关键词:
你很可能从某种途径听说过 Go 语言。它越来越受欢迎,并且有充分的理由可以证明。 Go 快速、简单,有强大的社区支持。学习这门语言最令人兴奋的一点是它的并发模型。 Go 的并发原语使创建多线程并发程序变得简单而有趣。我将通过插图介绍 Go 的并发原语,希望能点透相关概念以方便后续学习。本文是写给 Go 语言编程新手以及准备开始学习 Go 并发原语 (goroutines 和 channels) 的同学。
单线程程序 vs. 多线程程序
你可能已经写过一些单线程程序。一个常用的编程模式是组合多个函数来执行一个特定任务,并且只有前一个函数准备好数据,后面的才会被调用。

首先我们将用上述模式编写第一个例子的代码,一个描述挖矿的程序。它包含三个函数,分别负责执行寻矿、挖矿和练矿任务。在本例中,我们用一组字符串表示 rock(矿山) 和 ore(矿石),每个函数都以它们作为输入,并返回一组 “处理过的” 字符串。对于一个单线程的应用而言,该程序可能会按如下方式来设计:
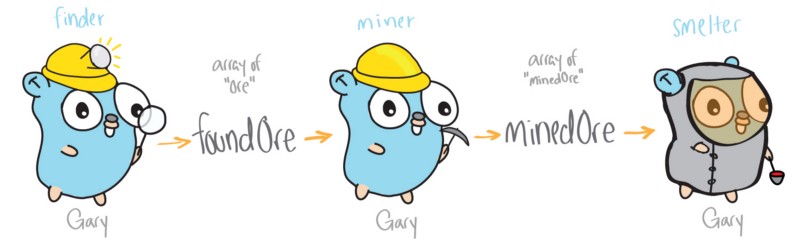
它有三个主要的函数:finder、miner 和 smelter。该版本的程序的所有函数都在单一线程中运行,一个接着一个执行,并且这个线程 (名为 Gary 的 gopher) 需要处理全部工作。
func main() theMine := [5]string"rock", "ore", "ore", "rock", "ore" foundOre := finder(theMine) minedOre := miner(foundOre) smelter(minedOre)
在每个函数最后打印出 "ore" 处理后的结果,得到如下输出:
From Finder: [ore ore ore] From Miner: [minedOre minedOre minedOre] From Smelter: [smeltedOre smeltedOre smeltedOre]
这种编程风格具有易于设计的优点,但是当你想利用多个线程并执行彼此独立的函数时会发生什么呢?这就是并发程序设计发挥作用的地方。
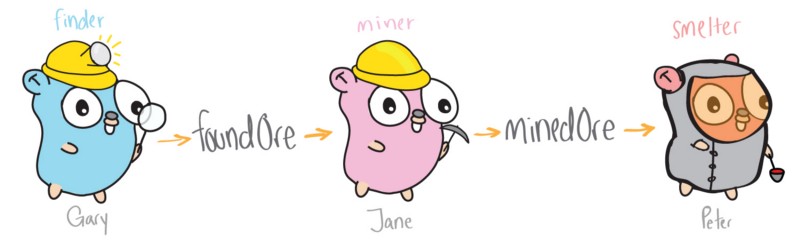
这种设计使得 “挖矿” 更高效。现在多个线程 (gophers) 是独立运行的,从而 Gary 不再承担全部工作。其中一个 gopher 负责寻矿,一个负责挖矿,另一个负责练矿,这些工作可能同时进行。
为了将这种并发特性引入我们的代码,我们需要创建独立运行的 gophers 的方法以及它们之间彼此通信 (传送矿石) 的方法。这就需要用到 Go 的并发原语:goroutines 和 channels。
Goroutines
Goroutines 可以看作是轻量级线程。创建一个 goroutine 非常简单,只需要把 go 关键字放在函数调用语句前。为了说明这有多么简单,我们创建两个 finder 函数,并用 go 调用,让它们每次找到 "ore" 就打印出来。

func main()
theMine := [5]string"rock", "ore", "ore", "rock", "ore"
go finder1(theMine)
go finder2(theMine)
<-time.After(time.Second * 5) //you can ignore this for now
程序的输出如下:
Finder 1 found ore!
Finder 2 found ore!
Finder 1 found ore!
Finder 1 found ore!
Finder 2 found ore!
Finder 2 found ore!
可以看出,两个 finder 是并发运行的。哪一个先找到矿石没有确定的顺序,当执行多次程序时,这个顺序并不总是相同的。
这是一个很大的进步!现在我们有一个简单的方法来创建多线程 (multi-gopher) 程序,但是当我们需要独立的 goroutines 之间彼此通信会发生什么呢?欢迎来到神奇的 channels 世界。
Channels
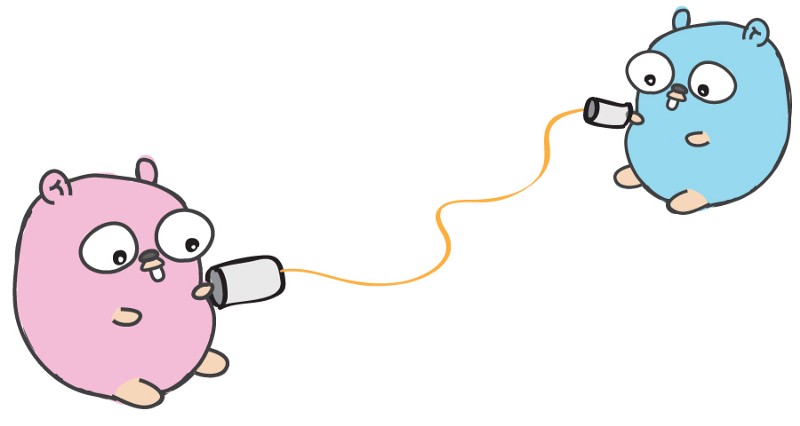
Channels 允许 go routines 之间相互通信。你可以把 channel 看作管道,goroutines 可以往里面发消息,也可以从中接收其它 go routines 的消息。
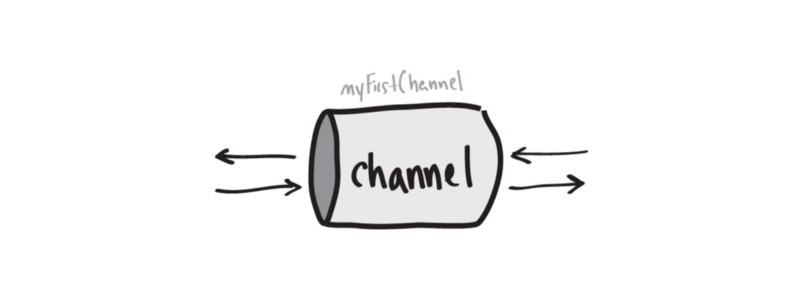
myFirstChannel := make(chan string)
Goroutines 可以往 channel 发送消息,也可以从中接收消息。这是通过箭头操作符 (<-) 完成的,它指示 channel 中的数据流向。
![]()
myFirstChannel <-"hello" // Send
myVariable := <- myFirstChannel // Receive
现在通过 channel 我们可以让寻矿 gopher 一找到矿石就立即传送给开矿 gopher ,而不用等发现所有矿石。
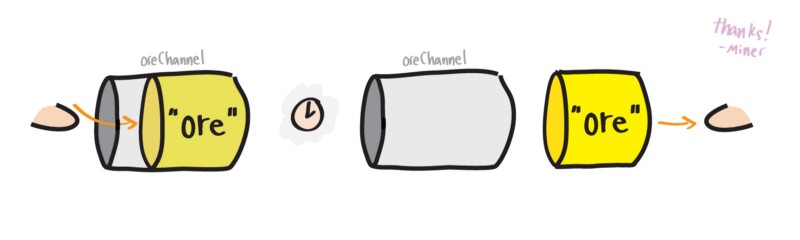
我重写了挖矿程序,把寻矿和开矿函数改写成了未命名函数。如果你从未见过 lambda 函数,不必过多关注这部分,只需要知道每个函数将通过 go 关键字调用并运行在各自的 goroutine 中。重要的是,要注意 goroutine 之间是如何通过 channel oreChan 传递数据的。别担心,我会在最后面解释未命名函数的。
func main()
theMine := [5]string"ore1", "ore2", "ore3"
oreChan := make(chan string)
// Finder
go func(mine [5]string)
for _, item := range mine
oreChan <- item //send
(theMine)
// Ore Breaker
go func()
for i := 0; i < 3; i++
foundOre := <-oreChan //receive
fmt.Println("Miner: Received " + foundOre + " from finder")
()
<-time.After(time.Second * 5) // Again, ignore this for now
从下面的输出,可以看到 Miner 从 oreChan 读取了三次,每次接收一块矿石。
Miner: Received ore1 from finder
Miner: Received ore2 from finder
Miner: Received ore3 from finder
太棒了,现在我们能在程序的 goroutines(gophers) 之间发送数据了。在开始用 channels 写复杂的程序之前,我们先来理解它的一些关键特性。
Channel Blocking
Channels 阻塞 goroutines 发生在各种情形下。这能在 goroutines 各自欢快地运行之前,实现彼此之间的短暂同步。
Blocking on a Send
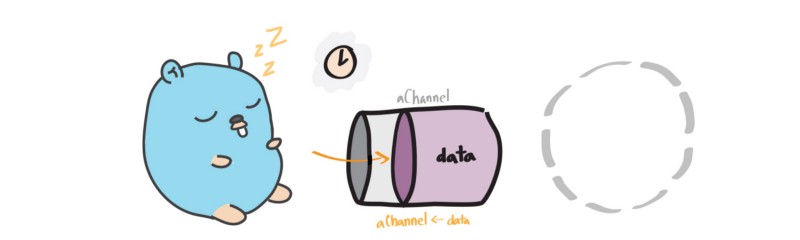
一旦一个 goroutine(gopher) 向一个 channel 发送数据,它就被阻塞了,直到另一个 goroutine 从该 channel 取走数据。
Blocking on a Receive
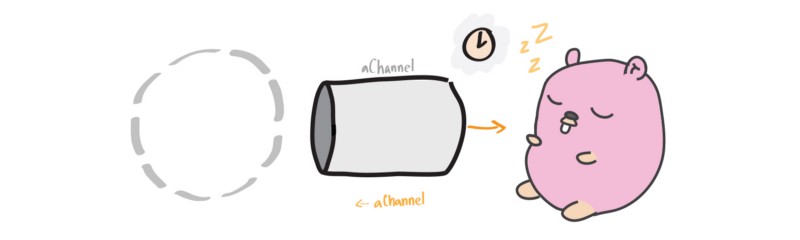
和发送时情形类似,一个 goroutine 可能阻塞着等待从一个 channel 获取数据,如果还没有其他 goroutine 往该 channel 发送数据。
一开始接触阻塞的概念可能令人有些困惑,但你可以把它想象成两个 goroutines(gophers) 之间的交易。 其中一个 gopher 无论是等着收钱还是送钱,都需要等待交易的另一方出现。
既然已经了解 goroutine 通过 channel 通信可能发生阻塞的不同情形,让我们讨论两种不同类型的 channels: unbuffered 和 buffered 。选择使用哪一种 channel 可能会改变程序的运行表现。
Unbuffered Channels
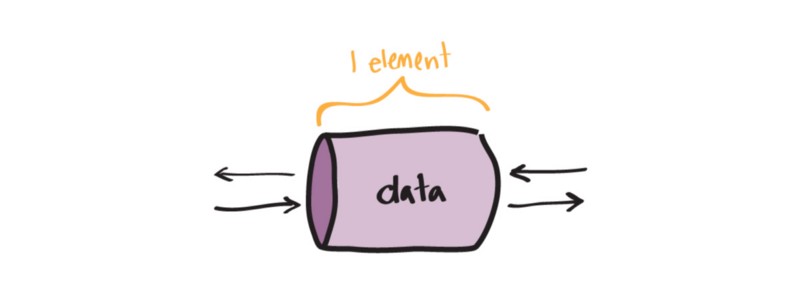
在前面的例子中我们一直在用 unbuffered channels,它们与众不同的地方在于每次只有一份数据可以通过。
Buffered Channels
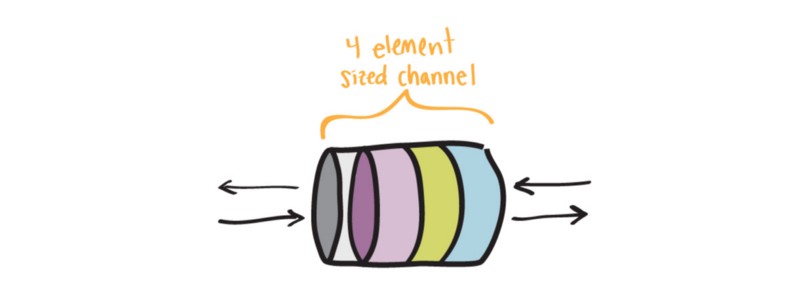
在并发程序中,时间协调并不总是完美的。在挖矿的例子中,我们可能遇到这样的情形:开矿 gopher 处理一块矿石所花的时间,寻矿 gohper 可能已经找到 3 块矿石了。为了不让寻矿 gopher 浪费大量时间等着给开矿 gopher 传送矿石,我们可以使用 buffered channel。我们先创建一个容量为 3 的 buffered channel。
bufferedChan := make(chan string, 3)
buffered 和 unbuffered channels 工作原理类似,但有一点不同—在需要另一个 gorountine 取走数据之前,我们可以向 buffered channel 发送多份数据。
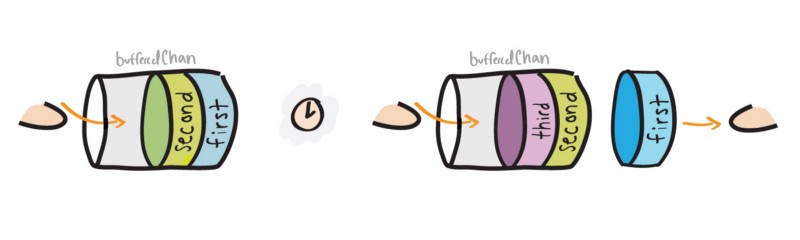
bufferedChan := make(chan string, 3)
go func()
bufferedChan <-"first"
fmt.Println("Sent 1st")
bufferedChan <-"second"
fmt.Println("Sent 2nd")
bufferedChan <-"third"
fmt.Println("Sent 3rd")
()
<-time.After(time.Second * 1)
go func()
firstRead := <- bufferedChan
fmt.Println("Receiving..")
fmt.Println(firstRead)
secondRead := <- bufferedChan
fmt.Println(secondRead)
thirdRead := <- bufferedChan
fmt.Println(thirdRead)
()
两个 goroutines 之间的打印顺序如下:
Sent 1st
Sent 2nd
Sent 3rd
Receiving..
first
second
third
为了简单起见,我们在最终的程序中不使用 buffered channels。但知道该使用哪种 channel 是很重要的。
注意: 使用 buffered channels 并不会避免阻塞发生。例如,如果寻矿 gopher 比开矿 gopher 执行速度快 10 倍,并且它们通过一个容量为 2 的 buffered channel 进行通信,那么寻矿 gopher 仍会发生多次阻塞。
把这些都放到一起
现在凭借 goroutines 和 channels 的强大功能,我们可以使用 Go 的并发原语编写一个充分发挥多线程优势的程序了。
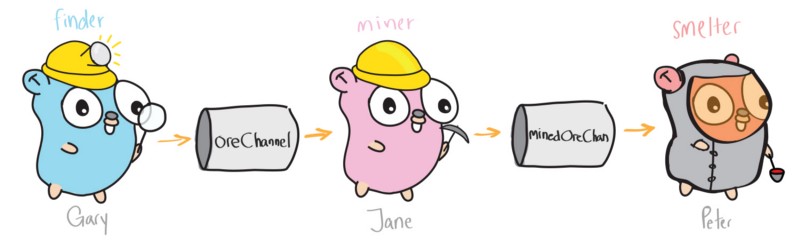
theMine := [5]string"rock", "ore", "ore", "rock", "ore"
oreChannel := make(chan string)
minedOreChan := make(chan string)
// Finder
go func(mine [5]string)
for _, item := range mine
if item == "ore"
oreChannel <- item //send item on oreChannel
(theMine)
// Ore Breaker
go func()
for i := 0; i < 3; i++
foundOre := <-oreChannel //read from oreChannel
fmt.Println("From Finder:", foundOre)
minedOreChan <-"minedOre" //send to minedOreChan
()
// Smelter
go func()
for i := 0; i < 3; i++
minedOre := <-minedOreChan //read from minedOreChan
fmt.Println("From Miner:", minedOre)
fmt.Println("From Smelter: Ore is smelted")
()
<-time.After(time.Second * 5) // Again, you can ignore this
程序输出如下:
From Finder: ore
From Finder: ore
From Miner: minedOre
From Smelter: Ore is smelted
From Miner: minedOre
From Smelter: Ore is smelted
From Finder: ore
From Miner: minedOre
From Smelter: Ore is smelted
相比最初的例子,已经有了很大改进!现在每个函数都独立地运行在各自的 goroutines 中。此外,每次处理完一块矿石,它就会被带进挖矿流水线的下一个阶段。
为了专注于理解 goroutines 和 channel 的基本概念,上文有些重要的信息我没有提,如果不知道的话,当你开始编程时它们可能会造成一些麻烦。既然你已经理解了 goroutines 和 channel 的工作原理,在开始用它们编写代码之前,让我们先了解一些你应该知道的其他信息。
在开始之前,你应该知道...
匿名的 Goroutines

类似于如何利用 go 关键字使一个函数运行在自己的 goroutine 中,我们可以用如下方式创建一个匿名函数并运行在它的 goroutine 中:
// Anonymous go routine
go func()
fmt.Println("I‘m running in my own go routine")
()
如果只需要调用一次函数,通过这种方式我们可以让它在自己的 goroutine 中运行,而不需要创建一个正式的函数声明。
main 函数是一个 goroutine

main 函数确实运行在自己的 goroutine 中!更重要的是要知道,一旦 main 函数返回,它将关掉当前正在运行的其他 goroutines。这就是为什么我们在 main 函数的最后设置了一个定时器—它创建了一个 channel,并在 5 秒后发送一个值。
<-time.After(time.Second * 5) // Receiving from channel after 5 sec
还记得 goroutine 从 channel 中读数据如何被阻塞直到有数据发送到里面吧?通过添加上面这行代码,main routine 将会发生这种情况。它会阻塞,以给其他 goroutines 5 秒的时间来运行。
现在有更好的方式阻塞 main 函数直到其他所有 goroutines 都运行完。通常的做法是创建一个 done channel, main 函数在等待读取它时被阻塞。一旦完成工作,向这个 channel 发送数据,程序就会结束了。

func main()
doneChan := make(chan string)
go func()
// Do some work…
doneChan <- "I‘m all done!"
()
<-doneChan // block until go routine signals work is done
你可以遍历 channel
在前面的例子中我们让 miner 在 for 循环中迭代 3 次从 channel 中读取数据。如果我们不能确切知道将从 finder 接收多少块矿石呢?
好吧,类似于对集合数据类型 (注: 如 slice) 进行遍历,你也可以遍历一个 channel。
更新前面的 miner 函数,我们可以这样写:
// Ore Breaker
go func()
for foundOre := range oreChan
fmt.Println("Miner: Received " + foundOre + " from finder")
()
由于 miner 需要读取 finder 发送给它的所有数据,遍历 channel 能确保我们接收到已经发送的所有数据。
遍历 channel 会阻塞,直到有新数据被发送到 channel。在所有数据发送完之后避免 go routine 阻塞的唯一方法就是用 "close(channel)" 关掉 channel。
对 channel 进行非阻塞读
但你刚刚告诉我们 channel 如何阻塞 goroutine 的各种情形?!没错,不过还有一个技巧,利用 Go 的 select case 语句可以实现对 channel 的非阻塞读。通过使用这这种语句,如果 channel 有数据,goroutine 将会从中读取,否则就执行默认的分支。
myChan := make(chan string)
go func()
myChan <- "Message!"
()
select
case msg := <- myChan:
fmt.Println(msg)
default:
fmt.Println("No Msg")
<-time.After(time.Second * 1)
select
case msg := <- myChan:
fmt.Println(msg)
default:
fmt.Println("No Msg")
程序输出如下:
No Msg
Message!
对 channel 进行非阻塞写
非阻塞写也是使用同样的 select case 语句来实现,唯一不同的地方在于,case 语句看起来像是发送而不是接收。
select
case myChan <- "message":
fmt.Println("sent the message")
default:
fmt.Println("no message sent")
go语言并发(代码片段)
并发与并行并发:同一时间段执行多个任务并行:同一时刻执行多个任务Go语言的并发通过goroutine实现。goroutine类似于线程,属于用户态的线程,我们可以根据需要创建成千上万个goroutine并发工作。goroutine是由Go语言的运行时调... 查看详情
图解go的unsafe.pointer(代码片段)
相信看过Go源码的同学已经对unsafe.Pointer非常的眼熟,因为这个类型可以说在源码中是随处可见:map、channel、interface、slice…但凡你能想到的内容,基本都会有unsafe.Pointer的影子。看字面意思,unsafe.Pointer是“不安全的指针”,指... 查看详情
go基础并发编程(代码片段)
并发编程并发编程Go并发的设计相关概念启动协程同步通道channel创建channelchannel的读写单方向channel定时器相关资料Go并发的设计 Go语言最大的特色是并发,而且Go的并发并不像线程或进程那样,受CPU核心数的限制,... 查看详情
go路由httprouter中的压缩字典树算法图解及c++实现(代码片段)
目录go路由httprouter中的压缩字典树算法图解及c++实现前言httprouter简介压缩字典树概念插入操作查询操作c+++实现go路由httprouter中的压缩字典树算法图解及c++实现@前言准备从嵌入式往go后端转,今年准备学习一下gin框架,决定先从... 查看详情
图解go引用的底层实现(代码片段)
Go怎么可能有引用?得了吧~有人要说了,那利用make()函数执行后得到的slice、map、channel等类型,不都是得到的引用吗?我要说:那能叫引用吗?你能确定啥叫引用吗?如果你有点迷糊,那么请听我往下讲:这一切要从变量说起。... 查看详情
图解go引用的底层实现(代码片段)
Go怎么可能有引用?得了吧~有人要说了,那利用make()函数执行后得到的slice、map、channel等类型,不都是得到的引用吗?我要说:那能叫引用吗?你能确定啥叫引用吗?如果你有点迷糊,那么请听我往下讲:这一切要从变量说起。... 查看详情
go语言系列之并发编程(代码片段)
Go语言中的并发编程并发与并行并发:同一时间段内执行多个任务(你在用微信和两个女朋友聊天)。并行:同一时刻执行多个任务(你和你朋友都在用微信和女朋友聊天)。Go语言的并发通过goroutine实现。goroutine类似于线程,... 查看详情
图解go的channel底层原理(代码片段)
废话不多说,直奔主题。channel的整体结构图简单说明:buf是有缓冲的channel所特有的结构,用来存储缓存数据。是个循环链表sendx和recvx用于记录buf这个循环链表中的发送或者接收的indexlock是个互斥锁。recvq和sendq分别是接收(<-ch... 查看详情
go并发编程模型(代码片段)
一、前言Go语言中实现了两种并发模型,一种是依赖于共享内存实现的线程-锁并发模型,另一种则是CSP(CommunicationingSequentialProcesses,通信顺序进程)并发模型。大多数编程语言(比如C++、Java、Python... 查看详情
图解算法基础--快速排序,附go代码实现(代码片段)
很多面试题的解答都是以排序为基础的,如果我们写出一个O()的算法,大概率要被挂,今天写个快排的基础文章,后面看情况再把归并和堆排序写一写,至于选择排序、冒泡排序这种时间复杂度高的就不写了,有兴趣的可以找书... 查看详情
go并发编程基础-channel(代码片段)
...runtime所调度,这一点和线程不一样。也就是说,Go语言的并发是由Go自己所调度的,自己决定同时执行多少个goroutine,什么时候执行哪几个。这些对于我们开发者来说完全透明,只需要在编码的时候告诉Go语 查看详情
go语言并发,并行,信道(代码片段)
go语言 并发 并行 信道packagemainimport("fmt""time")补充://并发:看上去在同一时间同时执行,实际是切换执行利用时间片轮转法,同一个CPU进行切换执行//并行:是在真正的同一时间两个程序同时进行吗,这个是在多核cpu... 查看详情
09.go语言并发(代码片段)
Go语言并发并发指在同一时间内可以执行多个任务。并发编程含义比较广泛,包含多线程编程、多进程编程及分布式程序等。本章讲解的并发含义属于多线程编程。Go语言通过编译器运行时(runtime),从语言上支持了并发的特性... 查看详情
go并发(代码片段)
packagemainimport("fmt""time")funcsay(sstring)fori:=0;i<5;i++time.Sleep(100*time.Millisecond)fmt.Println(s)funcmain()gosay("hello1")say("hello2")输出:hello2hello1hello1hello2hello2hello1hello2hello1hello2 查看详情
go语言实战并发模式(代码片段)
章节目录学习内容有:runner、pool、Go读写锁、以及总结。总结我习惯将其放在前面。总结稍后添加runnercommon.gopackagecommonimport("time""os""errors""os/signal")varErrTimeOut=errors.New("执行者执行超时")varErrInterrupt=errors.New("执行者被中断")//一个... 查看详情
go原生并发原语和最佳实践(代码片段)
...次演讲中,他将真正的问题确定为“需要一种方法来编写并发软件,以指导我们的设计和实现。”他接着说并发编程不是让程序并行化以更快地运行,而是“利用流程和通信的力量来设计优雅、响应迅速、可靠的系统。”包或任... 查看详情
go并发多线程goroutinechannel实例(代码片段)
Go语言支持并发,我们只需要通过go关键字来开启goroutine即可。一、goruntinegoroutine是轻量级线程,goroutine的调度是由Golang运行时进行管理的。goroutine语法格式:go函数名(参数列表)例如:gof(x,y,z)开启一个新的goroutine:... 查看详情
go语言并发与通道的运用(代码片段)
在go语言中我们可以使用goroutine开启并发。goroutine是轻量级线程,goroutine的调度是由Golang运行时进行管理的。goroutine语法格式:go函数名(参数列表)实例1:packagemainimport("fmt""time")funcsay(sstring)fori:=0;i< 查看详情