关键词:
文章很长,建议收藏起来慢慢读!疯狂创客圈总目录 语雀版 | 总目录 码云版| 总目录 博客园版 为您奉上珍贵的学习资源 :
-
免费赠送 经典图书:《Java高并发核心编程(卷1)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Java高并发核心编程(卷2)》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《Netty Zookeeper Redis 高并发实战》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 经典图书:《SpringCloud Nginx高并发核心编程》 面试必备 + 大厂必备 +涨薪必备 加尼恩免费领
-
免费赠送 资源宝库: Java 必备 百度网盘资源大合集 价值>10000元 加尼恩领取
Netty内存池
Netty 作为底层网络框架,为了更高效的网络传输性能,堆外内存(Direct ByteBuffer)的使用是非常高频的。
堆外内存在 JVM 之外,在有效降低 JVM GC 压力的同时,还能提高传输性能。
但它也是一把双刃剑,堆外内存是非常宝贵的资源,申请和释放都是高成本的操作,使用不当还可能造成严重的内存泄露等问题 。
性能问题:创建堆外内存的速度比堆内存慢了10到20倍
那么进行池化管理,多次重用是比较有效的方式。
为了解决这个问题Netty就做了内存池,Netty的内存池是不依赖于JVM本身的GC的。
从申请内存大小的角度讲,申请多大的 Direct ByteBuffer 进行池化又会是一大问题,太大会浪费内存,太小又会出现频繁的扩容和内存复制!!!
所以呢,就需要有一个合适的内存管理算法,解决高效分配内存的同时又解决内存碎片化的问题。
所以一个优秀的内存管理算法必不可少。
一个内存分配器至少需要看关注两个核心目标:
- 高效的内存分配和回收,提升单线程或者多线程场景下的性能
- 提高内存的有效利用率,减少内存碎片,包括内部碎片和外部碎片
可以带着以下问题去看Netty内存池源码:
- 内存池管理算法是怎么做到申请效率,怎么减少内存碎片
- 高负载下内存池不断扩展,如何做到内存回收
- 对象池是如何实现的,这个不是关键路径,可以当成黑盒处理
- 内存池跟对象池作为全局数据,在多线程环境下如何减少锁竞争
- 池化后内存的申请跟释放必然是成对出现的,那么如何做内存泄漏检测,特别是跨线程之间的申请跟释放是如何处理的。
jemalloc
jemalloc是一种优秀的内存管理算法,在这里就不展开去探究了,大家可以自行 google 百度。本文基于netty管理pooled direct memory实现进行讲解,netty对于java heap buffer的管理和对direct memory的管理在实现上基本相同
Netty 作为一款高性能的网络应用程序框架,拥有自己的内存分配。
Netty内存池的思想源于 jemalloc github ,可以说是 jemalloc 的 Java 版本。
本章源码基于 Netty 4.1.44 版本,该版本是采用 jemalloc3.x 的算法思想,而 4.1.45 以后的版本则基于 jemalloc4.x 算法进行重构,两者差别还是挺大的。
jemalloc 是由 Jason Evans 在 FreeBSD 项目中引入的新一代内存分配器。它是一个通用的 malloc 实现,侧重于减少内存碎片和提升高并发场景下内存的分配效率,其目标是能够替代 malloc。jemalloc 应用十分广泛,在 Firefox、Redis、Rust、Netty 等出名的产品或者编程语言中都有大量使用。具体细节可以参考 Jason Evans 发表的论文 [《A Scalable Concurrent malloc Implementation for FreeBSD》]。
除了 jemalloc 之外,业界还有一些著名的高性能内存分配器实现,比如 ptmalloc 和 tcmalloc。简单对比如下:
- ptmalloc(per-thread malloc) 基于 glibc 实现的内存分配器,由于是标准实现,兼容性较好。缺点是多线程之间内存无法实现共享,内存开销很大。
- tcmalloc(thread-caching malloc) 是由 Google 开源,最大特点是带有线程缓存,目前在 Chrome、Safari 等产品中有所应用。tcmalloc 为每个线程分配一个局部缓存,可以从线程局部缓冲分配小内存对象,而对于大内存分配则使用自旋锁减少内存竞争,提高内存效率。
jemalloc借鉴 tcmalloc 优秀的设计思路,所以在架构设计方面两者有很多相似之处,同样都包含线程缓存特性。但是 jemalloc 在设计上比 tcmalloc 要复杂。它将内存分配粒度划分为** Small、Large、Huge**,并记录了很多元数据,所以元数据占用空间高于 tcmalloc。
从上面了解到,他们的核心目标无外乎有两点:
- 高效的内存分配和回收,提升单线程或多线程场景下的性能。
- 减少内存碎片,包括内存碎片和外部碎片。提高内存的有效利用率。
内存碎片
在 Linux 世界,物理内存会被划分成若干个 4KB 大小的内存页(page),这是分配内存大小的最小粒度。
分配和回收都是基于 page 完成的。page 内产生的碎片称为 内存碎片,page 外产生的碎片称为 外部碎片。
内存碎片产生的原因是内存被分割成很小的块,虽然这些块是空闲且地址连续的,但却小到无法使用。
随着内存的分配和释放次数的增加,内存将变得越来越不连续。
最后,整个内存将只剩下碎片,即便有足够的空闲页框可以满足请求,但要分配一个大块的连续页框就无法满足,所以减少内存浪费的核心就是尽量避免产生内存碎片。
常见的内存分配器算法
常见的内存分配器算法有:
- 动态内存分配
- 伙伴算法
- Slab算法
动态内存分配
全称 Dynamic memory allocation,又称为 堆内存分配,简单 DMA。简单地说就是想要多少内存空间,操作系统就给你多少。在大部分场景下,只有在程序运行时才知道所需内存空间大小,提前分配的内存大小空间不好把控,分配太多造成空间浪费,分配太少造成程序崩溃。
DMA 就是从一整块内存中 按需分配,对于已分配的内存会记录元数据,同时还会使用空闲分区维护空闲内存,便于在下次分配时快速查找可用的空闲分区。常见的有以下三种查找策略:
首次适应算法(first fit)
- 空闲分区按内存地址从低到高的顺序以双向链表形式连接在一起。
- 内存分配每次从低地址开始查找并分配。因此造成低地址使用率较高而高地址使用率很低。同时会产生较多的小内存。
循环首次适应算法(next fit)
- 该算法是 首次适应算法 的变种,主要变化是第二次的分配是从下一个空闲分区开始查找。
- 对于 首次适应算法 ,该算法将内存分配得更加均匀,查找效率有所提升,但是这会导致严重的内存碎片。
最佳适应算法(best fit)
- 空间分区链始终保持从小到大的递增顺序。当内存分配时,从开头开始查找适合的空间内存并分配,当完成分配请求后,空闲分区链重新按分区大小排序。
- 此算法的空间利用率更高,但同样会有难以利用的小空间分区,究其原因是空闲内存块大小不变,并没有针对内存大小做优化分类,除非内存内存大小刚好等于空闲内存块的大小,空间利用率 100%。
- 每次分配完后需要重新排序,因此存在 CPU 消耗。
伙伴算法(Buddy memory allocation)
伙伴内存分配技术是一种内存分配算法,它将内存划分为分区,以最合适的大小满足内存请求。
于 1963 年 Harry Markowitz 发明。
伙伴算法把所有的空闲页框分组成 11 个块链表,每一个块链表分别包含大小为1、2、4、8、16、32、64、128、256、512 和 1024 个连续的页框。
最大内存请求大小为 4MB,该内存是连续的。
- 伙伴算法即大小相同、地址连续。
缺点: 虽然伙伴算法有效减少了外部碎片,但最小粒度还是 page,因此有可能造成非常严重的内部碎片,最严重带来 50% 的内存碎片。
Slab 算法
伙伴 算法 在小内存场景下并不适用,因为每次都会分配一个 page,导致非常严重的内部碎片。
而 Slab 算法 则是在 伙伴算法 的基础上对小内存分配场景做了专门的优化:
提供调整缓存机制存储内核对象,当内核需要再次分配内存时,基本上可以通过缓存中获取。
Linux 底层采用 Slab 算法 进行内存分配。
jemalloc 算法
jemalloc 是基于 Slab 而来,比 Slab 更加复杂。
Slab 提升小内存分配场景下的速度和效率,jemalloc 通过 Arena 和 Thread Cache 在多线程场景下也有出色的内存分配效率。
Arena 是分而治之思想的体现,与其让一个人管理全部内存,到不如将任务派发给多个人,每个人独立管理,互不干涉(线程竞争)。
Thread Cache 是 tcmalloc 的核心思想,jemalloc 也把它借鉴过来。
通过Thread Cache机制, 每个线程有自己的内存管理器,分配在这个线程内完成,就不需要和其他线程竞争。
相关文档
- Facebook Engineering post: This article was written in 2011 and corresponds to jemalloc 2.1.0.
- jemalloc(3) manual page: The manual page for the latest release fully describes the API and options supported by jemalloc, and includes a brief summary of its internals.
Netty 底层的内存分配是采用 jemalloc 算法思想。
内存规格
Netty 对内存大小划分为:Tiny、Small、Normal 和 Huge 四类。
Huge 类型
Netty 默认向操作系统申请的内存大小为 16MB,对于大于 16MB 的内存定义为 Huge 类型,
Netty 对 Huge 类型的处理方式为:
大型内存不做缓存、不做池化,直接以 Unpool 的形式分配内存,用完后回收。
Tiny、Small、Normal类型
对于 16MB 及更小的内存,分类为:Tiny、Small、Normal,也有对应的枚举 SizeClass 进行描述。
// io.netty.buffer.PoolArena.SizeClass
enum SizeClass
Tiny,
Small,
Normal

不过 Netty 定义了一套更细粒度的内存分配单位:Chunk、Page、Subpage,方便内存的管理。
注意:为了方便管理, Netty 在每个区域内又定义了更细粒度的内存分配单位,分别是 Chunk、Page 和 Subpage。
Chunk
Chunk 即上述提及的 Netty 向操作系统申请内存的单位,默认是 16MB。后续所有的内存分配也都是基于 Chunk 完成。
Chunk 是 Page 的集合。
一个 Chunk(16MB),由 2048 个 Page (8KB)组成。
netty 内存向系统或者JVM堆申请是大块的内存,单位是chunk块, 不是一点一点申请,而是一大块一大块的申请,然后再内部高效率的二次分配
一个chunk 的大小是16MB, 实际上每个chunk, 都以双向链表的形式保存在一个chunkList 中,
而多个chunkList, 同样也是双向链表进行关联的, 大概结构如下所示:

这样, 在内存分配时, chunkList 中, 是根据chunk 的内存使用率归到一个chunkList 中,
会根据百分比找到相应的chunkList, 在chunkList 中选择一个chunk 进行内存分配。
Page
Page 是 Chunk 用于管理内存的基本单位。
Page 的默认大小为 8KB,若欲申请 16KB,则需申请连续的两块空闲 Page。

SubPage
很多场景下, 为缓冲区分配8KB 的内存也是一种浪费, 比如只需要分配2KB 的缓冲区, 如果使用8KB 会造成6KB 的浪费,
这种情况, netty 又会将page 切分成多个subpage,
SubPage 是 Page 下的管理单位。
每个subpage 大小要根据分配的缓冲区大小而指定, 比如要分配2KB 的内存, 就会将一个page 切分成4 个subpage, 每个subpage 的大小为2KB, 如下图:

对于底层应用,KB 级的内存已属于大内存的范畴,更多的是 B 级的小内存,直接使用Page 进行内存的分配,无疑是非常浪费的。
所以对 Page 进行了切割划分,划分后的便是 SubPage,Tiny 和 Small 类型的内存使用的分配单位都是 SubPage。
切割划分的算法原则是:
如首次申请 512 B 的内存,则先申请一块 Page 内存,然后将 8 KB 的 Page 按照 512B 均分为 16 块,每一块可以认为是一个 SubPage,然后将第一块 SubPage 内存地址返回给申请方。
同时下一次申请 512B 内存,则在 16 块中分配第二块。
其他非 512B 的内存申请,则另外申请一个 Page 进行均等切分和分配。
所以,对于 SubPage 没有固定的大小,和 Tiny、Small 中某个具体大小的内存申请有关。
问题:为什么只有上面穷举出来的内存大小,没有19B、21B、3KB这样规格?
是因为 netty 中会把申请内存大小进行了标准化,向上取整到最接近的上图中所列举出的大小,以便于管理。
内存规格化
Netty 需要对用户申请的内存大小进行 规格化 处理,目的是方便后续计算和内存分配。
通过内存规格化,将 31B 规格化为 32B,将 15MB 规格化 16MB。
Netty 和内存规格化涉及三个核心算法:
- 一是找到离分配内存最近且大于分配内存的 2 值。获取最接近 2^n 的数
- 二是找到离分配内存最近且大于分配内存的16 倍的值。
- 三是通过掩码判断是否大于某个数。
获取最接近 2^n 的数(非常重要的算法)
对于small和normal ,规格化成获取最接近 2^n 的数,便于计算和管理。
注意:Netty 通过大量的位运算来提升性能,但代码的可读性不太好。
下面的算法,获取最接近 2^n 的数(非常重要的算法),jvm源码里边都用到了。



上面一连串的位移计算,看得眼花缭乱。
这个算法的核心:是找到最接近 2的幂 且 大于用户申请规模的值。这个算法很重要,很多核心源码用到。
这个算法的思路: 把二进制 0100 0000 0001(1025) 变成 0111 1111 1111 +1 (2048)。
记初始值为 i,原始值的二进制最高位为 1 的序号记为 n,具体执行过程描述如下:
-
先执行 i-1 操作,目的是解决当值为 2时也能得到本身,而非 2。
-
再执行 i |= i>>>1 运算,目的是赋值第 n-1 位的值为 1。
假设为1的最高位n,也就是第 n 位位置确定为 1,那么无符号右移一位后第 n-1 也为 1。
再与原值进行 | 运算后更新第 n-1 的值。
此时,原值的第 n、n-1 都确定为 1,那么接下来就可以无符号右移两倍,让n-2、n-3 赋值为 1。
由于 int 类型有 32 位,所以只需要进行 5 次运算,每次分别无符号右移1、2、4、8、16 就可让小于 i 的所有位都赋值为 1。
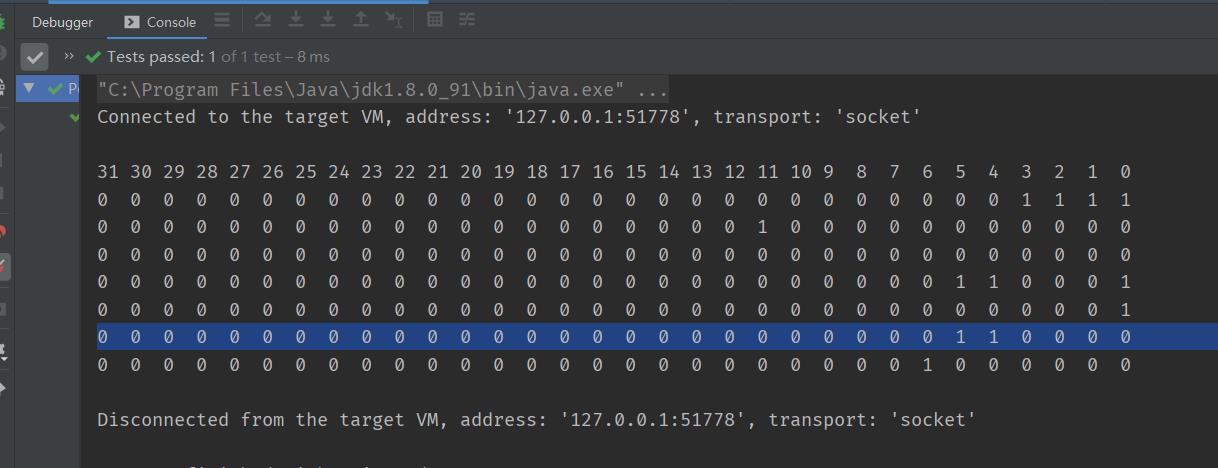
测试用例:获取最接近 2^n 的数
由于源码可读性太差,代码的可读性不太好。特意写了用例




完整演示与介绍,请参考40岁老架构师尼恩的视频:《彻底穿透netty架构与源码》
获取最近的下一个16的倍数值
对于tiny类型,规格化其实思路很简单:
先把低四位的值抹去(变成0),再加上
16就得到了目标值。

测试用例执行结果
完整演示与介绍,请参考40岁老架构师尼恩的视频:《彻底穿透netty架构与源码》
Netty 内存池分配整体思路
设计思路
Netty采用了jemalloc的思想,这是FreeBSD实现的一种并发malloc的算法。
jemalloc依赖多个Arena来分配内存,运行中的应用都有固定数量的多个Arena,默认的数量与处理器的个数有关。
系统中有多个Arena的原因是由于各个线程进行内存分配时竞争不可避免,这可能会极大的影响内存分配的效率,为了缓解高并发时的线程竞争,Netty允许使用者创建多个分配器(Arena)来分离锁,提高内存分配效率。
线程首次分配/回收内存时,首先会为其分配一个固定的Arena。
线程选择Arena时使用round-robin的方式,也就是顺序轮流选取。
每个线程各种保存Arena和缓存池信息,这样可以减少竞争并提高访问效率。
Arena将内存分为很多Chunk进行管理,Chunk内部保存Page,以页为单位申请。
下图展示了netty基于jemalloc实现的内存划分逻辑

内存池结构
Netty中将内存池分为五种不同的形态从大到小依次是:
-
PoolArena,
-
PoolChunkList,
-
PoolChunk,
-
PoolPage,
-
PoolSubPage.
首先,Netty 会向 操作系统 申请一整块 **连续内存,**称为 chunk(数据块),除非申请 Huge 级别大小的内存,
否则一般大小为 16MB,使用 io.netty.buffer.PoolChunk 对象包装。
具体长这样子:

Netty将chunk进一步拆分为多个page,每个 page 默认大小为 8KB,
因此每个 chunk 包含 2048 个 page。为了对小内存进行精细化管理,减少内存碎片,提高内存使用率,
Netty 对 page 进一步拆分若干 subpage,subpage 的大小是动态变化的,最小为 16Byte。
- 计算: 当请求内存分配时,将所需要内存大小进行内存规格化,获得规格化的内存请求值。根据值确认准确的树的高度。
- 搜索: 在内存映射数据中,进行空闲内存序列的搜索。
- 标记: 分组被标记为全部已使用,且通过循环更新其父节点标记信息。父节点的标记值取两个子节点标记值的最小的一个。
当然,上面说的只是整体思路。还要分类型进行细化。
Huge 分配逻辑概述
Normal 级别分配的大小范围是 [16M, 无限大) 。
大内存分配比其他类型的内存分配稍微简单一点,操作的内存单元是 PoolChunk,它的容量大小是用户申请的容量(可满足内存对齐要求)。
Netty 对 Huge 对象的内存块采用非池化管理策略,在每次请求分配内存时单独创建特殊的非池化 PoolChunk 对象,当对象内存释放时整个 PoolChunk 内存也会被释放。
大内存的分配逻辑是在 io.netty.buffer.PoolArena#allocateHuge 完成。
Normal 分配逻辑
Normal 级别分配的大小范围是 [4097B, 16M) 。
核心思想是将 PoolChunk 拆分成 2048 个 page ,这是 Normal 分配的最小单位。
每个 page 等大(pageSize=8KB),并在逻辑上通过一棵满二叉树管理这些 page 对象。
我们申请的内存本质是组合若干个 page 。Normal 的分配核心逻辑是在 PoolChunk#allocateRun(int) 完成。
Small 分配逻辑
Small 级别分配的大小范围是 (496B, 4096B] 。
核心是把一个 page 拆分若干个 Subpage,PoolSubpage 就是这些若干个 Subpage 的化身,有效解决小内存场景造成内存碎片的问题。
一个 page 大小为 8192B,有且只有四种大小: 512B、1024B、2048B 和 4096B,以 2 倍递增。
当申请的内存大小在 496B~4096B 范围内时,就能确定这四种中的一种。
当进行内存分配时,先在树的最底层找到一个空闲的 page,拆分成若干个 subpage,并构造一个 PoolSubpage 进行管理。
选择第一个 subpage 用于此次申请,标记为已使用,并将 PoolSubpage 放置在 PoolSubpage[] smallSubpagePools 数组所对应的链表中。
等下次申请等大容量内存时就可从 PoolSubpage[] 直接分配从链表中分配内存。
Tiny 分配逻辑
Tiny 级别分配的大小范围是 (0B, 496B] 。
分配逻辑与 Small 类似,
先找到空闲的 Page 然后将其拆分若干个 Subpage 并构造一个 PoolSubpage 对它们进行管理。
随后选择第一个 subpage 用于此次申请,并将对象 PoolSubpage 放置在 PoolSubpage[] tinySubpagePools 数组所对应的链表中。等待下次分配时使用。
区别在于如何定义若干个?
Tiny 给出的定义逻辑是获取最接近 16*N 的且大于规格值的大小。
比如申请内存大小为 31B,找到最接近的下一个 16*1 的倍数且大于 31 的值是 32,
因此,就把 Page 拆分成 8192/32=256 个 subpage,这里的若干个就是根据规格值确定的,它是可变的值。
PoolArena
上面讲述了针对不同级别 Netty 是如何完成内存分配的。
arena是jemalloc中的概念,它是一个内存管理单元,线程在arena中去分配和释放内存,
PoolArena的高并发设计
为了减少线程成间的竞争,很自然会提供多个PoolArena。
和G1垃圾回收器、Redis分段锁一样,这里用了分治模式,
系统正常会存在多个arena,每个线程会被绑定一个arena,PoolArena是线程共享的对象,每个线程只会绑定一个 PoolArena,线程和 PoolArena 是多对一的关系。
同一个arena可以被多个线程共享,arena和thread之间的关系如下图

PoolArena 是进行池化内存分配的核心类,采用固定数量的多个 Arena 进行内存分配,默认与 CPU 核心数量有关,
当某个线程首次申请内存分配时,会通过轮询(Round-Robin) 方式得到一个 PoolArena,在该线程的整个生命周期内只和这个 Arena 打交道,
PoolArena 是分治思想的体现,其目标是,解决在多线程场景下的高并发问题。
PoolArena的核心成员
PoolArena 提供 DirectArena 和 HeapArena 子类,这是因为底层容器类型不同所以需要子类区分。但核心逻辑是在 PoolArena 完成的。
PoolArena 的数据结构大致(除去监测指标数据)可分为两大类:
-
存储 PoolChunk 的 6 个 PoolChunkList
-
存储 PoolSubpage 的 2 个数组。
PoolArena 构造器初始化也做了很多重要的工作,包含串联 PoolChunkList 以及初始化 PoolSubpage[] 。
存储 PoolChunk 的 6 个 PoolChunkList

q000、q025、q050、q075、q100 表示最低内存使用率。如下图所示

任意 PoolChunkList 都有内存使用率的上下限:
-
minUsag
-
maxUsage。
如果使用率超过 maxUsage,那么 PoolChunk 会从当前 PoolChunkList 移除,并移动到下一个PoolChunkList 。
同理,如果使用率小于 minUsage,那么 PoolChunk 会从当前 PoolChunkList 移除,并移动到前一个PoolChunkList。
每个 PoolChunkList 的上下限都有交叉重叠的部分,为什么呢?
因为 PoolChunk 需要在 PoolChunkList 不断移动,如果临界值恰好衔接的,则会导致 PoolChunk 在两个 PoolChunkList 不断移动,造成性能损耗。
PoolChunkList 适用于 Chunk 场景下的内存分配,PoolArena 初始化 6 个 PoolChunkList 并按上图首尾相连,形成双向链表,但是, q000 这个 PoolChunkList 是没有前向节点
q000 这个 PoolChunkList 是没有前向节点,为什么呢?
因为当其余 PoolChunkList 没有合适的 PoolChunk 可以分配内存时,会创建一个新的 PoolChunk 放入 pInit 中,然后根据用户申请内存大小分配内存。
而在 p000 中的 PoolChunk ,如果因为内存归还的原因,使用率下降到 0%,则不需要放入 pInit,而是直接执行销毁方法,将整个内存块的内存释放掉。
这样,内存池中的内存就有生成/销毁等完成生命周期流程,避免了在没有使用情况下还占用内存。
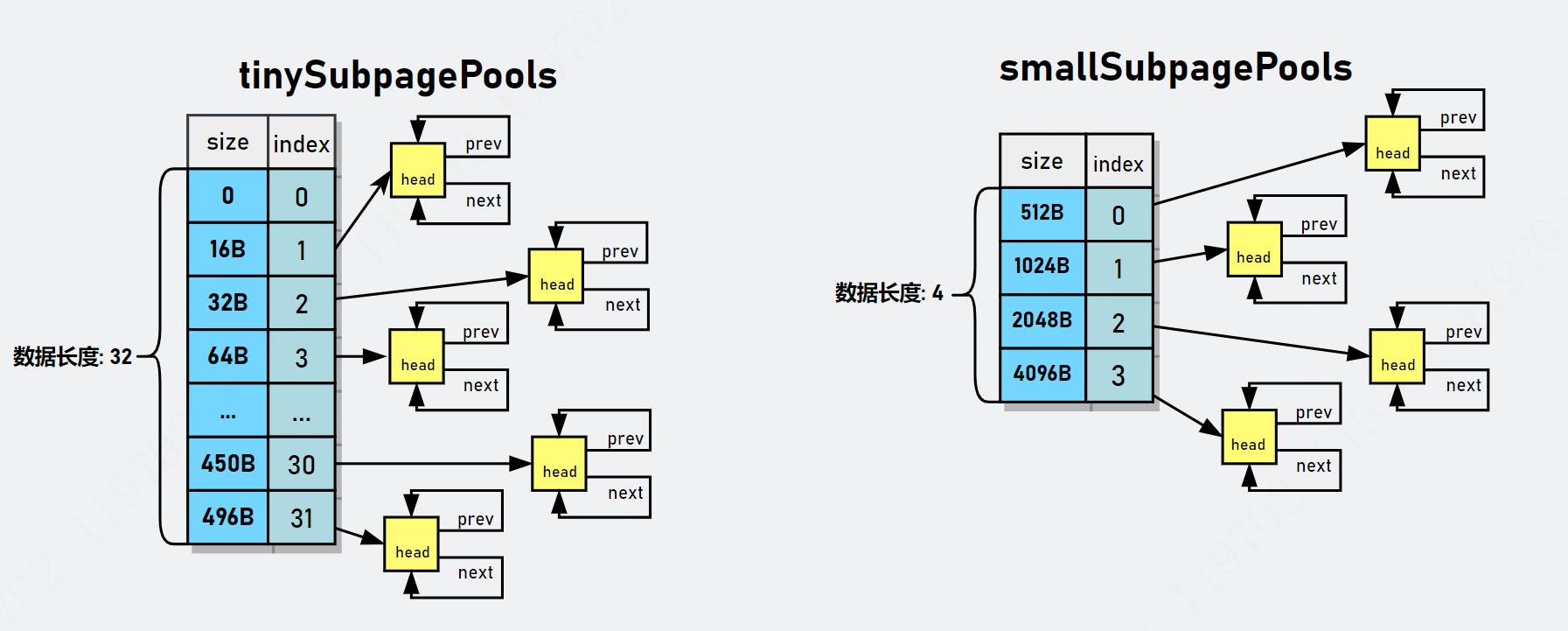
存储 PoolSubpage 的 2 个数组
PoolSubpage 是对某一个 page 的化身,page毕竟太粗,
如果申请1Byte的空间就分配一个页是不是太浪费空间,对,这确实很浪费,
在Netty中Page还会被细化为subpage,
用于专门处理小于8k的空间申请,那是subpage。

于是, Page 还可以按 elemSize 拆分成若干个 subpage,
在 PoolArena 使用 PoolSubpage[] 数组来存储 PoolSubpage 对象,
两个PoolSubpage[] 数组如下图所示:
smallSupbagePools 数组
对于 Small类型的subpage, 它拥有四种不同大小的规格,因此 smallSupbagePools 的数组长度为 4,
smallSubpagePools[0] 表示 elemSize=512B 的 PoolSubpage 对象的链表,
smallSubpagePols[1] 表示 elemSize=1024B 的 PoolSubpages 对象的链表。
smallSubpagePols[2] 表示 elemSize=2048B 的 PoolSubpages 对象的链表。
smallSubpagePols[3] 表示 elemSize=4096B 的 PoolSubpages 对象的链表。
tinySubpagePools 数组
tinySubpagePools 原理一样,只不过划分的粒度(步长)比较小,
tinySubpagePools 数组的元素划分,不是以2的幂的步长划分的,而是以倍数来的,以 16 的倍数递增。
从16B-496B,总共可分为 32 类,因此 tinySubpagePools 数组长度为 32。
PoolSubpage[] 数组与HashMap的对比
这两个PoolSubpage[] 数组用来存储 PoolSubpage 对象且按 PoolSubpage#elemSize 确定索引的位置 index,最后将它们构造双向链表。
每个PoolSubpage[] 数组都对应一组双向链表。
每个PoolSubpage[] 数组下标所对应的 size 容量不一样,按 PoolSubpage#elemSize 确定索引的位置 index
PoolSubpage数组的结构,非常类似于一个简单的HashMap,简单的HashMap集合的三个基本存储概念
| 名称 | 说明 |
|---|---|
| table | 存储所有节点数据的数组 |
| slot | 哈希槽。即table[i]这个位置 |
| bucket | 哈希桶。table[i]上所有元素形成的表或数的集合 |

PoolSubpage#elemSize 可以理解为hashmap的key,这是这里不进行hash运算,而是根据elemSize 的规模去确定 slot 槽位
PoolSubpage[] 的一个元素PoolSubpage,可以理解为hashmap的bucket,这是这里不链表,而是双向链表
PoolArena的具体实现
PoolArena是功能的门面,通过PoolArena提供接口供上层使用,屏蔽底层实现细节。
Netty默认会生成2×CPU个PoolArena跟IO线程数一致。
然后第一次使用的时候会找一个使用线程最少的PoolArena
private <T> PoolArena<T> leastUsedArena(PoolArena<T>[] arenas)
if (arenas == null || arenas.length == 0)
return null;
PoolArena<T> minArena = arenas[0];
for (int i = 1; i < arenas.length; i++)
PoolArena<T> arena = arenas[i];
if (arena.numThreadCaches.get() < minArena.numThreadCaches.get())
minArena = arena;
return minArena;
现在我们看下PoolArena的属性,比较多,
//maxOrder默认是11
private final int maxOrder;
//内存页的大小,默认是8k
final int pageSize;
//默认是13,表示的是8192等于2的13次方
final int pageShifts;
// 默认是16M
final int chunkSize;
//这个等于~(pageSize-1),用于判断申请的内存是不是大于或者等于一个page
//申请内存reqCapacity&subpageOverflowMask如果等于0那么表示申请的内
//存小于一个page的大小,如果不等于0那么表示申请的内存大于或者一个page的大小
final int subpageOverflowMask;
//它等于pageShift - 9,默认等4
final int numSmallSubpagePools;
final int directMemoryCacheAlignment;
final int directMemoryCacheAlignmentMask;
//tiny类型内存PoolSubpage数组,数组长度是32,从index=1开始使用
private final PoolSubpage<T>[] tinySubpagePools;
//small类型内存PoolSubpage数组,数组长度在默认情况下是4
private final PoolSubpage<T>[] smallSubpagePools;
//PoolChunkList代表链表中的节点,
//每个PoolChunkList存放内存使用量在相同范围内的chunks,
//比如q075存放的是使用量达到了75%以上的chunk
private final PoolChunkList<T> q050;
private final PoolChunkList<T> q025;
private final PoolChunkList<T> q000;
private final PoolChunkList<T> qInit;
private final PoolChunkList<T> q075;
private final PoolChunkList<T> q100;
private final List<PoolChunkListMetric> chunkListMetrics;
//下面都是一些记录性质的属性
// Metrics for allocations and deallocations
private long allocationsNormal;
// We need to use the LongCounter here as this is not guarded via synchronized block.
private final LongCounter allocationsTiny = PlatformDependent.newLongCounter();
private final LongCounter allocationsSmall = PlatformDependent.newLongCounter();
private final LongCounter allocationsHuge = PlatformDependent.newLongCounter();
private final LongCounter activeBytesHuge = PlatformDependent.newLongCounter();
private long deallocationsTiny;
private long deallocationsSmall;
private long deallocationsNormal;
// We need to use the LongCounter here as this is not guarded via synchronized block.
private final LongCounter deallocationsHuge = PlatformDependent.newLongCounter();
// Number of thread caches backed by this arena.
final AtomicInteger numThreadCaches = new AtomicInteger();
是由多个PoolChunkList和两个SubPagePools(一个是tinySubPagePool,一个是smallSubPagePool)组成的。
看下tinySubpagePools和smallSubpagePools数组的初始化, 以tinySubpagePools为例

private PoolSubpage<T>[] newSubpagePoolArray(int size)
return new PoolSubpage[size];
构造一个 newSubpagePoolArray方法中,创建了一个PoolSubpage 对象数组,里边没有初始化任何元素
接下来,是初始化每一个元素,或者说,初始化每一个slot槽位,
具体的做法是:每一个槽位构造出一个头部对象,类型为 PoolSubpage
private PoolSubpage<T> newSubpagePoolHead(int pageSize)
PoolSubpage<T> head = new PoolSubpage<T>(pageSize);
head.prev = head;
head.next = head;
return head;
PoolSubpage是双向链表节点型的对象,默认head和next都指向自己
所以初始化后的SubpagePools长这样

看下smallSubpagePools数组的初始化, 和tinySubpagePools类似,只是数组的大小不同

Netty的池化内存分配流程
在深入PoolSubpage之前,有必要先说下netty的内存分配流程实现。
netty向jvm或者堆外内存每次申请的内存以chunk为基本单位,
每个chunk的默认大小是16M,在netty内部每个chunk又被分成若干个page,默认情况下每个page的大小为8k,所以在默认情况下一个chunk包含2048个page

应用程序向netty申请内存的时候分成两四情况:
1)如果申请的内存大于一个chunk的尺寸,规模为huge,那么netty就会直接向JVM或者操作系统申请相应大小的内存。
2)如果申请的内存小于chunk的尺寸,但是规模为normal,默认情况下也就是小于16M,那么netty就会以page为单位去分配一个run系列的page给应用程序
比如申请10K的内存,那么netty会选择一个chunk中的2个page分配给应用程序,
如果申请的内存小于一个page的大小,那么就直接分配一个page给应用程序
3)如果申请的内存小于normal的尺寸,但是规模为small,则先去 smallSubpagePools 中查找,如果没有,则找一个page劈成n个同等规模的Subpage,然后进行分配,剩余的Subpage插入smallSubpagePools 具体的slot中。
4)如果申请的内存小于normal的尺寸,但是规模为tiny,则先去 tinySubpagePools 中查找,如果没有,则找一个page劈成n个同等规格的Subpage,然后进行分配,剩余的Subpage插入tinySubpagePools 具体的slot中。
第2、3、4步中,如果没有空闲的page,则申请一个chunk,分配成page后,再申请一个page
PooledByteBufAllocator
用户程序申请内存通过PooledByteBufAllocator类提供的buffer去操作,下面是这个类定义的属性
//heap类型arena的个数,数量计算方法同下
private static final int DEFAULT_NUM_HEAP_ARENA;
//direct类型arena个数,默认为min(cpu_processors * 2,maxDirectMemory/16M/2/3),正
//常情况下如果不设置很小的Xmx或者很小的-XX:MaxDirectMemorySize,
//arena的数量就等于计算机processor个数的2倍,
private static final int DEFAULT_NUM_DIRECT_ARENA;
//内存页的大小,默认为8k(这个内存页可以类比操作系统内存管理中的内存页)
private static final int DEFAULT_PAGE_SIZE;’
//默认是11,因为一个chunk默认是16M = 2^11 * 2^13(8192)
private static final int DEFAULT_MAX_ORDER; // 8192 << 11 = 16 MiB per chunk
//缓存tiny类型的内存的个数,默认是512
private static final int DEFAULT_TINY_CACHE_SIZE;
//缓存small类型的内存的个数,默认是256
private static final int DEFAULT_SMALL_CACHE_SIZE;
//缓存normal类型的内存的个数,默认是64
private static final int DEFAULT_NORMAL_CACHE_SIZE;
//最大可以被缓存的内存值,默认为32K,当申请的内存超过32K,那么这块内存就不会被放入缓存池了
private static final int DEFAULT_MAX_CACHED_BUFFER_CAPACITY;
//cache经过多少次回收之后,被清理一次,默认是8192
private static final int DEFAULT_CACHE_TRIM_INTERVAL;
private static final long DEFAULT_CACHE_TRIM_INTERVAL_MILLIS;
//是不是所有的线程都是要cache,默认true,
private static final boolean DEFAULT_USE_CACHE_FOR_ALL_THREADS;
private static final int DEFAULT_DIRECT_MEMORY_CACHE_ALIGNMENT;
// Use 1023 by default as we use an ArrayDeque as backing storage which will then allocate an internal array
// of 1024 elements. Otherwise we would allocate 2048 and only use 1024 which is wasteful.
static final int DEFAULT_MAX_CACHED_BYTEBUFFERS_PER_CHUNK;
//-------------------------------------------下半部分的属性---------------------------------------
//heap类型的arena数组
private final PoolArena<byte[]>[] heapArenas;
//direct memory 类型的arena数组
private final PoolArena<ByteBuffer>[] directArenas;
//对应上面的DEFAULT_TINY_CACHE_SIZE;
private final int tinyCacheSize;
private final int smallCacheSize;
private final int normalCacheSize;
private final List<PoolArenaMetric> heapArenaMetrics;
private final List<PoolArenaMetric> directArenaMetrics;
//这是个FastThreadLocal,记录是每个线程自己的内存缓存信息
private final PoolThreadLocalCache threadCache;
//每个PageChunk代表的内存大小,默认是16M,这个可以类比操作系统内存管理中段的概念
private 查看详情
秒懂:jctool的mpsc高性能无锁队列(史上最全+10w字长文)(代码片段)
文章很长,而且持续更新,建议收藏起来,慢慢读!疯狂创客圈总目录博客园版为您奉上珍贵的学习资源:免费赠送:《尼恩Java面试宝典》持续更新+史上最全+面试必备2000页+面试必备+大厂必备+... 查看详情
史上最全的opencv入门教程!这篇够你学习半个月了!万字长文入门(代码片段)
一、PythonOpenCV入门欢迎阅读系列教程,内容涵盖OpenCV,它是一个图像和视频处理库,包含C++,C,Python和Java的绑定。OpenCV用于各种图像和视频分析,如面部识别和检测,车牌阅读,照片编辑,高级机器人视觉,光学字符识别等等... 查看详情
面试难题:netty如何解决selector空轮询bug?(图解+秒懂+史上最全)(代码片段)
文章很长,建议收藏起来,慢慢读!Java高并发发烧友社群:疯狂创客圈奉上以下珍贵的学习资源:免费赠送经典图书:《Java高并发核心编程(卷1)》面试必备+大厂必备+涨薪必备加尼恩免费领免... 查看详情
两万字长文,史上最全c++年度总结!
...力。本文的四位作者联合撰文,写下了这篇两万字的长文,深度总结了C++的新进展,以及未来的演进方向& 查看详情
两万字长文,史上最全c++年度总结!
...力。本文的四位作者联合撰文,写下了这篇两万字的长文,深度总结了C++的新进展,以及未来的演进方向& 查看详情
netty源码之内存池(代码片段)
目录一、DirectBuffer和HeapBuffer对外直接内存缓冲堆内存缓冲IO二、Netty的池化池化的好处netty的缓冲池使用1、池化Buffer2、非池化Buffer三、内存分配1、PooledDirectByteBuf对象池的使用2、回收池Recycler原理3、堆外内存的分配四、apache的对... 查看详情
jvm逃逸分析(史上最全)(代码片段)
...DF文件,请从下面的链接获取:语雀或者码云JVM的内存分配策略-首先回顾一下JVM的内存分配策略。JVM的内存包 查看详情
史上最全面的线程池介绍
敬请期待https://gitbook.cn/gitchat/activity/5b4731ca260b1f16129ecb0f 查看详情
bytebuddy(史上最全)(代码片段)
ByteBuddy(史上最全)文章很长,建议收藏起来慢慢读!总目录博客园版为大家准备了更多的好文章!!!!推荐:尼恩Java面试宝典(持续更新+史上最全+面试必备)具体详情,... 查看详情
bytebuddy(史上最全)(代码片段)
ByteBuddy(史上最全)文章很长,建议收藏起来慢慢读!总目录博客园版为大家准备了更多的好文章!!!!推荐:尼恩Java面试宝典(持续更新+史上最全+面试必备)具体详情,... 查看详情
应聘阿里,字节跳动美团90%会问到的jvm面试题!史上最全系列!(代码片段)
Java内存分配?寄存器:程序计数器,是线程私有的,就是一个指针,指向方法区中的方法字节码。?静态域:static定义的静态成员。?常量池:编译时被确定并保存在.class文件中的(final)常量值和一些文本修饰的符号引用(类和接... 查看详情
netty源码之内存池(代码片段)
目录一、DirectBuffer和HeapBuffer对外直接内存缓冲堆内存缓冲IO二、Netty的池化池化的好处netty的缓冲池使用1、池化Buffer2、非池化Buffer三、内存分配1、PooledDirectByteBuf对象池的使用2、回收池Recycler原理3、堆外内存的分配四、apache的对... 查看详情
netty源码之内存池(代码片段)
目录一、DirectBuffer和HeapBuffer对外直接内存缓冲堆内存缓冲IO二、Netty的池化池化的好处netty的缓冲池使用1、池化Buffer2、非池化Buffer三、内存分配1、PooledDirectByteBuf对象池的使用2、回收池Recycler原理3、堆外内存的分配四、apache的对... 查看详情
netty源码之内存池(代码片段)
目录一、DirectBuffer和HeapBuffer对外直接内存缓冲堆内存缓冲IO二、Netty的池化池化的好处netty的缓冲池使用1、池化Buffer2、非池化Buffer三、内存分配1、PooledDirectByteBuf对象池的使用2、回收池Recycler原理3、堆外内存的分配四、apache的对... 查看详情
javascript代码技巧——史上最全类型判断(代码片段)
1.typeof(不能区分复杂类型)console.log(typeofbool);//booleanconsole.log(typeofnum);//numberconsole.log(typeofstr);//stringconsole.log(typeofund);//undefinedconsole.log(typeofnul);//objectconsole. 查看详情
javascript代码技巧——史上最全类型判断(代码片段)
1.typeof(不能区分复杂类型)console.log(typeofbool);//booleanconsole.log(typeofnum);//numberconsole.log(typeofstr);//stringconsole.log(typeofund);//undefinedconsole.log(typeofnul);//objectconsole. 查看详情
prometheus+grafana(史上最全)(代码片段)
...#xff08;elasticsearch+logstash+kibana)原理和实操(史上最全)高级开发必备,架构师必备一键打造本地Prometheus+Grafana实操环境:Prometheus+Grafana 查看详情