关键词:
Hive架构前面我们讲解了hive是什么,下面我们接着来看一下hive的架构。
hive在hadoop生态系统的位置
在讲解hive的架构前,我们先看一下hadoop的生态系统图,看一下hive到底在hadoop生态系统中占据着什么位置。
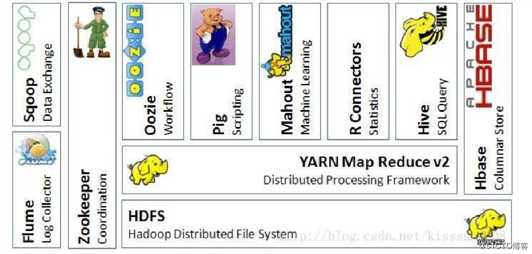
这张图上所有的框架我们在后续都会给大家介绍。
通过上图,我们可以看到hive的下面是yarn、MapReduce、HDFS,这和我们对hive的定义是一样的。在hive的右侧是Hbase,这就说明hive可以和HBase进行集成。可以看到hive在整个hadoop生态系统中还是占据着比较重要的位置的。
hive架构
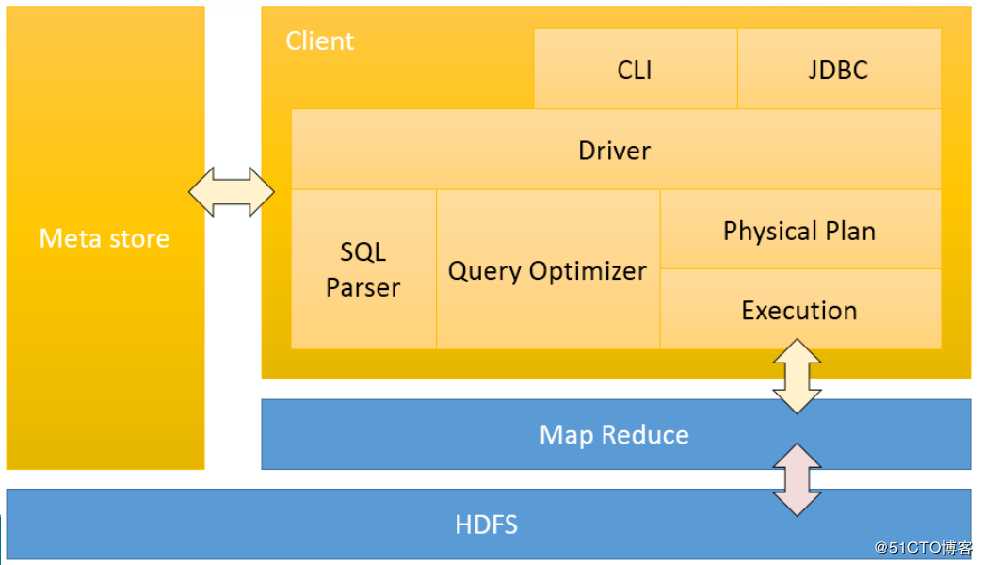
我们先看这张图的蓝色部分,我们可以看到这就是MapReduce和HDFS,这一部分我们就比较熟悉了。
在回想下hive的本质,就是讲HQL语句转换成MapReduce程序进行在yarn上执行。那么现在底层的MapReduce和HDFS我们清楚了。那用户是如何提交HQL语句到hive的呢?
这就是上图中的右上部分,用户可以通过cli(命令行)或者java调用jdbc的方式通过Hive的驱动将HQL提交给Hive。
hive在接收到HQL语句时要进行以下四部的处理:
- 将HQL语句进行解析
- 对已经解析的进行优化处理。
- 根据优化的结果生成一个物理的计划。
- 将物理的计划提交给yarn进行执行。
通过以上这几个步骤,hive就完成了他的工作,接受用户提交的HQL语句,将其转换成MapReduce程序进行执行。
我们看到上图的左侧还有个MetaStore,这个是什么呢?这个就是hive的元数据。我们来解释下什么是元数据。我们知道hive是讲一定的日志数据转换成数据表的形式,那是不是需要记录表的名字与存储在HDFS文件系统上文件的对应关系,是不是需要知道每一个列数据的名称。这些就组成了hive的元数据。hive通过查找元数据才能清楚的知道要去查找那个文件等等。
元数据默认存储在自带的derby数据库中,推荐使用MySQL存储Metestore。
hive的优势
- 操作接口采用类SQL语法,提供快速开发的能及(简单、容易上手)
- 避免了去写MapReduce,减少开发人员的学习成本
- 统一的元数据管理,可与impala/spark等共享数据
- 易扩展(HDFS+MapReduce),可以扩展集群规模;支持自定义函数
使用场景
- 数据的离线处理:比如,日志分析,海量结构化数据离线分析
- Hive的执行延迟比较高:hive常用于数据分析的,对实时性要求不高的场合
- Hive优势在于处理大数据,对于处理小数据没有优势,因为Hive的执行延迟比较高
hive之hive架构
...nbsp; Hive架构图主要分为以下几个部分:用户接口,包括命令行CLI,Client,Web界面WUI,JDBC/ODBC接口等中间件:包括thrift接口和JDBC/ODBC的服务端,用于整合Hive和其他程序。元数据metad... 查看详情
hive的设计与架构(代码片段)
本文包含Hive的设计与架构的详细信息,具体内容如下:Hive架构Hive数据模型元存储Motivation元数据对象Hive架构图中展示了Hive的主要组成部分,以及与Hadoop的交互,如图所述,Hive的主要组件有:UI–提供给用... 查看详情
Hive 外部表架构重新连接
】Hive外部表架构重新连接【英文标题】:HiveExternalTableSchemaReconnection【发布时间】:2019-02-1207:42:08【问题描述】:假设我通过删除表删除了现有hive外部表的架构,数据仍然存在于位置。然后,我在现有数据的相同位置重新创建... 查看详情
hive架构
Hive架构前面我们讲解了hive是什么,下面我们接着来看一下hive的架构。hive在hadoop生态系统的位置在讲解hive的架构前,我们先看一下hadoop的生态系统图,看一下hive到底在hadoop生态系统中占据着什么位置。这张图上所有的框架我们... 查看详情
hive基础及系统架构
1、hive是什么 hive是建立在hadoop上的数据仓库,提供数据的提取、转化和加载。2、hive的数据存储 1】hive的数据存储基于hdfs 2】存储结构主要包括:数据库、文件、表、索引、视图 3】hive默认可以直接加载文本文件... 查看详情
更改 Hive 表的架构
】更改Hive表的架构【英文标题】:AltertheschemaofHivetable【发布时间】:2014-02-2006:30:28【问题描述】:我想更改在Hive中创建的映射到HBase字段的表。最近我在HBase中添加了更多列,因此也希望将这些字段添加到Hive中。我使用的创作... 查看详情
hive架构
一、Hive是什么,作用是什么? 可以这么简单得理解,Hive是一个工具。它得作用是查询hdfs文件系统上得海量数据,方式是通过HQL语句查询(类似sql)。或许你又有疑问了,明明可以在java程序里直接访问HDFS的数据了啊,为什... 查看详情
[hive]-架构篇
1.Hive简述 1.1Hive是什么 Hive是数据仓库.它是构建在Hadoop之上的,通过解析QL(HiveSQL),转换成MR任务(Tez,Spark......)去提交执行. 1.2Hive的优缺点 优点: 可以直接访问HDFS,或者其它的标准分布式文件系统(s... 查看详情
hive的功能和架构(代码片段)
...ve是Hadoop的数据仓库,从【数据存储和分析】方面理解Hive架构,分为三个部门来理解,画图理解1.Hive能做什么,与mapreduce相比优势在哪里(相对于开发)1.1.hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一... 查看详情
hive架构
UI: 用于提交查询的客户端,hive自带有CLI(commandline),现在推荐使用beelineDRIVER: 1.用于接收客户端提交的SQL,并实现了session控制 查看详情
hive的体系架构及安装
1,什么是Hive? Hive是能够用类SQL的方式操作HDFS里面数据一个数据仓库的框架,这个类SQL我们称之为HQL(HiveQueryLanguage)2,什么是数据仓库? 存放数据的地方3,Hive的特征 海量数据的存储 海量数据的查询 ... 查看详情
外部覆盖后 Spark 和 Hive 表架构不同步
】外部覆盖后Spark和Hive表架构不同步【英文标题】:SparkandHivetableschemaoutofsyncafterexternaloverwrite【发布时间】:2018-03-0920:10:40【问题描述】:在使用Spark2.1.0和Hive2.1.1的Mapr集群上,Hive表的架构在Spark和Hive之间不同步时遇到问题。我... 查看详情
hive基础架构
Hive由Facebook开源用于解决海量结构化日志的数据统计:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射成一张表,并提供类SQL查询功能;构建在Hadoop之上的数据仓库: *使用HQL作为查询接口 *处理的数据... 查看详情
hive的架构和工作流程
架构 1.hive是数据仓库,在hadoop基础上处理结构化数据;它驻留在hadoop之上,用户对数据的统计,查询和简单的分析操作。 2.hive不是 a.关系型数据库 b.OLTP c.实时查询和行级更新操作 3.hive特点... 查看详情
Hortonworks Hive 仓库连接器和架构更新
】HortonworksHive仓库连接器和架构更新【英文标题】:HortonworksHiveWarehouseConnectorandschemaupdates【发布时间】:2019-02-2611:04:47【问题描述】:似乎直到v.1.0.0的HortonworksHiveWarehouseConnector不支持架构更新。我尝试使用hive.createTable(tableName).... 查看详情
hive架构倾斜优化sql及常见问题
Hive架构hive架构如图所示,client跟driver交互,通过parser、planner、optimizer,最后转为mapreduce运行,具体步骤如下driver输入一条sql,会由parser转为抽象语法树AST,这个是没有任务元数据信息的语法树;语法分析器再把AST转为一个一个... 查看详情
hive的配置|架构原理(代码片段)
...分析数据底层的实现是MapReduce3)执行程序运行在Yarn上Hive架构原理 Hive安装及配置(1)把apache-hive-1.2.1-bin.tar.gz上传到linux的/opt/software目录下(2)解压apache-hive-1.2.1-bin.tar.gz到/opt/module/目录下面 [[email protected]software]$tar-... 查看详情
apachehive入门:模拟实现hive功能hive架构组件
一、ApacheHive概述什么是HiveApacheHive是一款建立在Hadoop之上的开源数据仓库系统,可以将存储在Hadoop文件中的结构化、半结构化数据文件映射为一张数据库表, 基于表提供了一种类似SQL的查询模型, 称为Hive查询语言(... 查看详情