关键词:
基于想自己下载网络小说的念头,认识到了python. 使用过后真是觉得是一门适合网络的语言,加上数不清的第三方库可以使用。适合快速开发。当然python也在数据分析,自然语义方面也有很多优势。这里主要介绍在网络方面的应用。
说到网络,和我们最接近的就是网页了。网页主要技术是http,当然还有javascript,XML,JSON,TCP连接等一大堆前端,后端的东东,关于http的知识这里不做多的描述,推荐看下http权威指南。

网页都是用html语言写的,关于HTML语言W3CSCHOOL上面有大量的介绍。而网络爬虫就是主要针对HTML语言而言。不如下面的百度的界面,用google浏览器点击F12,IE右击鼠标,然后选择查看网页源代码。左边是我们上网看到的百度页面,右边就是html源代码。被script包含的部分就是javascript。 这个页面主要是动态加载的页面,显示的内容主要是用javascript来驱动。看上去还不太直观。下面我们看一个更简单的
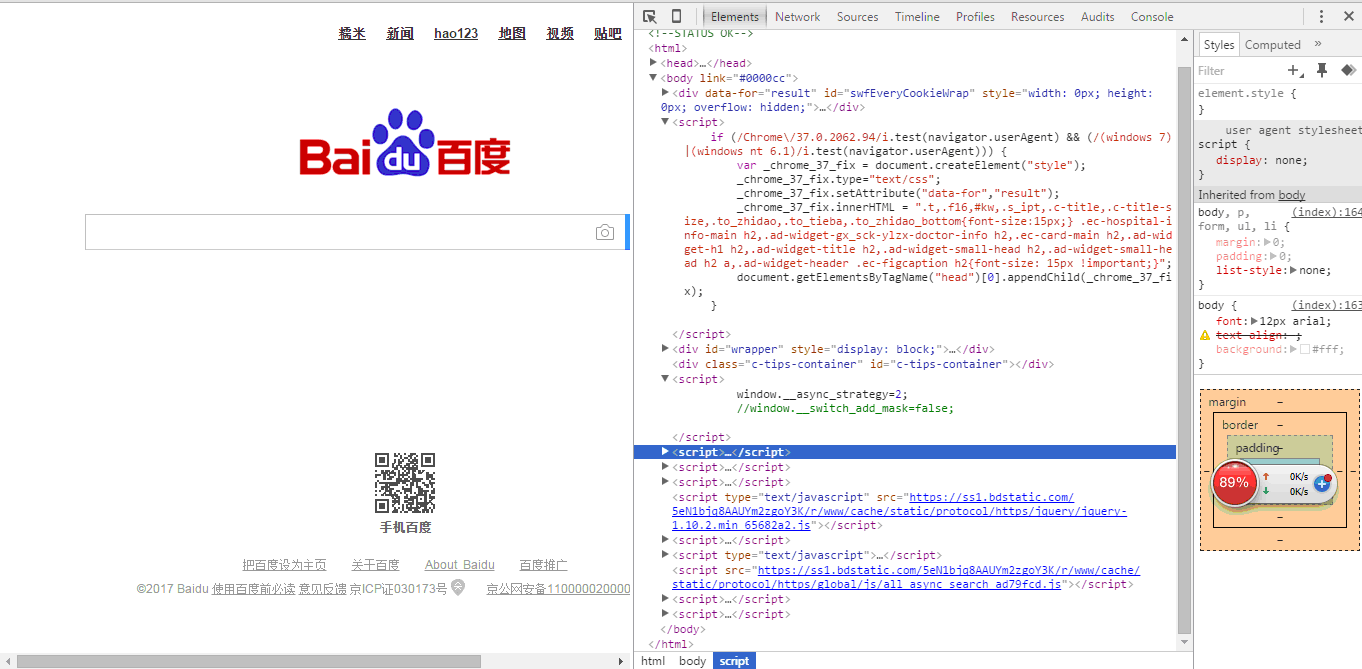
在百度一下上右击鼠标,然后选择审查元素,对于的HMTL代码就显示出来
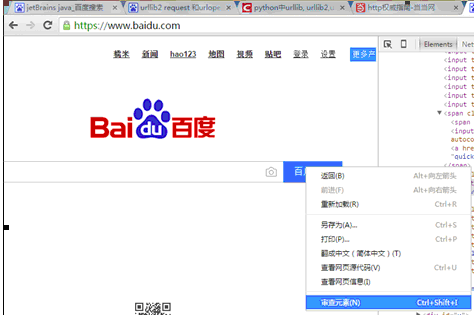
具体的代码:可以看到百度一下的这几个字在input元素里面,代表的是这是一个输入框
也许有人问,这和网络爬虫以及下载小说有啥关系,别急,前面的只是个网页的入门介绍。下面我们来看个小说的界面:下面是迅读网的小说,左边是小说正文,右边是相关的网页代码。大家看到没有,所有的小说正文都包含在标签是<div>并且id=”content_1”的的元素里面
如果我们能有工具能自动将HTML代码对应元素内容自动下载下来。不就可以自动下载小说了。这就是网络爬虫的功能,说白了网络爬虫就是解析HMTL代码并保存下来然后进行后处理的。简单来说就三个步骤:1 解析网页得到数据,2 保存数据 3 数据的后处理。下面我们就首先从第一步解析网页得到数据开始。
访问网页首先要请求URL,也就是网址链接。Python提供了urllib2函数进行链接。具体如下:
import urllib2
req=urllib2.Request(‘http://www.baidu.com.cn‘)
fd=urllib2.urlopen(req)
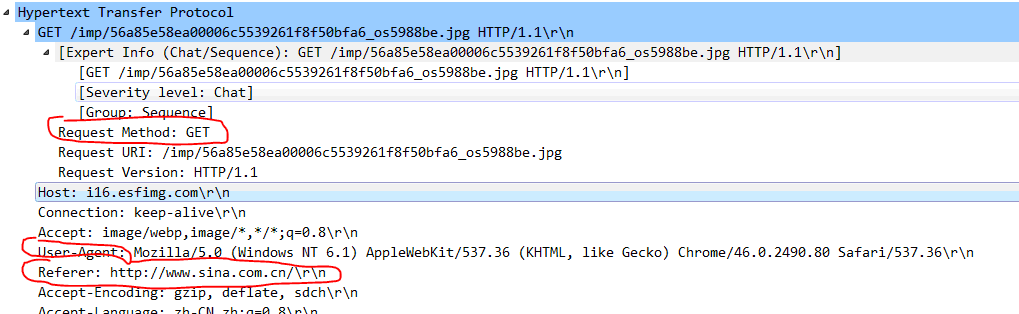
Request里面的第一个参数为网址的链接,里面还可以携带头信息以及具体要传递给网址的信息。这样说比较抽象。我们用wireshark抓取一个上网的报文。在google浏览器中输入www.sina.com.cn.可以看到如下信息。这就是从电脑上发出去的请求。其中有几个关键信息:Request Method: Get. 这里有两种方式,Get和Post,Get主要是用于请求数据,Post可以用来提交数据。
User-Agent指的是用户代码,什么意思呢。通过这些消息,服务器就能够识别客户使用的操作系统以及浏览器。一般服务器可以通过来识别是否是爬虫。这个后面讲
Referer可以认为是你需要从服务器上请求什么网址,这里可以看到就是sina
Accet-Encoding: 这是告诉电脑可以接受的数据压缩方式。
上图是浏览器上输入网址得到的抓包结果。如果我们运行程序结果会如何呢。下图是刚才python代码的截图结果。访问的网址是百度。从下面可以看到明显的差别。最重要的就是User-Agent变成了Python-urllib2/2.7. 这个字段给服务器一个明确的提示,这是一个程序发起的网页链接,也就是爬虫,而不是坐在电脑前的人在访问。由于爬虫进行链接一样会进行TCP等底层链接,因此为了防止大规模爬虫同时进行网页爬取。服务器会根据User-Agent来判断,如果是爬虫,则直接拒绝。
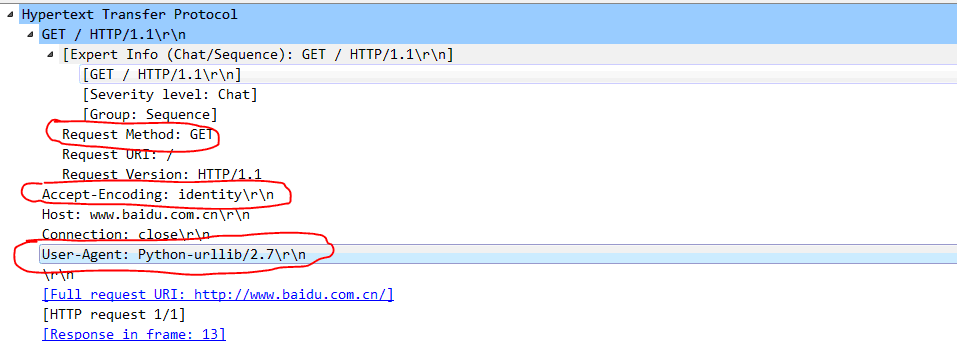
那么为了防止服务器禁掉我们的申请,该如何应对呢。我们自程序中自己构造一个和真实浏览器一样的User_Agent不就一样了。
user_agent="Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36"
headers=‘User-Agent‘:user_agent
req=urllib2.Request(‘http://www.baidu.com.cn‘,‘‘,headers)
fd=urllib2.urlopen(req)
添加了headers的描述。Request的第一个参数是网址,第二个参数是提交的数据,第三个参数是头信息。这里第二个参数暂时为空。第三个参数添加头信息,以字典的形式。可以看到抓包信息如下。这里就变成了我们和浏览器一样的形式,这样服务器就不会认为是爬虫了。下一步就是放心的抓取网页数据了。

有同学可能会问,如果我不小心输错了网址,该怎么办呢。这就要用到python的异常保护机制了。代码可以修改如下:
try:
user_agent="Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.80 Safari/537.36"
headers=‘User-Agent‘:user_agent
req=urllib2.Request(‘http://www.baidu.com.cn‘,‘‘,headers)
fd=urllib2.urlopen(req)
print fd.read().decode(‘utf-8‘).encode(‘GB18030‘)
html=BeautifulSoup(fd.read(),"lxml")
# print html.encode(‘gbk‘)
except urllib2.URLError,e:
print e.reason
增加了保护机制,其中URLError在没有网络连接或者服务器不存在的情况下产生,这种情况下,异常通常会带有reason属性.HTTP的错误码如下,具体参考HTTP权威指南
200:请求成功 处理方式:获得响应的内容,进行处理
201:请求完成,结果是创建了新资源。新创建资源的URI可在响应的实体中得到 处理方式:爬虫中不会遇到
202:请求被接受,但处理尚未完成 处理方式:阻塞等待
204:服务器端已经实现了请求,但是没有返回新的信 息。如果客户是用户代理,则无须为此更新自身的文档视图。 处理方式:丢弃
300:该状态码不被HTTP/1.0的应用程序直接使用, 只是作为3XX类型回应的默认解释。存在多个可用的被请求资源。 处理方式:若程序中能够处理,则进行进一步处理,如果程序中不能处理,则丢弃
301:请求到的资源都会分配一个永久的URL,这样就可以在将来通过该URL来访问此资源 处理方式:重定向到分配的URL
302:请求到的资源在一个不同的URL处临时保存 处理方式:重定向到临时的URL
304 请求的资源未更新 处理方式:丢弃
400 非法请求 处理方式:丢弃
401 未授权 处理方式:丢弃
403 禁止 处理方式:丢弃
404 没有找到 处理方式:丢弃
5XX 回应代码以“5”开头的状态码表示服务器端发现自己出现错误,不能继续执行请求 处理方式:丢弃
下面就是要打印出获取到的网页信息了。Request返回一个获取网页的实体,urlopen则是实现打开网页fd.read()则可以打印出网页的具体信息
代码里面有这个decode和encode的消息。这个是干嘛用的呢。这个主要是针对网页中的中文。Python3之前的中文输出是一个很忧伤的事情。
print fd.read().decode(‘utf-8‘).encode(‘GB18030‘)
网页上的数据也有自己的编码方式,从下面的截图的网页代码看到编码方式是utf-8.而在windows中中文的编码方式是GBK。
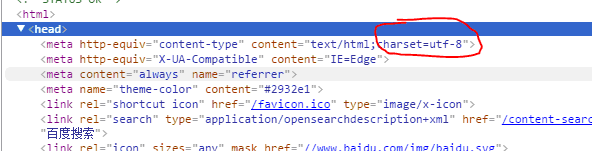
因此如果不进行编码转换的话,网页中的中文就会是乱码形式:

那么是否可以提前获取网页的编码方式呢,这也是可以的。如下代码就可以得到网页返回的编码方式
fd1=urllib2.urlopen(req).info()
print fd1.getparam(‘charset‘)
到此,我们已经成功的进行网页链接,并获取到了网页内容。下一步就是进行网页解析了。后面讲介绍beautifulSoup,lxml,HTMLParser,scrapy,selenium等常用的爬虫工具用法
爬虫实战国家企业公示网-crawler爬虫抓取数据(代码片段)
...现3.完成后的项目文件结构4.后续可以继续完善学习目标了解crawler爬虫运行流程了解crawler爬虫模块实现1.crawler功能初始化driver输入公司名称,并点击判断是否需要验证如果需要验证,获取验证图片并保存获取打码坐标点击验证... 查看详情
爬虫原理与数据抓取-----(了解)通用爬虫和聚焦爬虫(代码片段)
通用爬虫和聚焦爬虫根据使用场景,网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种.通用爬虫通用网络爬虫是捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形... 查看详情
python爬虫2beautifulsoup快速抓取网站图片(代码片段)
前言学习,最重要的是要了解它,并且使用它,正所谓,学以致用、本文,我们将来介绍,BeautifulSoup模块的使用方法,以及注意点,帮助大家快速了解和学习BeautifulSoup模块。有兴趣了解爬虫的小伙... 查看详情
python爬虫2beautifulsoup快速抓取网站图片(代码片段)
前言学习,最重要的是要了解它,并且使用它,正所谓,学以致用、本文,我们将来介绍,BeautifulSoup模块的使用方法,以及注意点,帮助大家快速了解和学习BeautifulSoup模块。有兴趣了解爬虫的小伙... 查看详情
python爬虫2beautifulsoup快速抓取网站图片(代码片段)
前言学习,最重要的是要了解它,并且使用它,正所谓,学以致用、本文,我们将来介绍,BeautifulSoup模块的使用方法,以及注意点,帮助大家快速了解和学习BeautifulSoup模块。有兴趣了解爬虫的小伙... 查看详情
爬虫第一章(代码片段)
爬虫基础什么是爬虫?爬虫是通过程序模拟浏览器上网,从网上获取数据的过程.爬虫的分类: 通用爬虫:爬取一整个页面的数据. 聚焦爬虫:爬取页面中指定的局部数据 增量式爬虫:检测网站中数据更新的情况,爬取的是网站... 查看详情
第一次爬虫实例(代码片段)
第一次爬虫实例1、这是我第一次写的爬虫实例,写的不好请见谅,最后发现爬取的次数多了,被网站拉黑了,还是需要代理才行,代理还不太清楚怎么弄就先这样了后面请大神可以帮忙改下怎么使用代理爬取。第一次爬取网站... 查看详情
爬虫jsonajax,来了解一下!(代码片段)
1初识1.1JSONJavaScript对象表示法(JavaScriptObjectNotation)。是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台... 查看详情
爬小说(第一次编写爬虫)(代码片段)
1importrequests2importre3html=‘http://www.jingcaiyuedu.com/book/317834.html‘4response=requests.get(html)5‘‘‘while(str(response)!="<Response[200]>"):6response=requests.get(html)7print(response)8‘ 查看详情
5.13第一次爬虫和测试(代码片段)
1importrequests2frombs4importBeautifulSoup34count=05forxinrange(20):6count+=17res_web=requests.get(‘https://www.baidu.com/‘)(由于谷歌网站遭遇反爬虫,于是改为百度网站)8print(‘第次的响应码为:‘.format(count,res_web.status_code 查看详情
python-入门的第一个爬虫例子(代码片段)
...为大家入门爬虫来做一次简单的例子,让大家更直观的来了解爬虫。本次我们利用Requests和正则表达式来抓取豆瓣电影的相关内容。一、本次目标:我们要提取出豆瓣电影-正在上映电影名称、评分、图片的信息,提取的站点URL为... 查看详情
爬虫第一课(代码片段)
一、小说下载小说网址是:http://www.biqukan.comimportrequestsfrombs4importBeautifulSoupclassdownloader(object):def__init__(self):self.url=‘http://www.biqukan.com/1_1408/‘self.serve=‘http://www.biqukan.com‘se 查看详情
python爬虫速度很慢?并发编程了解一下吧(代码片段)
...程度上提升IO密集型程序的执行效率。再开始之前你要先了解以下概念!基础知识并发 查看详情
python爬虫——刚学会爬虫,第一次实践就爬取了《长津湖》影评数据(代码片段)
思路:数据采集清洗入库分析处理1.数据采集接口地址https://m.maoyan.com/mmdb/comments/movie/257706.json?_v_=yes&offset=15&startTime=解析地址:257706代表电影ID长津湖offset=15代表:每次加载多少条数据15条start 查看详情
python爬虫——刚学会爬虫,第一次实践就爬取了《长津湖》影评数据(代码片段)
思路:数据采集清洗入库分析处理1.数据采集接口地址https://m.maoyan.com/mmdb/comments/movie/257706.json?_v_=yes&offset=15&startTime=解析地址:257706代表电影ID长津湖offset=15代表:每次加载多少条数据15条start 查看详情
scrapy框架学习第一步,了解它的运作流程(代码片段)
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之... 查看详情
了解爬虫(代码片段)
1什么是互联网互联网是由于网络设备(网线,路由器,交换机,防火墙等等)和计算机连接而成,像一张网一样。1.1互联网建立的目的?互联网的核心价值在于数据的共享和传递,数据是放在一台计算机上的,而将计算机互联到一... 查看详情
爬虫进阶chrome在爬虫中的使用(必备技能)(代码片段)
...找action对的url地址3.2通过抓包寻找登录的url地址学习目标了解新建隐身窗口的目的了解chrome中network的使用了解寻找登录接口的方法1新建隐身窗口浏览器中直接打开网站,会自动带上之前网站 查看详情