关键词:
@
问题引出
要求将统计结果按照条件输出到不同文件中(分区)。
比如:将统计结果按照手机归属地不同省份输出到不同文件中(分区)
默认Partitioner分区
public class HashPartitioner<K,V> extends Partitioner<K,V>
public int getPartition(K key,V value, int numReduceTasks)
return (key.hashCode() & Integer.MAX VALUE) & numReduceTasks;
- 默认分区是根据key的hashCode对ReduceTasks个数取模得到的。
- 用户没法控制哪个key存储到哪个分区。
自定义Partitioner步骤
- 自定义类继承
Partitioner,重写getPartition()方法
public class CustomPartitioner extends Partitioner<Text,FlowBea>
@Override
public int getPartition(Text key,FlowBean value,int numPartitions)
//控制分区代码逻辑
……
return partition;
- 在Job驱动类中,设置自定义
Partitioner
job.setPartitionerClass(CustomPartitioner.class)
- 自定义Partition后,要根据自定义Partitioner的逻辑设置相应数量的
ReduceTask
job.setNumReduceTask(5);//假设需要分5个区
Partition分区案例实操
将统计结果按照手机归属地不同省份输出到不同文件中(分区)
输入数据:
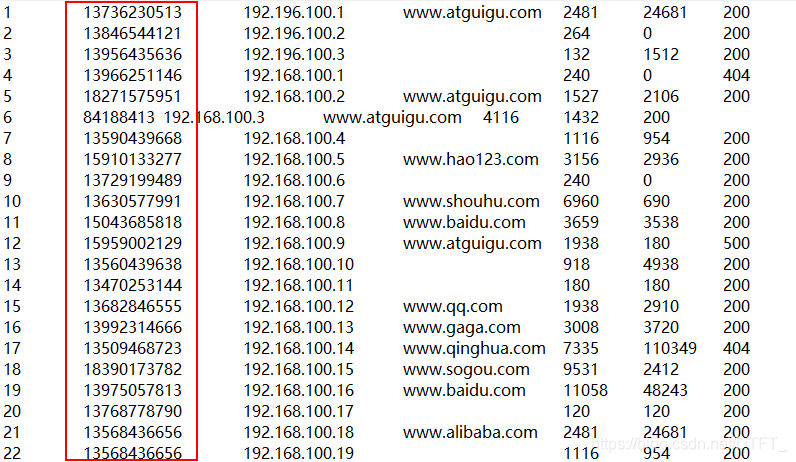
期望输出数据:
手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中。所以总共分为5个文件,也就是五个区。
相比于之前的自定义flowbean,这次自定义分区,只需要多编写一个分区器,以及在job驱动类中设置分区器,mapper和reducer类不改变
MyPartitioner.java
/*
* KEY, VALUE: Mapper输出的Key-value类型
*/
public class MyPartitioner extends Partitioner<Text, FlowBean>
// 计算分区 numPartitions为总的分区数,reduceTask的数量
// 分区号必须为int型的值,且必须符合 0<= partitionNum < numPartitions
@Override
public int getPartition(Text key, FlowBean value, int numPartitions)
String suffix = key.toString().substring(0, 3);//前开后闭,取手机号前三位数
int partitionNum=0;//分区编号
switch (suffix)
case "136":
partitionNum=numPartitions-1;//由于分区编号不能大于分区总数,所以用这种方法比较好
break;
case "137":
partitionNum=numPartitions-2;
break;
case "138":
partitionNum=numPartitions-3;
break;
case "139":
partitionNum=numPartitions-4;
break;
default:
break;
return partitionNum;
FlowBeanDriver.java
public class FlowBeanDriver
public static void main(String[] args) throws Exception
Path inputPath=new Path("e:/mrinput/flowbean");
Path outputPath=new Path("e:/mroutput/partitionflowbean");
//作为整个Job的配置
Configuration conf = new Configuration();
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath))
fs.delete(outputPath, true);
// ①创建Job
Job job = Job.getInstance(conf);
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(FlowBeanMapper.class);
job.setReducerClass(FlowBeanReducer.class);
// Job需要根据Mapper和Reducer输出的Key-value类型准备序列化器,通过序列化器对输出的key-value进行序列化和反序列化
// 如果Mapper和Reducer输出的Key-value类型一致,直接设置Job最终的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 设置ReduceTask的数量为5
job.setNumReduceTasks(5);
// 设置使用自定义的分区器
job.setPartitionerClass(MyPartitioner.class);
// ③运行Job
job.waitForCompletion(true);
FlowBeanMapper.java
/*
* 1. 统计手机号(String)的上行(long,int),下行(long,int),总流量(long,int)
*
* 手机号为key,Bean上行(long,int),下行(long,int),总流量(long,int)为value
*
*
*
*
*/
public class FlowBeanMapper extends Mapper<LongWritable, Text, Text, FlowBean>
private Text out_key=new Text();
private FlowBean out_value=new FlowBean();
// (0,1 13736230513 192.196.100.1 www.atguigu.com 2481 24681 200)
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context)
throws IOException, InterruptedException
String[] words = value.toString().split(" ");
//封装手机号
out_key.set(words[1]);
// 封装上行
out_value.setUpFlow(Long.parseLong(words[words.length-3]));
// 封装下行
out_value.setDownFlow(Long.parseLong(words[words.length-2]));
context.write(out_key, out_value);
FlowBeanReducer.java
public class FlowBeanReducer extends Reducer<Text, FlowBean, Text, FlowBean>
private FlowBean out_value=new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context)
throws IOException, InterruptedException
long sumUpFlow=0;
long sumDownFlow=0;
for (FlowBean flowBean : values)
sumUpFlow+=flowBean.getUpFlow();
sumDownFlow+=flowBean.getDownFlow();
out_value.setUpFlow(sumUpFlow);
out_value.setDownFlow(sumDownFlow);
out_value.setSumFlow(sumDownFlow+sumUpFlow);
context.write(key, out_value);
FlowBean.java
public class FlowBean implements Writable
private long upFlow;
private long downFlow;
private long sumFlow;
public FlowBean()
public long getUpFlow()
return upFlow;
public void setUpFlow(long upFlow)
this.upFlow = upFlow;
public long getDownFlow()
return downFlow;
public void setDownFlow(long downFlow)
this.downFlow = downFlow;
public long getSumFlow()
return sumFlow;
public void setSumFlow(long sumFlow)
this.sumFlow = sumFlow;
// 序列化 在写出属性时,如果为引用数据类型,属性不能为null
@Override
public void write(DataOutput out) throws IOException
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
//反序列化 序列化和反序列化的顺序要一致
@Override
public void readFields(DataInput in) throws IOException
upFlow=in.readLong();
downFlow=in.readLong();
sumFlow=in.readLong();
@Override
public String toString()
return upFlow + " " + downFlow + " " + sumFlow;
输出结果:
总共五个文件
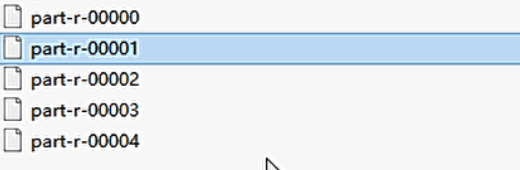
一号区:

二号区:

三号区:

四号区:

其他号码为第五号区:

分区总结
- 如果
ReduceTask的数量 > getPartition的结果数,则会多产生几个空的输出文件part-r-000xx - 如果
Reduceask的数量 < getPartition的结果数,则有一部分分区数据无处安放,会Exception - 如果
ReduceTask的数量 = 1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件partr-00000
以刚才的案例分析:
例如:假设自定义分区数为5,则
- job.setlNlurmReduce Task(1);会正常运行,只不过会产生一个输出文件
- job.setlNlunReduce Task(2),会报错
- job.setNumReduceTasks(6);大于5,程序会正常运行,会产生空文件
Hadoop Oozie MapReduce 操作自定义分区器
】HadoopOozieMapReduce操作自定义分区器【英文标题】:HadoopOozieMapReduceActionCustomPartitioner【发布时间】:2017-08-0214:17:46【问题描述】:如何在oozie工作流XML上为MapReduce操作配置自定义分区器?我尝试使用:<property><name>mapreduce... 查看详情
[mapreduce_8]mapreduce中的自定义分区实现(代码片段)
0.说明 设置分区数量&&编写自定义分区代码 1.设置分区数量 分区(Partition) 分区决定了指定的Key进入到哪个Reduce中 默认hash分区,算法//返回的分区号(key.hashCode()&Integer.MAX_VALUE)%numReduceTasks&nb... 查看详情
mapreduce的partition分区(代码片段)
一、Partitioner分区位置从MapRedece框架原理里面我们发现在进入环形缓冲区有一个分区的操作,如图二、Partitioner分区机制源码默认采用HashPartitioner,源码如下publicclassHashPartitioner<K2,V2>implementsPartitioner<K2,V2>publicvoidco... 查看详情
mapreduce之自定义inputformat(代码片段)
在企业开发中,Hadoop框架自带的InputFormat类型不能满足所有应用场景,需要自定义InputFormat来解决实际问题。自定义InputFormat步骤如下:(1)自定义一个类继承FilelnputFormat。(2)自定义一个类继承RecordReader,实现一次读取一个完... 查看详情
mapreduce框架原理mapreduce工作流程&shuffle机制(代码片段)
【MapReduce框架原理】1.MapReduce工作流程2.Shuffle机制2.1Shuffle机制2.2Partition分区2.3自定义Partitioner步骤2.4分区总结2.5案例分析3.Partition分区案例实操3.1需求3.2需求分析3.3在案例2.3的基础上,增加一个分区类3.4在驱动函数中增加自定... 查看详情
hadoop中的mapreduce框架原理自定义partitioner步骤在job驱动中,设置自定义partitionerpartition分区案例(代码片段)
文章目录13.MapReduce框架原理13.3Shuffle机制13.3.2Partition分区13.3.2.3自定义Partitioner步骤13.3.2.3.1自定义类继承Partitioner,重写getPartition()方法13.3.2.3.2在Job驱动中,设置自定义Partitioner13.3.2.3.3自定义Partition后,要 查看详情
MapReduce 中的自定义动态分区
】MapReduce中的自定义动态分区【英文标题】:CustomDynamicPartitionsinMapReduce【发布时间】:2019-02-0619:38:31【问题描述】:我正在使用MapReduce来处理我的数据。我需要将输出存储在日期分区下。我的排序键是日期字符串。现在,如果... 查看详情
mapreduce之自定义combiner(代码片段)
概述Combinar继承了`Reducer`, 可选过程,在map端的实现分组(是在map端运行的reduce),减小网络IO传输; 使用Combiner需要满足的条件Combiner不能影响最终计算结果例如求平均值就不能使用Combiner输出k-v类型必须与map输出一致自定义过... 查看详情
未调用 hadoop mapreduce 分区程序
】未调用hadoopmapreduce分区程序【英文标题】:hadoopmapreducepartitionernotinvoked【发布时间】:2014-03-0609:58:31【问题描述】:我需要有关mapreduce工作的帮助,我的自定义分区器从未被调用。我检查了所有内容数百万次,但没有结果。前... 查看详情
kafka分区分配计算(分区器partitions)(代码片段)
...是经过序列化Serializer处理,之后就到了Partitions阶段,即分区分配计算阶段。在某些应用场景下,业务逻辑需要控制每条消息落到合适的分区中,有些情形下则只要根据默认的分配规则即可。在KafkaProducer计算分配时,首先根据的... 查看详情
mapreduce深入
hadoop中map和reduce都是进程(spark中是线程),map和reduce可以部署在同一个机器上也可以部署在不同机器上。输入数据是hdfs的block,通过一个map函数把它转化为一个个键值对,并同时将这些键值对写入内存缓存区(100M),... 查看详情
mapreduce的工作流程
MapReduce的工作流程 1.客户端将每个block块切片(逻辑切分),每个切片都对应一个map任务,默认一个block块对应一个切片和一个map任务,split包含的信息:分片的元数据信息,包含起始位置,长度,和所在节点列表等... 查看详情
mapreduce学习4----自定义分区自定义排序自定义组分
1.map任务处理1.3对输出的key、value进行分区。分区的目的指的是把相同分类的<k,v>交给同一个reducer任务处理。 publicstaticclassMyPartitioner<Text,LongWritable>extendsPartitioner<Text,LongWritable>{ staticHashMap<Stri 查看详情
jvm进阶之自定义类加载器(代码片段)
自定义类加载器1.作用2.场景3.注意4.实现1.作用隔离加载类在某些框架内进行中间件与应用的模块隔离,把类加载到不同的环境。修改类加载的方式类的加载模型并非强制的,应该根据实际情况在某个时间点按需进行动态... 查看详情
jvm进阶之自定义类加载器(代码片段)
自定义类加载器1.作用2.场景3.注意4.实现1.作用隔离加载类在某些框架内进行中间件与应用的模块隔离,把类加载到不同的环境。修改类加载的方式类的加载模型并非强制的,应该根据实际情况在某个时间点按需进行动态... 查看详情
hadoop3-mapreduce分区介绍及自定义分区(代码片段)
一、MapReduce分区上篇文章使用COVID-19对MapReduce进一步的案例理解,本篇文章讲解MapReduce分区,下面是上篇文章的地址:https://blog.csdn.net/qq_43692950/article/details/127475811在默认情况下,不管map阶段有多少个并发执行task,... 查看详情
与java类型相比较,mapreduce中定义的数据类型都有哪些特点?
参考技术AMapReduce是一种编程模型,用于在分布式计算集群上处理大量数据。它通常用于计算和分析海量的数据集,例如搜索引擎中的网页抓取数据、社交网络中的用户信息等。MapReduce中定义的数据类型与Java类型相比有以下几个... 查看详情
kafka总结
...个键的消息会被写到同一个分区上。生产者也可以使用自定义的分区器。读取消息。消费者订阅一个或多个主题,并按照消息生产的顺序读取它们。消费者通过检查消息的偏移量来区分已经读取过的消息。偏移量是另一种元数据... 查看详情