关键词:
在之前的redis源码阅读三-终于把主线任务执行搞明白了和redis源码阅读五-为什么大量过期key会阻塞redis?梳理了redis的整体处理流程和redis的定期清理。都没有说到redis的过期策略。这次我来探究一下。
我们都知道redis的缓存淘汰策略有以下几种:
-
noeviction 无过期策略,内存满了就直接异常
-
volatile-lru 对有过期时间的key进行lru淘汰(越长时间没有被访问,越容易被淘汰)
-
allkeys-lru 对全局的key按LRU进行淘汰(越长时间没有被访问,越容易被淘汰)
-
volatile-lfu 对有过期时间的key进行lfu淘汰(经常不被访问的,越容易被淘汰)
-
allkeys-lfu 对全局的key进行lfu淘汰(经常不被访问的,越容易被淘汰)
-
volatile-random 对有过期时间的key进行随机淘汰
-
allkeys-random 对有所有的key进行随机淘汰
-
volatile-ttl 按时间进行过期淘汰
淘汰策略触发入口
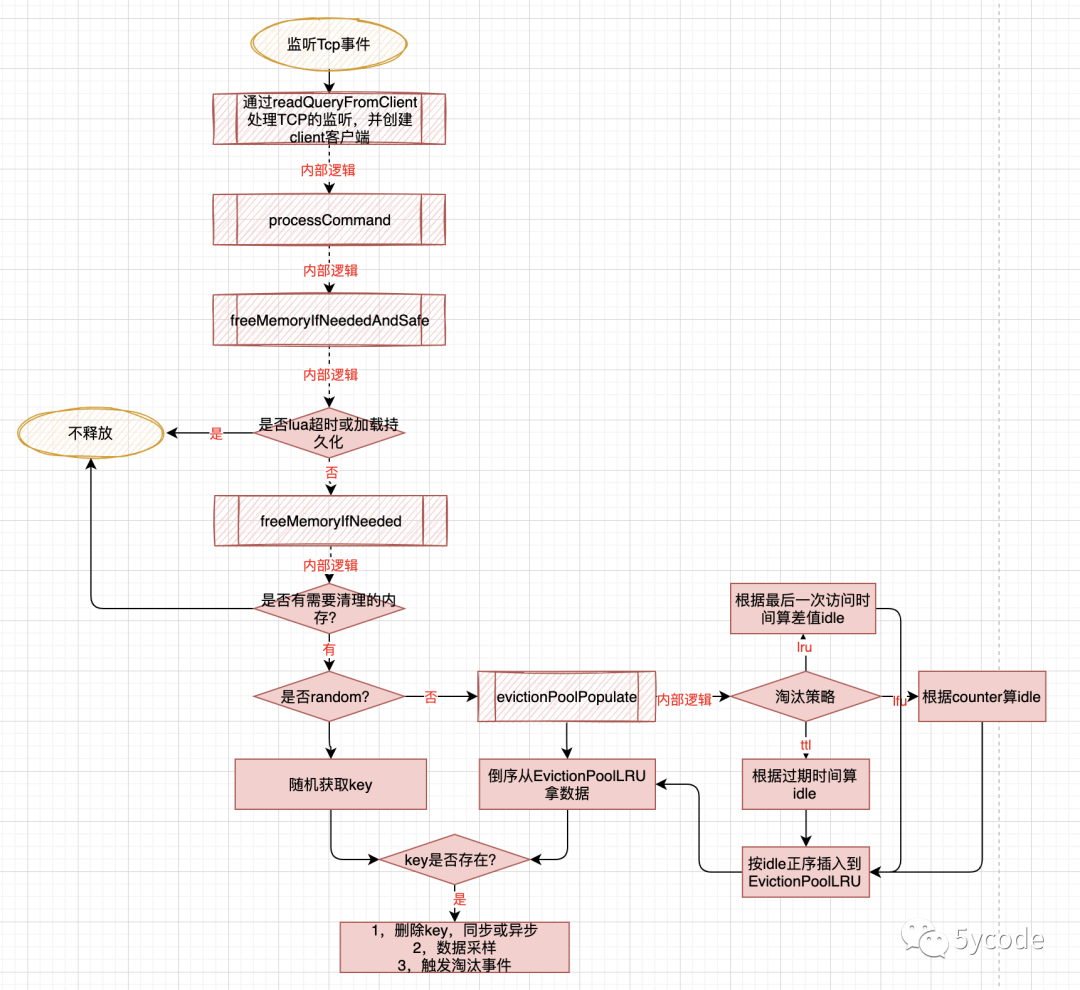
在redis源码阅读三-终于把主线任务执行搞明白了中,分析了redis通过acceptTcpHandler绑定readQueryFromClient,对新进来的请求进行监听。最终定位到了processCommand函数。当时只说了核心的方法call(c,CMD_CALL_FULL);在这里还有一处逻辑 freeMemoryIfNeededAndSafe(),这里是对内存淘汰的处理,代码如下:
int processCommand(client *c)
//从server.commands字典里查询命令执行命令的映射,c->argv[0]为命令名称
c->cmd = c->lastcmd = lookupCommand(c->argv[0]->ptr);
//找不到命令就未知命令异常,参数不对,也异常
//其他一堆逻辑判断
//设置了最大内存,并且lua脚本执行没有超时
if (server.maxmemory && !server.lua_timedout)
//如果有必要的话回收内存
int out_of_memory = freeMemoryIfNeededAndSafe() == C_ERR;
/**
* @brief 执行命令
* 开始了事务(CLIENT_MULTI)直接放入Multi队列
*
*/
if (c->flags & CLIENT_MULTI &&
c->cmd->proc != execCommand && c->cmd->proc != discardCommand &&
c->cmd->proc != multiCommand && c->cmd->proc != watchCommand)
queueMultiCommand(c);
addReply(c,shared.queued);
else
//执行命令回调
call(c,CMD_CALL_FULL);
//
c->woff = server.master_repl_offset;
if (listLength(server.ready_keys))
handleClientsBlockedOnKeys();
淘汰策略处理主流程
在这个 freeMemoryIfNeededAndSafe() 函数里通过redis的具体淘汰策略来淘汰key。具体流程如下:
-
lua脚本超时或正在加载持久化不进行(所以会超最大限制)
-
对从库逻辑的判读,从库不进行释放内存处理
-
计算需要释放的空间mem_tofree,如果没有需要释放的就不处理(这里会把主从复制的缓冲区减掉)
-
noeviction 淘汰策略特殊处理
-
如果已用的内存超了,随机采样key,进行释放,直到释放的空间小于要释放的内存,包含两种策略
-
LRU、LFU、TTL 这三种是一套处理,根据类型采样不同的源,然后计算idle,值越大优先清理
-
random 就随机采样,然后删除
在evict.c中
int freeMemoryIfNeededAndSafe(void)
//lua脚本超时或正在加载持久化,直接返回
if (server.lua_timedout || server.loading) return C_OK;
return freeMemoryIfNeeded();
/**
* @brief 如果有必要释放内存
* 1,从库不处理
* 2,计算需要释放的空间mem_tofree,如果没有需要释放的就不处理(这里会把主从复制的缓冲区减掉)
* 3,noeviction 淘汰策略直接返回
* 4,如果已用的内存超了,随机采样key,进行释放,直到释放的空间小于要释放的内存
* 4.1 LRU、LFU、TTL 这三种策略是一种处理
* 4.2 RANDOM 策略处理
* 5,根据采样到的key进行删除
* @return int
*/
int freeMemoryIfNeeded(void)
//从库不用处理
if (server.masterhost && server.repl_slave_ignore_maxmemory) return C_OK;
size_t mem_reported, mem_tofree, mem_freed;
mstime_t latency, eviction_latency;
long long delta;
//从库数量
int slaves = listLength(server.slaves);
if (clientsArePaused()) return C_OK;
//计算需要释放的空间mem_tofree,如果没有需要释放的就不处理
if (getMaxmemoryState(&mem_reported,NULL,&mem_tofree,NULL) == C_OK)
return C_OK;
mem_freed = 0;
if (server.maxmemory_policy == MAXMEMORY_NO_EVICTION)
goto cant_free; /* We need to free memory, but policy forbids. */
latencyStartMonitor(latency);
while (mem_freed < mem_tofree)
int j, k, i, keys_freed = 0;
static unsigned int next_db = 0;
sds bestkey = NULL;
int bestdbid;
redisDb *db;
dict *dict;
dictEntry *de;
//不同的淘汰策略执行不同的逻辑
if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) ||
server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL)
//默认16的数组,在initServer里,调用 evictionPoolAlloc 初始化数组
struct evictionPoolEntry *pool = EvictionPoolLRU;
while(bestkey == NULL)
unsigned long total_keys = 0, keys;
//遍历db
for (i = 0; i < server.dbnum; i++)
db = server.db+i;
//根据不同的策略固定采样源是从全全局hash表里拿,还是从expires哈希表里拿
dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ? db->dict : db->expires;
if ((keys = dictSize(dict)) != 0)
//采集的信息放入数组,idle越大都在左边
evictionPoolPopulate(i, dict, db->dict, pool);
total_keys += keys;
if (!total_keys) break; /* No keys to evict. */
/**
* 倒序处理
*/
for (k = EVPOOL_SIZE-1; k >= 0; k--)
if (pool[k].key == NULL) continue;
bestdbid = pool[k].dbid;
//根据不同的策略是从全全局hash表里拿,还是从expires哈希表里拿到键值dictEntry
if (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS)
de = dictFind(server.db[pool[k].dbid].dict,pool[k].key);
else
de = dictFind(server.db[pool[k].dbid].expires,pool[k].key);
/* Remove the entry from the pool. */
if (pool[k].key != pool[k].cached)
sdsfree(pool[k].key);
pool[k].key = NULL;
pool[k].idle = 0;
if (de)
bestkey = dictGetKey(de);
break;
else
/* Ghost... Iterate again. */
/* random 策略处理 */
else if (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM ||
server.maxmemory_policy == MAXMEMORY_VOLATILE_RANDOM)
for (i = 0; i < server.dbnum; i++)
//防止溢出,如果直接取模求db
j = (++next_db) % server.dbnum;
//数组的名是首地址
db = server.db+j;
//删除的源是全局还是expires
dict = (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM) ?db->dict : db->expires;
if (dictSize(dict) != 0)
//随机获取key
de = dictGetRandomKey(dict);
bestkey = dictGetKey(de);
bestdbid = j;
break;
//删除选中的key
if (bestkey)
//释放空间
db = server.db+bestdbid;
robj *keyobj = createStringObject(bestkey,sdslen(bestkey));
propagateExpire(db,keyobj,server.lazyfree_lazy_eviction);
delta = (long long) zmalloc_used_memory();
latencyStartMonitor(eviction_latency);
//删除方式
if (server.lazyfree_lazy_eviction)
dbAsyncDelete(db,keyobj);
else
dbSyncDelete(db,keyobj);
latencyEndMonitor(eviction_latency);
latencyAddSampleIfNeeded("eviction-del",eviction_latency);
latencyRemoveNestedEvent(latency,eviction_latency);
delta -= (long long) zmalloc_used_memory();
mem_freed += delta;
server.stat_evictedkeys++;
//触发淘汰事件,(之前是过期事件)
notifyKeyspaceEvent(NOTIFY_EVICTED, "evicted", keyobj, db->id);
decrRefCount(keyobj);
keys_freed++;
//主从同步
if (slaves) flushSlavesOutputBuffers();
if (server.lazyfree_lazy_eviction && !(keys_freed % 16))
if (getMaxmemoryState(NULL,NULL,NULL,NULL) == C_OK)
/* Let's satisfy our stop condition. */
mem_freed = mem_tofree;
if (!keys_freed)
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("eviction-cycle",latency);
goto cant_free; /* nothing to free... */
latencyEndMonitor(latency);
latencyAddSampleIfNeeded("eviction-cycle",latency);
return C_OK;
cant_free:
while(bioPendingJobsOfType(BIO_LAZY_FREE))
if (((mem_reported - zmalloc_used_memory()) + mem_freed) >= mem_tofree)
break;
usleep(1000);
return C_ERR;
根据不同的淘汰策略采样(核心)
对于LRU/LFU/TTL evictionPoolPopulate 函数是核心,核心思想就是随机采样后,计算采样数据的idle值
-
对LRU,idle是现在到上次访问的时间差,操作val对象的robj,这个值是记录在robj中的lru里
-
对LFU,idle是255-counter,counter是根据访问计算出来的衰减值,操作val对象的robj
-
对TTL, idle是db->expires里存储的dictEntry,val是到期日期
/**
* @brief 将待淘汰的数据填充到pool里,最终从小到大排序
* @param dbid 数据的id
* @param sampledict 采样来源,可能是db->dict也可能是 db->expires
* @param keydict 全局hash表 db->dict
* @param pool 待淘汰的候选键集合
*/
void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool)
int j, k, count;
//定义dictEntry的指针数组,默认5
dictEntry *samples[server.maxmemory_samples];
/**
* @brief 随机采样
* 1,随机定位到hash表的索引
* 2,采样,如果采样为空,索引+1;
* 3,如果连续maxmemory_samples次数的采样都为空,再重新计算hash的索引
* 4,找到对应的hash桶,连续取maxmemory_samples个key,返回
*/
count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples);
for (j = 0; j < count; j++)
unsigned long long idle;
sds key;
robj *o;
dictEntry *de;
de = samples[j];
key = dictGetKey(de);
if (server.maxmemory_policy != MAXMEMORY_VOLATILE_TTL)
if (sampledict != keydict) de = dictFind(keydict, key);
o = dictGetVal(de);
//LRU是值越大,越容易被清理
if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU)
//返回最后一次请求到现在的时间差
idle = estimateObjectIdleTime(o);
else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU)
/**
* @brief LFUDecrAndReturn 返回的是LFU的counter,时间越长不访问,counter越小,最小为0
* LFU访问频次越高counter越大(虽然会衰减),用最大值255-counter越大,说明访问的频率越低
*/
idle = 255-LFUDecrAndReturn(o);
else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL)
//如果是TTL,一定是从db->expires采样的,de里面存储的是到期时间
idle = ULLONG_MAX - (long)dictGetVal(de);
else
serverPanic("Unknown eviction policy in evictionPoolPopulate()");
k = 0;
/**
* idle越大越容易被清理,当pool中的idle小于采样的数据时,会进行替换
* 第一个进来6 0的位置没值,触发逻辑2,直接0的位置存放 idle=6对应的key
* 然后idle 5,2 和8,7,3 过来
* 过来5 话 k=0 这个时候0的位置上有key了,触发逻辑3,整体会把0位置向右移动,然后插入5 最后是:5,6
* 2 的话k=0,同5的步骤,触发逻辑3 最后是:2,5,6
* 8 的话 k=3,且k=3的位置没有值,触发逻辑2,直接放入3的位置, 最后是:2,5,6,8
* 7 的话 k=3,k=3的位置已有值,触发逻辑3,整体把3以后的右移,然后插入7,最后是 2,5,6,7,8
* 假设只有5个
* 3 过来,k=1,最后一位已满,触发逻辑4,k--最后为0,取出原来0位置的cached,把1位置的拷贝到0位置,然后,2对应的key给cached和key
* 2 过来,k=0,触发逻辑1然后continue
*/
while (k < EVPOOL_SIZE &&
pool[k].key &&
pool[k].idle < idle) k++;
//逻辑1,k=0,且pool满了就不再处理,
if (k == 0 && pool[EVPOOL_SIZE-1].key != NULL)
/* Can't insert if the element is < the worst element we have
* and there are no empty buckets. */
continue;
//逻辑2
else if (k < EVPOOL_SIZE && pool[k].key == NULL)
//正常插入逻辑
else
//逻辑3,最后一个为空,,就把k以后的数据都往后挪移,给刚来的数据挪位
if (pool[EVPOOL_SIZE-1].key == NULL)
sds cached = pool[EVPOOL_SIZE-1].cached;
/**
* 当内存发生局部重叠的时候,memmove保证拷贝的结果是正确的,memcpy不保证拷贝的结果的正确。
* 从 pool+k拷贝到 pool+k+1,长度是sizeof(pool[0])*(EVPOOL_SIZE-k-1)
*/
memmove(pool+k+1,pool+k,
sizeof(pool[0])*(EVPOOL_SIZE-k-1));
//把最后的cached放到当前
pool[k].cached = cached;
else //逻辑4
/* No free space on right? Insert at k-1 */
k--;
sds cached = pool[0].cached; /* Save SDS before overwriting. */
if (pool[0].key != pool[0].cached) sdsfree(pool[0].key);
memmove(pool,pool+1,sizeof(pool[0])*k);
pool[k].cached = cached;
int klen = sdslen(key);
if (klen > EVPOOL_CACHED_SDS_SIZE)
//key比较大,cached是最后的或首位的,key和cache可能不一致
pool[k].key = sdsdup(key);
else
//直接把key拷贝到k的位置
memcpy(pool[k].cached,key,klen+1);
sdssetlen(pool[k].cached,klen);
//key和cache一致
pool[k].key = pool[k].cached;
pool[k].idle = idle;
pool[k].dbid = dbid;
在这里,我们要关注几个函数estimateObjectIdleTime和LFUDecrAndReturn
-
LRU_CLOCK 是缓存的一个时间戳,在定期任务里会更新
-
会根据当前的lru时钟获取对应的差值
-
LFU会从lru字段里拆出时间和counter
-
counter计算的很巧妙,最大255,你一直访问我不衰减,一旦你超过1分钟不访问,我就给你衰减1(所以新添加的key,因为counter默认是5,可以防止被直接干掉)
/**
* @brief 返回最后一次请求到现在的时间差
*
* @param o
* @return unsigned long long
*/
unsigned long long estimateObjectIdleTime(robj *o)
//获取当前的lru时钟
unsigned long long lruclock = LRU_CLOCK();
//计算差值
if (lruclock >= o->lru)
return (lruclock - o->lru) * LRU_CLOCK_RESOLUTION;
else
//这个是又重新进入了一个新的周期(如果跨越了多个周期呢?没什么意义,一个周期200天了)
return (lruclock + (LRU_CLOCK_MAX - o->lru)) * LRU_CLOCK_RESOLUTION;
/**
* @brief LFU计数衰减,最终衰减到0
* @param o
* @return unsigned long 0~255
*/
unsigned long LFUDecrAndReturn(robj *o)
//获取lru中的高16位的值,存储的是分钟级的时间
unsigned long ldt = o->lru >> 8;
// 通过&获取lru的counter,最大
unsigned long counter = o->lru & 255;
/**
* 配置衰减时间的情况下
* server.lfu_decay_time 计数衰减,默认为1
* num_periods = 上次访问时间/1
*/
unsigned long num_periods = server.lfu_decay_time ? LFUTimeElapsed(ldt) / server.lfu_decay_time : 0;
/**
* 在频繁访问的情况下num_periods=0 (不超过1分钟)不会衰减
* 超过1分钟没访问就减1,超过n分钟没访问就衰减n,最终衰减到0
*/
if (num_periods)
counter = (num_periods > counter) ? 0 : counter - num_periods;
return counter;
typedef struct redisObject
//robj存储的对象类型
unsigned type:4; //4位
// 编码
unsigned encoding:4; //4位
/**
* @brief 24位
* LRU的策略下:lru存储的是 秒级时间戳的低24位,约194天会溢出
* LFU的策略下:24位拆为两块,高16位(最大值65535)低8位(最大值255)
* 高16存储的是 存储的是分钟级&最大存储位的值,要溢出的话,需要65535%60%24 约 45天溢出
* 低8位存储的是近似统计位
*/
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits access time). */
//引用次数,当为0的时候可以释放就,c语言没有垃圾回收的机制,通过这个可以释放空间
int refcount; //4字节
void *ptr; // 8字节
robj;//一个robj 占16字节
看到这里,和我最开始理解的lru和lfu有很大的出入,之前我一直以为是全局排,最长时间的一定会被先释放掉,最不经常访问的也是先释放。直到看到这块的源码。
-
redis的淘汰策略都是随机采样,默认采样5个通过.maxmemory_samples配置,所以一切都有随机性
-
在LRU策略模式下,通过计算时间差值来确定idle
-
在LFU策略下,通过衰减计算counter,然后用255-counter,计算出idle
-
在TTL的策略下,通过ULLONG_MAX-过期时间戳来计算出idle
-
最终按idle从小达到排序(这个算法也蛮有意思)
上一个流程处理的逻辑图
LRU与LFU的设置与更新
直接看源码吧
#创建的时候设置lru
/**
* @brief 根据类型创建一个redisObject
*
* @param type
* @param ptr
* @return robj*
*/
robj *createObject(int type, void *ptr)
//申请redisOject的空间
robj *o = zmalloc(sizeof(*o));
//赋值
o->type = type;
//默认raw编码
o->encoding = OBJ_ENCODING_RAW;
o->ptr = ptr;
//默认引用一次
o->refcount = 1;
/**
* 如果是LFU的淘汰策略,设置高16位为分钟级的时间戳,设置低8位为LFU的计数值,默认值为5
* 为了解决数据还没有预热就被冲掉的问题
*/
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU)
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
else
//LRU,就赋值为LRU时钟
o->lru = LRU_CLOCK();
return o;
# 只要到key的操作都会调用lookupKey
/**
* @brief 根据key 从全局hash表中查询
*
* @param db
* @param key key的robj对象
* @param flags
* @return robj*
*/
robj *lookupKey(redisDb *db, robj *key, int flags)
dictEntry *de = dictFind(db->dict,key->ptr);
if (de)
robj *val = dictGetVal(de);
if (server.rdb_child_pid == -1 &&
server.aof_child_pid == -1 &&
!(flags & LOOKUP_NOTOUCH))
//跟新LFU
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU)
updateLFU(val);
else
//更新LRU的时钟
val->lru = LRU_CLOCK();
return val;
else
return NULL;
/**
* @brief 更新LFU高16位的时钟和后8位记录的数
*
* @param val
*/
void updateLFU(robj *val)
unsigned long counter = LFUDecrAndReturn(val);
counter = LFULogIncr(counter);
val->lru = (LFUGetTimeInMinutes()<<8) | counter;
**
* @brief 更新LRU的后8位,也就是LFU的counter
* LFU 使用近似计数法,counter越大
*
* @param counter
* @return uint8_t
*/
uint8_t LFULogIncr(uint8_t counter)
if (counter == 255) return 255;
/**
* @brief rand()随机生成一个0~RAND_MAX 的随机数
* r的范围是0~1
*/
double r = (double)rand()/RAND_MAX;
//
double baseval = counter - LFU_INIT_VAL;
if (baseval < 0) baseval = 0;
/**
* server.lfu_log_factor 默认为10
* baseval 越大 p的值就越小
*/
double p = 1.0/(baseval*server.lfu_log_factor+1);
/**
* r是随机生成的0~1
* counter 是以5为起始点
* baseval=0 时: p的值为1 r的在1以下的概率为100%
* baseval=1 时: p的值为0.0909 r的在0.09以下的概率只有约9% 10次counter+1
* baseval=2 时: p的值为0.0476 r的在0.0476以下的概率只有约4.8% 20次counter+1
* baseval=3 时: p的值为0.0322 r的在0.0322以下的概率只有约3.2% 30次counter+1
* baseval=4 时: p的值为0.0244 r的在0.0244以下的概率只有约2.4% 40次counter+1
* baseval=5 时: p的值约0.0196 r的在0.0196 以下的概率只有约2% 50次counter+1
* baseval=10 时:p的值约0.0099 r的在0.0099 以下的概率只有约1% 100次才可能加1次
* baseval=100时:p的值约0.000999 r的在0.000999 以下的概率只有约0.1% 1000次才可能加1
* baseval=200时:p的值约0.0005 r的在0.0005 以下的概率只有约0.05% 2000次才可能加1
* 想达到100的baseval总次数为(10+20+30+40+...+1000)=49*1000+500 约 5万次
* 想达到200的baseval总次数为 (10+20+30+40+...+2000) = 99*2000+1000 约20万次
*/
if (r < p) counter++;
return counter;
/**
* @brief 获取当前时间(分钟级)只取低16位
*
* @return unsigned long
*/
unsigned long LFUGetTimeInMinutes(void)
/**
* server.unixtime/60 获取分钟
* 分钟再&65535,45天溢出
*/
return (server.unixtime/60) & 65535;
LFU通过近似算法解决了以下几个问题:
-
解决了热点数据被刷上去,然后下不来(想达到255,得几十万次的访问,想从255到0,只需要255分钟也就是4个小时多);
-
通过设置初始值5,防止新加入的高频数据在没有积累优势的时候,被淘汰;
-
通过255,只需要1字节8位解决了访问量过高,数值过大占用过多的内存空间
其他的优化手段也不少,比如定期LRU时钟,是一个全局变量,定期刷新,虽然堵塞会有一定的延迟,但这个可以忽略不计;
至此,我们一共了解了redis的三种触发删除的机制
-
惰性删除(健过期的情况)
-
定期清除(健过期的情况)
-
内存淘汰 (执行命令前,发现内存空间不够的情况)
注释代码地址:https://github.com/yxkong/redis/tree/5.0
redis源码阅读系列:
redis源码阅读四-我把redis6里的io多线程执行流程梳理明白了
redis中的lru淘汰策略分析(代码片段)
Redis作为缓存使用时,一些场景下要考虑内存的空间消耗问题。Redis会删除过期键以释放空间,过期键的删除策略有两种:惰性删除:每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键;如果没有... 查看详情
你说,redis如何实现键值自动清理?(代码片段)
...存服务器会配置比较高的内存资源,但如果对于Redis中的缓存数据我们不管不顾,内存资源总有耗尽的时候,这时缓存服务器就无法再对外提供服务了。我们要用有限的服务器资源支撑更多的业务服务,就必须要... 查看详情
聊聊redis内存淘汰策略(代码片段)
文章首发于公众号“蘑菇睡不着”前情回顾《源码级别了解Redis持久化》《聊聊Redis过期键删除策略》《Redis数据结构详解》《超详细Redis五种数据结构底层实现》这一期咱们一起来看看Redis的内存淘汰策略~为什么要有内存淘汰机... 查看详情
redis的缓存淘汰策略lru与lfu
...期,如果过期就直接删除,如果删除后还有超过25%的集合中的键已经过期,那么继续检测过期集合中的20个随机键进行删除。这样可以保证过期键最大只占所有设置了过期时间键的25%。在Java中LRU的实现方式是使用HashMap结合双向... 查看详情
redis——内存淘汰策略
一、缓存耗尽的原因1、每台机器的内存是一定的2、key未设置过期时间key不设置过期时间则在内存中一直存在,直到我们明确删除它。3、过度或不合理的持久化无论RDB快照或者AOF日志,都会在内存和磁盘中反复操作,需要一定的... 查看详情
redis淘汰策略与过期策略及其应用场景
...策略Redis的过期策略那么我们应如何合理的设置过期时间缓存穿透、缓存击穿、缓存雪崩有什么区别,该如何解决?缓存穿透:问题描述:解决方案:缓存击穿:问题描述:解决方案:缓存雪崩... 查看详情
redis淘汰策略与过期策略及其应用场景
...策略Redis的过期策略那么我们应如何合理的设置过期时间缓存穿透、缓存击穿、缓存雪崩有什么区别,该如何解决?缓存穿透:问题描述:解决方案:缓存击穿:问题描述:解决方案:缓存雪崩... 查看详情
redis过期删除策略和内存淘汰策略
...s的基础上,在新加监听配置监听配置类监听类将Redis用作缓存时,如果内存空间用满,就会自动驱逐老的数据。Redis中有6种淘汰策略:redis.conf文件中配置策略,有2个地方: 查看详情
day750.redis缓存淘汰替换策略:redis是如何工作的-redis核心技术与实战(代码片段)
Redis缓存淘汰替换策略Hi,阿昌来也,今天学习记录的是关于Redis缓存淘汰替换策略。Redis缓存使用内存来保存数据,避免业务应用从后端数据库中读取数据,可以提升应用的响应速度。那么,如果把所有要访问... 查看详情
flask-web缓存redis——架构缓存模式淘汰策略雪崩穿透(代码片段)
一、缓存的架构计算机体系结构中的缓存:多级缓存构建本地缓存方法:使用全局变量,一般适用于保存非常非常高频的数据项目的方案SQLAlchemy起到一定的本地缓存作用在同一请求中多次相同的查询只查询数据库一... 查看详情
缓存数据库redis之三:内存淘汰策略及优化(代码片段)
...略 1.1.概念 Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。 1.2.策略一:全局的键空间选择性移除-noeviction:当内存不足以容纳新写入数据时,... 查看详情
缓存数据库redis之三:内存淘汰策略及优化(代码片段)
目录一、Redis的内存淘汰策略 1.1.概念 1.2.策略一:全局的键空间选择性移除 1.3.策略二:设置过期时间的键空间选择性移除 1.4.LRU、LFU和volatile-ttl都是近似随机算法 1.4.1.LRU算法 1.4.2.LFU算法1.5.过期删除策略1.6.AOF... 查看详情
缓存数据库redis之三:内存淘汰策略及优化(代码片段)
目录一、Redis的内存淘汰策略 1.1.概念 1.2.策略一:全局的键空间选择性移除 1.3.策略二:设置过期时间的键空间选择性移除 1.4.LRU、LFU和volatile-ttl都是近似随机算法 1.4.1.LRU算法 1.4.2.LFU算法1.5.过期删除策略1.6.AOF... 查看详情
redis之缓存穿透击穿雪崩问题与缓存删除淘汰策略(代码片段)
一、缓存问题与解决缓存穿透缓存穿透是指查询缓存和DB中都不存在的数据。缓存穿透示例:publicStationfindProjectStation(LongstationId)//从缓存中查询Stationstation=(Station)redisTemplate.boundHashOps("project_station").get(stationId);if(station==null)// 查看详情
redis之缓存穿透击穿雪崩问题与缓存删除淘汰策略(代码片段)
一、缓存问题与解决缓存穿透缓存穿透是指查询缓存和DB中都不存在的数据。缓存穿透示例:publicStationfindProjectStation(LongstationId)//从缓存中查询Stationstation=(Station)redisTemplate.boundHashOps("project_station").get(stationId);if(station==null)// 查看详情
redis前传自己手写一个lru策略|redis淘汰策略(代码片段)
一、题目描述146.LRU缓存机制运用你所掌握的数据结构,设计和实现一个LRU(最近最少使用)缓存机制。实现LRUCache类:LRUCache(intcapacity)以正整数作为容量capacity初始化LRU缓存intget(intkey)如果关键字key存在于缓存中,则返回... 查看详情
redis前传自己手写一个lru策略|redis淘汰策略(代码片段)
一、题目描述146.LRU缓存机制运用你所掌握的数据结构,设计和实现一个LRU(最近最少使用)缓存机制。实现LRUCache类:LRUCache(intcapacity)以正整数作为容量capacity初始化LRU缓存intget(intkey)如果关键字key存在于缓存中,则返回... 查看详情
redis缓存淘汰算法——lrulfu(代码片段)
...持一下微信搜索程序dunk,关注公众号,获取博客源码、数据结构与算法笔记(超级全)、大厂面试、笔试题Redis过期键的删除策略对于过期键一般的三种删除策略定时删除:在设置键的过期时间的同时,创... 查看详情