关键词:
分词技术就是搜索引擎针对用户提交查询的关键词串进行的查询处理后根据用户的关键词串用各种匹配方法进行分词的一种技术。
中文分词(Chinese Word Segmentation)指的是将一个汉字序列(句子)切分成一个一个的单独的词,分词就是将连续的字序列按照一定的规则重新组合成词序列的过程。
现在分词方法大致有三种:基于字符串配置的分词方法、基于理解的分词方法和基于统计的分词方法。
今天为大家分享一个国内使用人数最多的中文分词工具GoJieba,源代码地址:GoJieba ,官方文档:GoJieba官方文档
 ?
?
官方介绍
- 支持多种分词方式,包括: 最大概率模式, HMM新词发现模式, 搜索引擎模式, 全模式
- 核心算法底层由C++实现,性能高效。
- 无缝集成到 Bleve 到进行搜索引擎的中文分词功能。
- 字典路径可配置,NewJieba(...string), NewExtractor(...string) 可变形参,当参数为空时使用默认词典(推荐方式)
模式扩展
- 精确模式:将句子精确切开,适合文本字符分析
- 全模式:把短语中所有的可以组成词语的部分扫描出来,速度非常快,会有歧义
- 搜索引擎模式:精确模式基础上,对长词再次切分,提升引擎召回率,适用于搜索引擎分词
主要算法
- 前缀词典实现高效的词图扫描,生成句子中汉字所有可能出现成词情况所构成的有向无环图(DAG)
- 采用动态规划查找最大概率路径,找出基于词频最大切分组合
- 对于未登录词,采用汉字成词能力的HMM模型,采用Viterbi算法计算
- 基于Viterbi算法做词性标注
- 基于TF-IDF和TextRank模型抽取关键词
编码实现
package main
import (
"fmt"
"github.com/yanyiwu/gojieba"
"strings"
)
func main()
var seg = gojieba.NewJieba()
defer seg.Free()
var useHmm = true
var separator = "|"
var resWords []string
var sentence = "万里长城万里长"
resWords = seg.CutAll(sentence)
fmt.Printf("%s 全模式:%s
", sentence, strings.Join(resWords, separator))
resWords = seg.Cut(sentence, useHmm)
fmt.Printf("%s 精确模式:%s
", sentence, strings.Join(resWords, separator))
var addWord = "万里长"
seg.AddWord(addWord)
fmt.Printf("添加新词:%s
", addWord)
resWords = seg.Cut(sentence, useHmm)
fmt.Printf("%s 精确模式:%s
", sentence, strings.Join(resWords, separator))
sentence = "北京鲜花速递"
resWords = seg.Cut(sentence, useHmm)
fmt.Printf("%s 新词识别:%s
", sentence, strings.Join(resWords, separator))
sentence = "北京鲜花速递"
resWords = seg.CutForSearch(sentence, useHmm)
fmt.Println(sentence, " 搜索引擎模式:", strings.Join(resWords, separator))
sentence = "北京市朝阳公园"
resWords = seg.Tag(sentence)
fmt.Println(sentence, " 词性标注:", strings.Join(resWords, separator))
sentence = "鲁迅先生"
resWords = seg.CutForSearch(sentence, !useHmm)
fmt.Println(sentence, " 搜索引擎模式:", strings.Join(resWords, separator))
words := seg.Tokenize(sentence, gojieba.SearchMode, !useHmm)
fmt.Println(sentence, " Tokenize Search Mode 搜索引擎模式:", words)
words = seg.Tokenize(sentence, gojieba.DefaultMode, !useHmm)
fmt.Println(sentence, " Tokenize Default Mode搜索引擎模式:", words)
word2 := seg.ExtractWithWeight(sentence, 5)
fmt.Println(sentence, " Extract:", word2)
return
运行结果
go build -o gojieba
time ./gojieba
万里长城万里长 全模式:万里|万里长城|里长|长城|万里|里长
万里长城万里长 精确模式:万里长城|万里|长
添加新词:万里长
万里长城万里长 精确模式:万里长城|万里长
北京鲜花速递 新词识别:北京|鲜花|速递
北京鲜花速递 搜索引擎模式: 北京|鲜花|速递
北京市朝阳公园 词性标注: 北京市/ns|朝阳/ns|公园/n
鲁迅先生 搜索引擎模式: 鲁迅|先生
鲁迅先生 Tokenize Search Mode 搜索引擎模式: [鲁迅 0 6 先生 6 12]
鲁迅先生 Tokenize Default Mode搜索引擎模式: [鲁迅 0 6 先生 6 12]
鲁迅先生 Extract: [鲁迅 8.20023407859 先生 5.56404756434]
real 0m1.746s
user 0m1.622s
sys 0m0.124s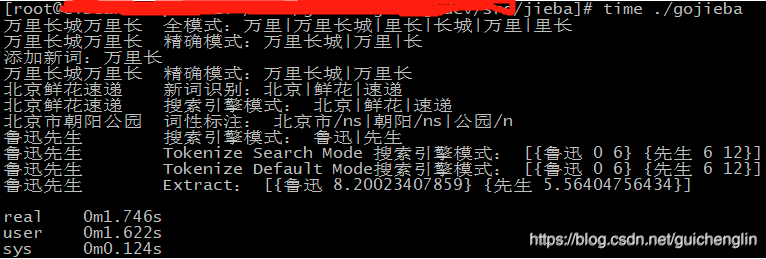
![]() ?
?
性能评测
| 语言 | 源码 | 耗时 |
| C++版本 | CppJieba | 7.5 s |
| Golang版本 | GoJieba | 9.11 s |
| Python版本 | Jieba | 88.7 s |
计算分词过程的耗时,不包括加载词典耗时,CppJieba性能是GoJieba的1.2倍。CppJieba性能详见jieba-performance-comparison,GoJieba由于是C++开发的CppJieba,性能方面仅次于CppJieba,如果追求性能还是可以考虑的。

![]() ?
?
中文分词资源
在学习nlp自然语言处理的过程中,免不了要使用中文分词资源作为分词依据或前期调研。所以想研究中文分词,第一步需要解决的就是资源问题。 作为中文信息处理的壁垒,中文分词在国内的关注度似乎远远超过了... 查看详情
java在一串中文中,怎么只拿机场或者港口的名字
要从一串中文中提取机场或者港口的名字,需要利用自然语言处理技术和相关的数据处理方法。下面是一些可能的实现方式:1.利用正则表达式进行匹配:针对中文,可以使用正则表达式来匹配机场或者港口的名称,例如匹配以... 查看详情
浅谈中文分词与自然语言处理
...新回顾中文分词技术,期间有些心得,以及一些关于自然语言处理的浅薄之见,这里简单分享一下。首先,中文分词_百度百科里面简单介绍了其中主要的分词算法以及相应的优缺点,包括字符匹配法、统计法以及理解法,其中... 查看详情
详解中文是如何进行分词-nlp学习(中文篇)(代码片段)
...如何分词的,我们都知道英文或者其他国家或者地区一些语言文字是词与词之间有空格(分隔符),这样子分词处理起来其实是要相对容易很多,但是像中文处理起来就没有那么容易,因为中文字与字之间,词与词之间都是紧密... 查看详情
day112es中文分词介绍
...分词器)、whitespaceanalyzer(空格分词器)、languageanalyzer(语言分词器)而如果我们不指定分词器类型的话,elasticsearch默认是使用标准分词器的我们需要下载中文分词插件,来实现中文分词二下载地址为:https: 查看详情
「gocn酷go推荐」go高性能多语言nlp和分词库——gse(代码片段)
gse是什么?Go高性能多语言NLP和分词库,支持英文、中文、日文等,支持接入elasticsearch和bleveGse是结巴分词(jieba)的golang实现,并尝试添加NLP功能和更多属性特征支持普通、搜索引擎、全模式、精确模式和HMM模式多种分词模式支持自定... 查看详情
编程实践golang实现中文分词
Golang实现中文分词分词技术就是搜索引擎针对用户提交查询的关键词串进行的查询处理后根据用户的关键词串用各种匹配方法进行分词的一种技术。中文分词(ChineseWordSegmentation)指的是将一个汉字序列(句子)切分成一个一个... 查看详情
中文分词的常见项目
...分类定义。能够对未知的词汇进行合理解析。仅支持Java语言。MMSEG4J基于Java的开源中文分词组件,提供lucene和solr接口:1.mmseg4j用Chih-HaoTsai的MMSeg算法实现的中文分词器,并实现lucene的analyzer和solr的TokenizerFactory以方便在Lucene和Sol... 查看详情
solr中文分词
...版本上有不兼容的情况,由于它是一个开源的,基于java语言开发的轻量级的 查看详情
r语言中文分词包jiebar
650)this.width=650;"src="http://blog.fens.me/wp-content/uploads/2016/07/jiebaR.png"width="600"height="400"alt="jiebaR.png"/>前言本文挖掘是数据挖掘中一个非常重要的部分,有非常广阔的使用场景,比如我们可以对新闻事件进行分析,了解国家大事;也可... 查看详情
有哪些比较好的中文分词方案?
...分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块。不同于英文的是,中文句子中没有词的界限,因此在进行中文自然语言处理时,通常需要先进行分词,分词效果将直接影响词性、句法树等模块的效... 查看详情
ikanalyzer结合lucene实现中文分词
...停止词、提取词干的过程基本就能实现英文分词,单对于中文分词而言,由于语义的复杂导致分词并没英文分词那么简单,一般都是通过相关的分词工具来实现,目前比较常用的有庖丁分词以及IKAnalyzer等。这里我们主要通过一... 查看详情
中文分词的原理是啥?
我想要知道中文分词工具的原理什么?求大神帮帮忙?我使用的是python的jieba分词,它的原理是首先将要分词的字符串与自身的词典进行匹配查找,如果字典中有词语就返回该词语,然后使用HMM模型对其余为分出词语的词进行算... 查看详情
中文分词实践(基于r语言)
背景:分析用户在世界杯期间讨论最多的话题。 思路:把用户关于世界杯的帖子拉下来。然后做中文分词+词频统计,最后将统计结果简单做个标签云。效果例如以下: 兴许:中文分词是... 查看详情
为啥solr使用中文分词cmd命令行会出现异常
参考技术A方法一:在当前目录下,按下shift+鼠标右键,会出现“在此处打开命令窗口”的字样,然后点击即可。方法二:在该文件夹上,按下shift+鼠标右键,会出现“在此处打开命令窗口”的字样,然后点击即可。 查看详情
1.jieba中文处理
参考技术Ajieba是一个在中文自然语言处理中用的最多的工具包之一,它以分词起家,目前已经能够实现包括分词、词性标注以及命名实体识别等多种功能。既然Jieba是以分词起家,我们自然要首先学习Jieba的中文分词功能。Jieba提... 查看详情
java中文分词为啥用ik
...Lucene自带的分词器比较适合英文的分词,而IK首先是一个中文的分词器。具体的优点先不细说,单说分词的结果来看:1比如说我爱北京使用自带的分词我/爱/北/京IK分词我/爱/北京2可以自己扩展词典有很多分词器是不能够进行自... 查看详情
mmseg中文分词算法解析
Mmseg中文分词算法解析@author linjiexing开发中文搜索和中文词库语义自己主动识别的时候,我採用都是基于mmseg中文分词算法开发的Jcseg开源project。使用场景涉及搜索索引创建时的中文分词、新词发现的中文分词、语义词向量空... 查看详情