未来还可以做更多的工作来优化我们的情感分类系统:
- 挖掘更多的极性词(多领域)
- 尝试不同的分类器,调优现有的模型
- 句式识别:否定句,转折句,排比句等……
- 语料清洗:识别水军评论和用户评论
- 极性词扩展:采用近义词、反义词等方法,将挖掘的极性词扩展更多
三.总结:
文智平台情感分类系统基于多个领域数、亿标注语料的学习,可对众多评论数据进行倾向性分析,掌握用户舆论走向。尤其是对新闻、影视、产品等领域句子极别的评论数据,倾向性分析更为准确、有效。系统目前已上线运营,并为兄弟部门提供舆论倾向服务。系统使用简单、效果可靠,期待能为其他业务部门提供更为广泛的应用。
欢迎有需求的团队联系我们,使用腾讯文智自然语言处理。
SwiftUI 中某些环境自动更新背后的奥秘
】SwiftUI中某些环境自动更新背后的奥秘【英文标题】:TheMysterybehindautoupdateofsomeEnvironmentinSwiftUI【发布时间】:2021-03-2917:23:50【问题描述】:我可以使用环境修改器轻松更改视图级别中名为backgroundColor的自定义环境!像这样下来... 查看详情
Lime 解释器显示与分类器预测不同的预测概率 - 情感分析
...Lime来追踪模型为何决定预测这句话是(NEG、POS或NEUTRAL)背后的行为,并且在大多数情况下,lim 查看详情
第17篇textcnn
...报告了在预训练词向量之上训练的卷积神经网络(CNN)的一系列实验,用于句子级分类任务。我们表明,具有很少超参数调整和静态向量的简单CNN在多个基准测试中取得了出色的结果。通过微调学习特定于任务的向量可进一步提高... 查看详情
rk3568平台开发系列讲解(驱动基础篇)io模型的分类
@aspect注解背后的奥秘--上(代码片段)
@Aspect注解背后的奥秘--上引言aop的原始时代ProxyFactory实现思路AspectJProxyFactory的实现思路1.切面元数据解析过程2.InstantiationModelAwarePointcutAdvisorImpl获取advice3.AopUtils筛选能够应用到当前目标对象上的advisors4.AspectJProxyUtils添加一个Ex... 查看详情
论文笔记基于语义依赖和上下文矩的深度掩码记忆网络在方面级情感分类中的应用(英文题目太长)
DeepMaskMemoryNetworkwithSemanticDependencyandContextMomentforAspectLevelSentimentClassification这篇论文来自IJCAI-2019,其结果也是目前非Bert模型中已发表论文的最高水平。这个模型相较于上面那一篇要复杂很多,是一篇名副其实的IJCAI论文。... 查看详情
.net平台系列29:.netcore跨平台奥秘
...点击查看详细】参考蒋金楠老师的博客:.NETCore跨平台的奥秘[上篇]:历史的枷锁.NETCore跨平台的奥秘[中篇]:复用之殇.NETCore跨平台的奥秘[下篇]:全新的布局系列目录 【已更新最新开发文章,点击查看详细】 查看详情
bert实战:使用distilbert进行文本情感分类(代码片段)
这次根据一篇教程JayAlammar:AVisualGuidetoUsingBERTfortheFirstTime学习下如何在Pytorch框架下使用BERT。主要参考了中文翻译版本教程提供了可用的代码,可以在colab或者github获取。1.huggingface/transformersTransformers提供了数千个预训练的模型... 查看详情
文本情感分类:传统模型
基于情感词典的文本情感分类传统的基于情感词典的文本情感分类,是对人的记忆和判断思维的最简单的模拟,如上图。我们首先通过学习来记忆一些基本词汇,如否定词语有“不”,积极词语有“喜欢”、“爱”,消极词语有... 查看详情
社交媒体情感分类数据集
】社交媒体情感分类数据集【英文标题】:Datasetforemotionclassificationonsocialmedia【发布时间】:2012-10-2917:54:54【问题描述】:我想对文本进行情感分类(来自社交媒体的帖子,例如推文、Facebook墙贴、youtubecmets等......)。虽然我找... 查看详情
@aspect注解背后的奥秘--下(代码片段)
@Aspect注解背后的奥秘--下前言手动化进行到自动化靠的是什么自动代理创建器如何搜寻并对增强器集合进行过滤1.寻找所有可用的候选advisor1.1isEligibleBean两种分支情况2.过滤候选增强器3.扩展增强器4.对增强器进行排序搜寻所有... 查看详情
基于朴素贝叶斯算法的情感分类(代码片段)
环境win8,python3.7,jupyternotebook正文什么是情感分析?(以下引用百度百科定义)情感分析(Sentimentanalysis),又称倾向性分析,意见抽取(Opinionextraction),意见挖掘(Opinionmining),情感挖掘(Sentimentmining),主观分析(Subjectivityanalysi... 查看详情
情感分类
按情感价值正负可以分为正向情感与负向情感,正向情感是人对正向价值的增加或负向价值的减少所产生的情感,如愉快、信任、感激、庆幸等;而负向情感是人对正向价值的减少或负向价值的增加所产生的情感,如痛苦、鄙视... 查看详情
使用机器学习的情感分析分类器
】使用机器学习的情感分析分类器【英文标题】:SentimentAnalysisclassifierusingMachineLearning【发布时间】:2016-04-3020:08:14【问题描述】:我们如何为情绪分析制作一个有效的分类器,因为为此我们需要在庞大的数据集上训练我们的分... 查看详情
metaverse系列一元宇宙的奥秘
你有没有想过逃离闷热的会议室,瞬间移动到马尔代夫的沙滩上开会?开完会,纵身跳入大海和美人鱼捉迷藏。然后一个鲤鱼打挺直冲云霄,进入天宫一号开展科学研究,发现微重力环境下韭菜的长势喜人,而且在特定光照条件... 查看详情
中文情感分类单标签
...lp/practice/sentiment.md背景介绍这次的任务是中文的一个评论情感去向分类:每一行一共有三个部分,第一个是索引,无所谓;第二个是评论具体内容;第三个是标签,由0,1,2组成,1代表很好ÿ... 查看详情
文本分类(代码片段)
文本情感分类文本分类是自然语言处理的一个常见任务,它把一段不定长的文本序列变换为文本的类别。本节关注它的一个子问题:使用文本情感分类来分析文本作者的情绪。这个问题也叫情感分析,并有着广泛的应用。同搜索... 查看详情
第二天学习进度--文本情感分类(代码片段)
...文本进行分类,但是对于相对具有深层含义的内容,例如情感的积极,情感的消息这方面的分类来说,就显得有些乏力的。根据昨天构建的文本分类模型,在训练完消极和积极的评论各1w个之后,对于在淘宝某个商品新获取的评... 查看详情