关键词:
今年3月份在公司的内部k8s培训会上,开发同事对应用整合进pod提出了几个问题,主要围绕在java应用的日志统一收集、集中存放和java jvm内存监控数据收集相关的点上,本文将介绍使用filebeat实现pod日志的统一收集,集中存放使用集群外的elasticsearch,后续可以加上kibana及模板文件实现更友好的数据展示。
一、准备和测试tomcat基础镜像
该镜像主要是配置jdk环境变量和tomcat软件包部署,如果有特殊的需求,例如安装其他软件包、配置tomcat https等也可以在dockerfile里面实现。之后如果有对jdk和tomcat进行统一升级,更新基础镜像即可。
1、dockerfile编译镜像并推送到本地仓库
# docker pull centos
# cd tomcat/
# ls
# cat dockerfile
FROM centos
MAINTAINER yangliangwei "[email protected]"
WORKDIR /home
COPY java1.8.tgz /home/
RUN tar zxf /home/java1.8.tgz -C /usr/local/ && rm -rf /home/java1.8.tgz
ENV JAVA_HOME /usr/local/java/
ENV CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
ENV PATH $PATH:$JAVA_HOME/bin
COPY apache-tomcat-7.0.86.tar.gz /home/
RUN tar zxf apache-tomcat-7.0.86.tar.gz -C /home && rm -rf /home/apache-tomcat-7.0.86.zip
RUN mv /home/apache-tomcat-7.0.86 /home/tomcat
EXPOSE 8080
ENTRYPOINT /home/tomcat/bin/startup.sh && tail -f /home/tomcat/logs/catalina.out# docker build -t tomcat_base:v1.0 .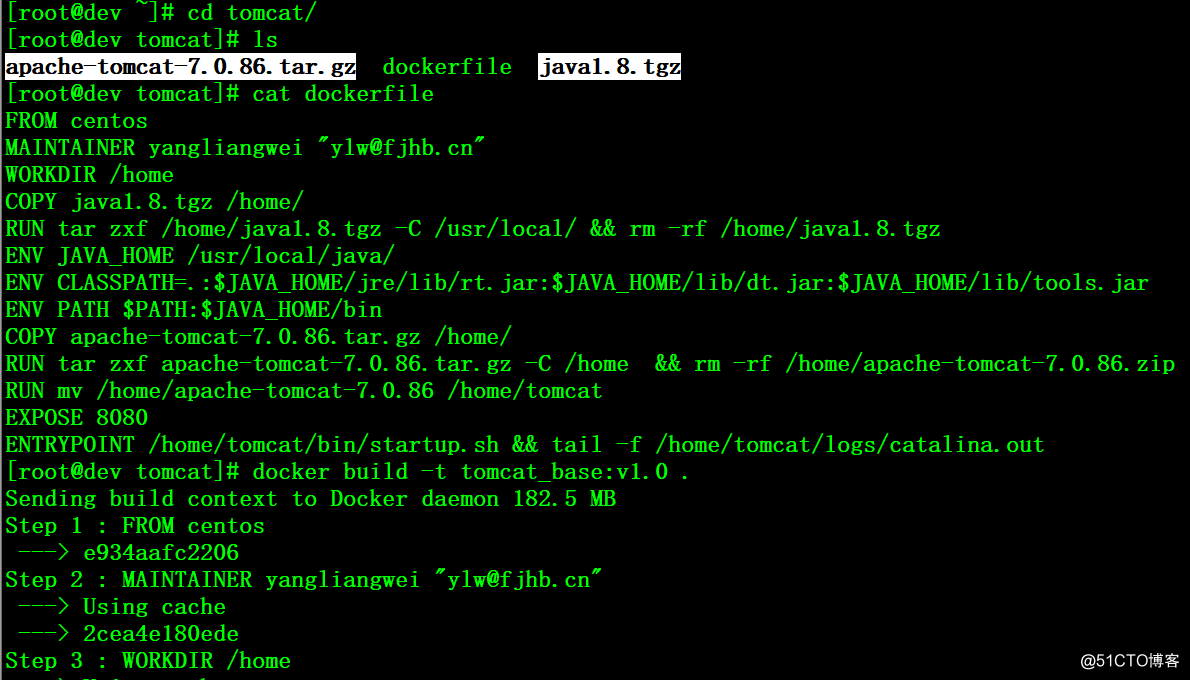
# docker tag tomcat_base:v1.0 registry.59iedu.com
# docker push registry.59iedu.com/tomcat_base:v1.0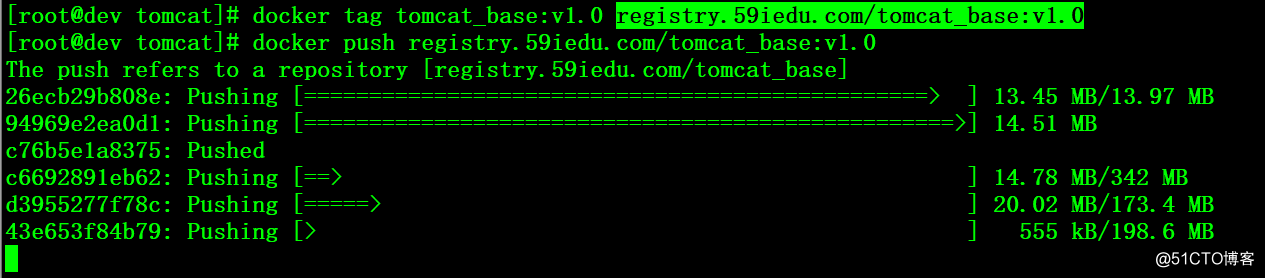
2、其他docker主机通过本地仓库下载镜像run测试
# docker pull registry.59iedu.com/tomcat_base:v1.0
# docker run -idt --name tomcat_test -p 8889:8080 registry.59iedu.com/tomcat_base:v1.0
# curl http://localhost:8889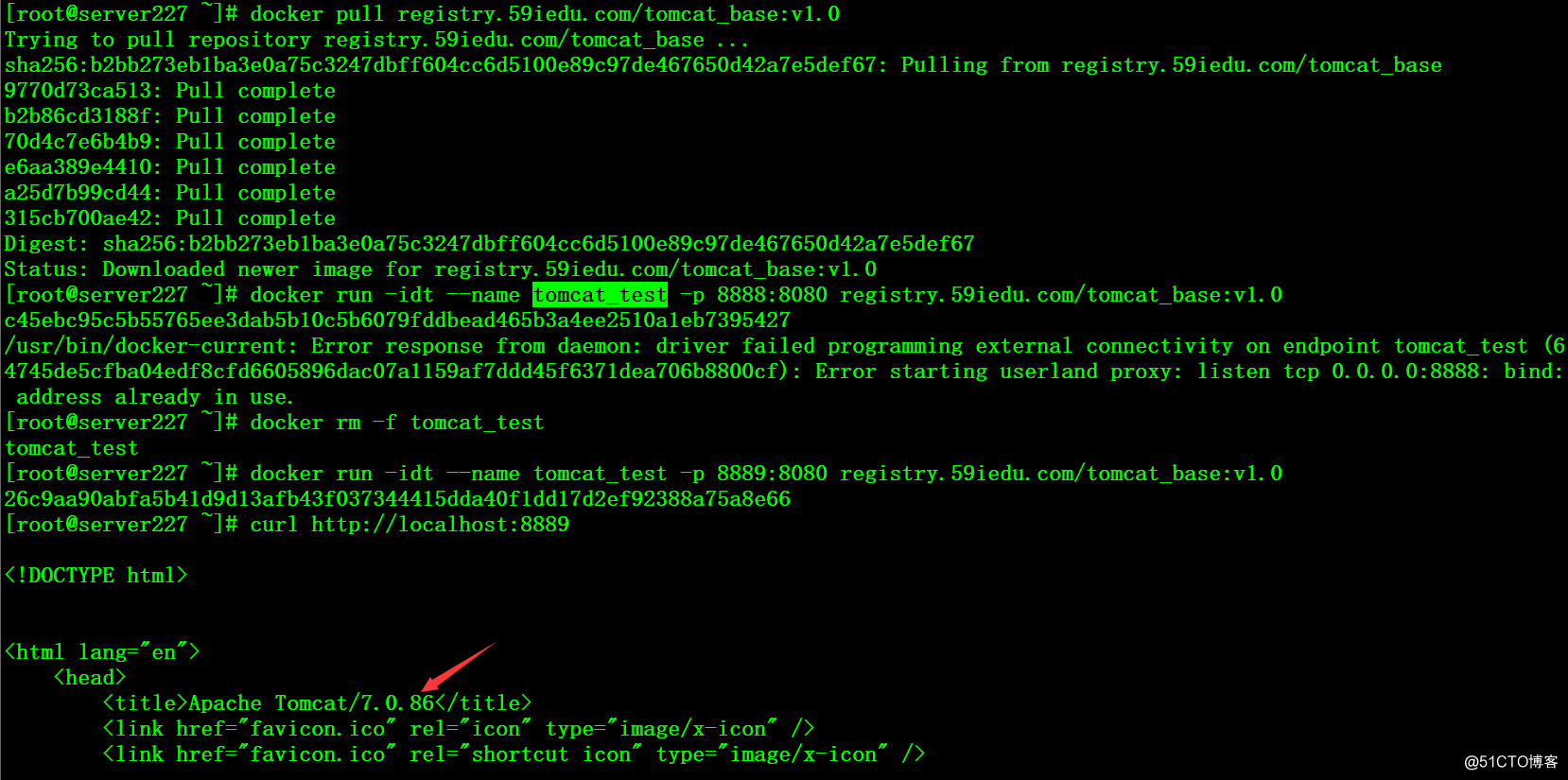
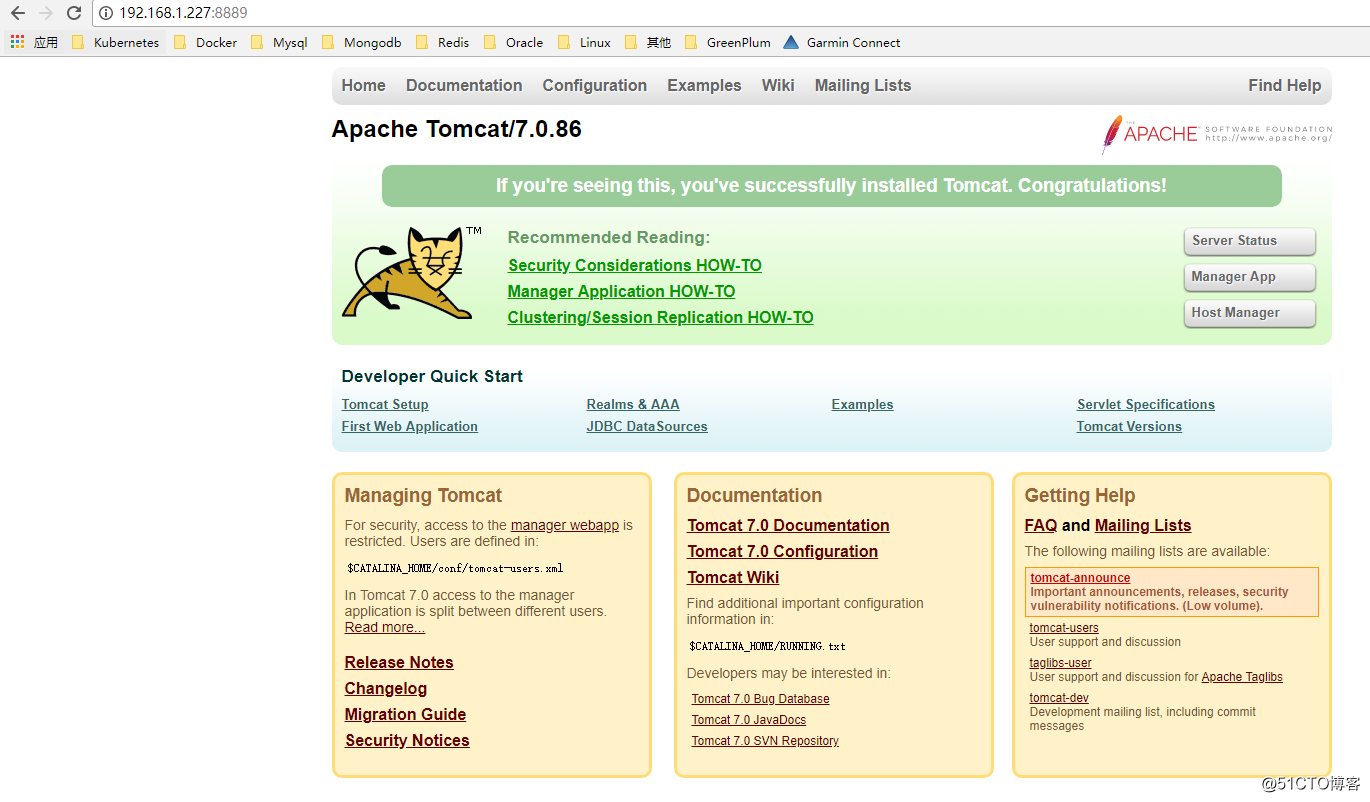
二、在基础镜像上叠加app并推送到本地仓库
这里选择使用shopxx java开源项目来做模拟java app,将部署的shopxx打包好放入指定位置即可运行。为了简单,这里选择Shopxx调用的数据库放在k8s集群之外,只要pod网络可以正常访问即可。
# cd shopxx
# cat dockerfile
FROM registry.59iedu.com/tomcat_base:v1.0
MAINTAINER yangliangwei "[email protected]"
COPY ROOT.tgz /home/
RUN tar zxf /home/ROOT.tgz -C /home/tomcat/webapps/ && rm -rf /home/ROOT.tgz
# docker build -t tomcat_shopxx:v1 .
# docker tag tomcat_shopxx:v1 registry.59iedu.com/tomcat_shopxx:v1
# docker push registry.59iedu.com/tomcat_shopxx:v1 三、准备filebeat镜像
Filebeat容器主要负责将app容器里面的日志推送到elasticsearch, 为了降低耦合度及后续的维护难度,创建filebeat容器的时候将filebeat.yml配置文件以configmap的方式实现。所以在镜像编译部分不考虑filebeat.yml配置文件
# cd filebeat-v5.4.0/
# ls -lh
# cat dockerfile
FROM docker.io/centos
MAINTAINER YangLiangWei <[email protected]>
# Install Filebeat
WORKDIR /usr/local
COPY filebeat-5.4.0-linux-x86_64.tar.gz /usr/local
RUN cd /usr/local && tar xvf filebeat-5.4.0-linux-x86_64.tar.gz && rm -f filebeat-5.4.0-linux-x86_64.tar.gz && ln -s /usr/local/filebeat-5.4.0-linux-x86_64 /usr/local/filebeat && chmod +x /usr/local/filebeat/filebeat && mkdir -p /etc/filebeat
ADD ./docker-entrypoint.sh /usr/bin/
RUN chmod +x /usr/bin/docker-entrypoint.sh
ENTRYPOINT ["docker-entrypoint.sh"]
CMD ["/usr/local/filebeat/filebeat","-e","-c","/etc/filebeat/filebeat.yml"]# cat docker-entrypoint.sh
#!/bin/bash
set -e
TMP=$PATHS
config=/etc/filebeat/filebeat.yml
if [ $TMP:0:1 = ‘/‘ ] ;then
tmp=‘"‘$PATHS‘"‘
fi
env
echo ‘Filebeat init process done. Ready for start up.‘
echo "Using the following configuration:"
cat /etc/filebeat/filebeat.yml
exec "[email protected]"# docker build -t filebeat-v5.4.0 .
# docker tag filebeat-v5.4.0 registry.59iedu.com/filebeat:v5.4.0
# docker push registry.59iedu.com/filebeat:v5.4.0四、准备yaml配置文件
1、tomcat.yaml文件
一个POD里面运行两个容器,两个容器通过emptydir的方式共享/home/tomcat/logs目录下的日志文件。Filebeat的配置文件通过configmap方式挂载进容器
# cat tomcat.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: tomcat-shopxx
namespace: default
spec:
replicas: 1
template:
metadata:
labels:
k8s-app: tomcat-shopxx
spec:
containers:
- image: registry.59iedu.com/filebeat:v5.4.0
imagePullPolicy: Always
name: filebeat
volumeMounts:
- name: app-logs
mountPath: /log
- name: filebeat-config
mountPath: /etc/filebeat/
- image: registry.59iedu.com/tomcat_shopxx:v1
name : tomcat-shopxx
imagePullPolicy: Always
ports:
- containerPort: 8080
volumeMounts:
- name: app-logs
mountPath: /home/tomcat/logs
volumes:
- name: app-logs
emptyDir:
- name: filebeat-config
configMap:
name: filebeat-config2、configamp.yaml
通过configmap的形式创建filebeat.yml配置文件,指定收集日志的路径、elasticsearch的配置信息及索引名称
# cat configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: filebeat-config
data:
filebeat.yml: |
filebeat.prospectors:
- input_type: log
paths:
- "/var/log/yum.log"
- "/log/*"
output.elasticsearch:
hosts: ["192.168.1.19:9600"]
index: "filebeat-tomcat-shopxx"3、service.yaml文件
通过service.yaml文件将shopxx发布出去
# cat service.yaml
apiVersion: v1
kind: Service
metadata:
name: tomcat-shopxx
labels:
k8s-app: tomcat-shopxx
spec:
type: NodePort
ports:
- port: 8080
protocol: TCP
targetPort: 8080
name: http
nodePort: 8480
selector:
k8s-app: tomcat-shopxx五、通过yaml配置文件创建pod、configmap、service
# kubectl create -f .
# kubectl get pod
# kubectl get svc
# kubectl get deployment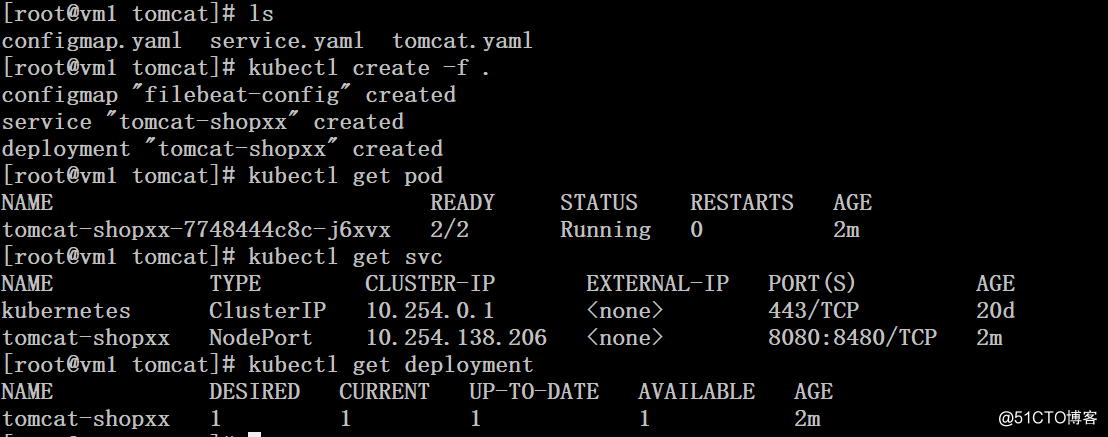
六、测试与验证
Filebeat容器日志: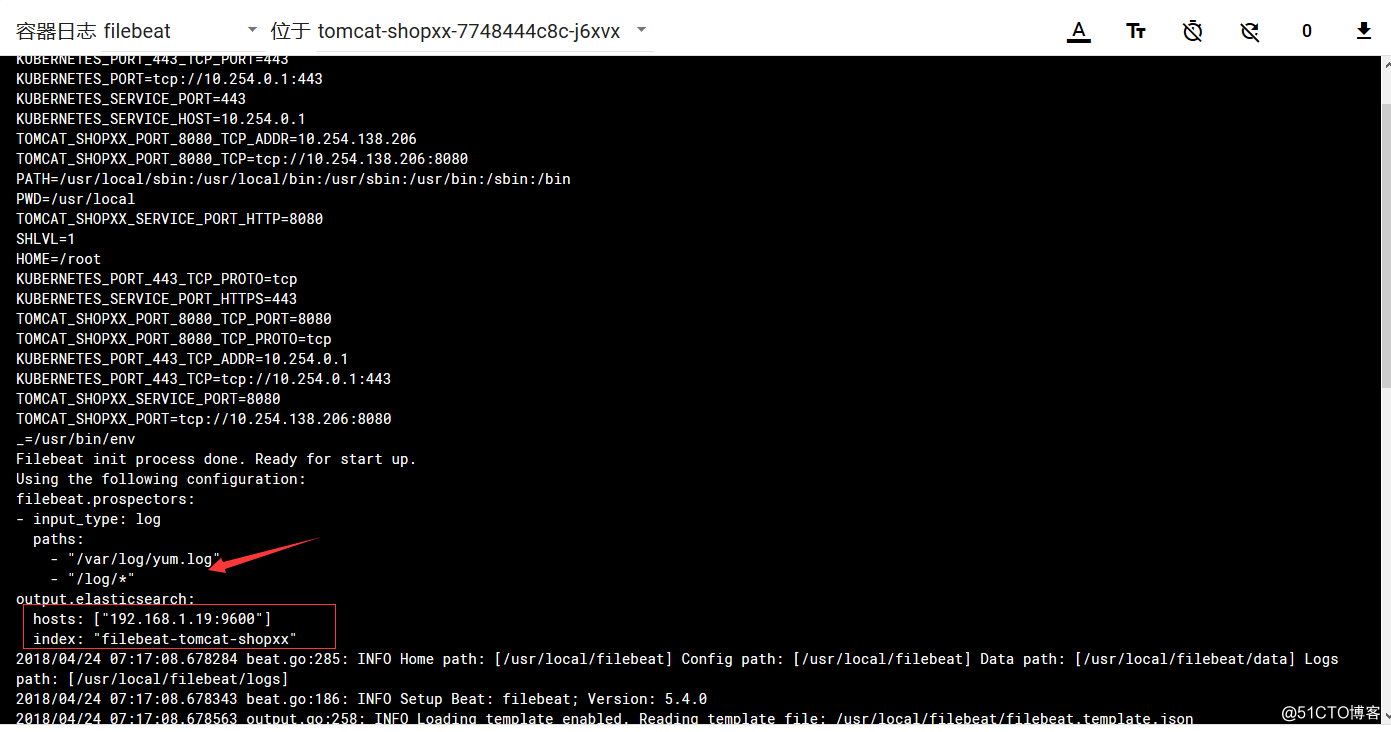
Shopxx容器日志:
使用elasticsearch-head插件查看对应的索引: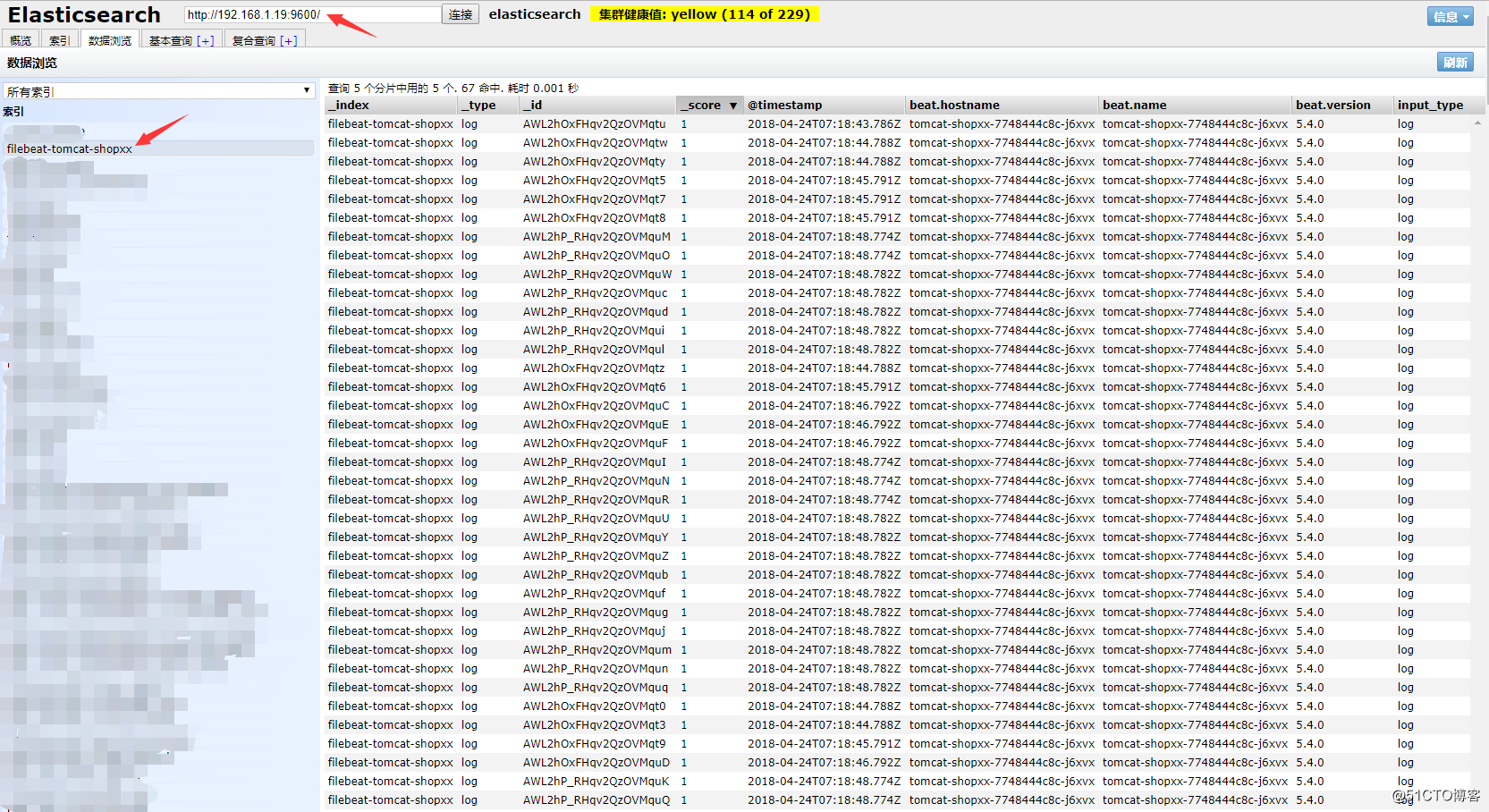
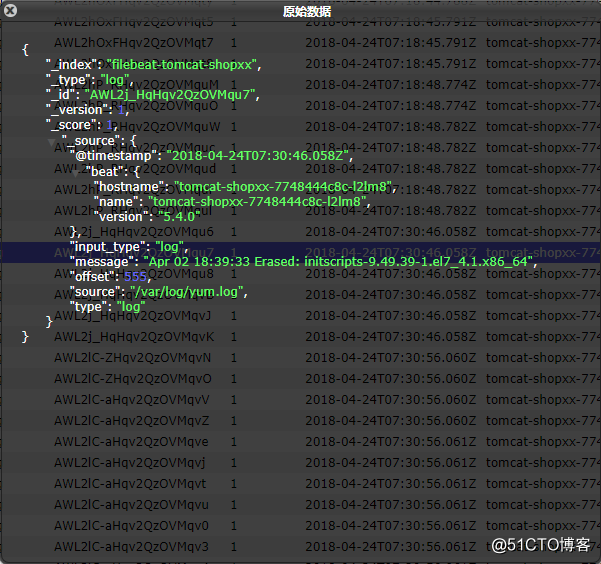
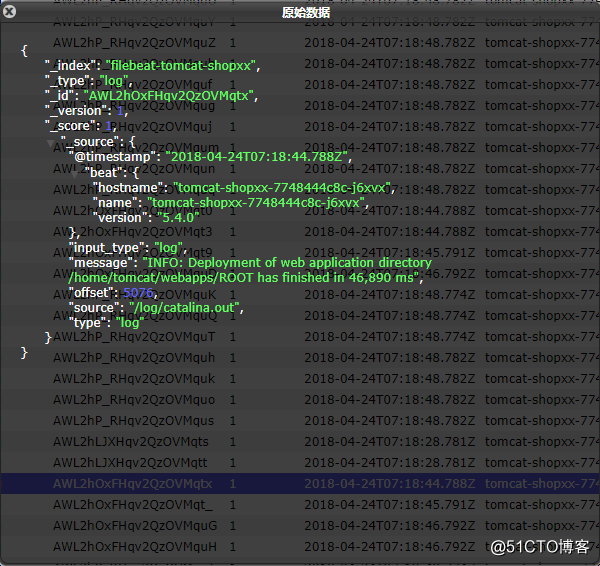
访问web测试: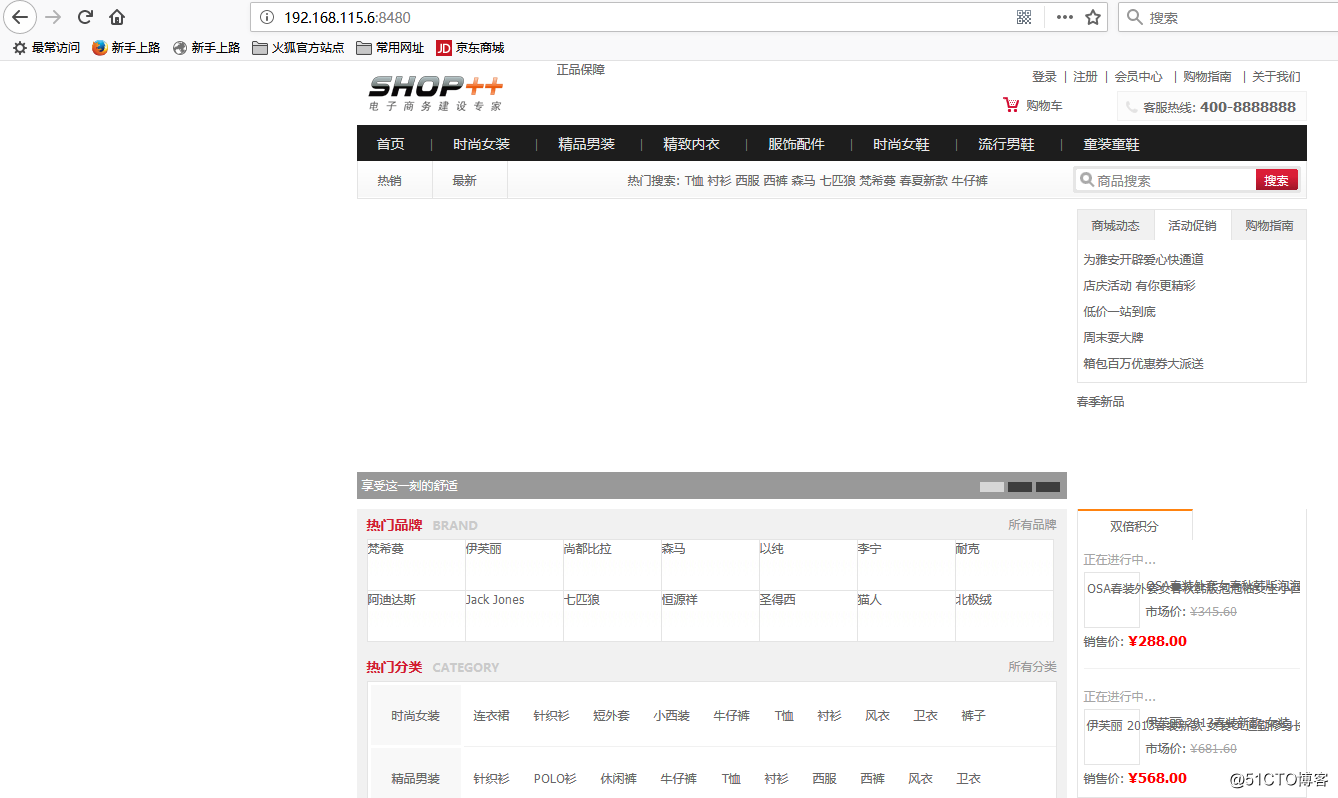
k8s日志收集解决方案(代码片段)
...专门的日志服务器。从这个日志服务器启一个logstash或者filebeat写入es。不建议直接从每个节点直接写入es。因为日志量大的时候可能es就会被弄死,另外这么多的filebeat也是要占用不少资源的。如果觉得麻烦,就每个node写个文件... 查看详情
(19)go-micro微服务filebeat收集日志(代码片段)
目录一Filebeat介绍二FileBeat基本组成三FileBeat工作原理四Filebeat如何记录文件状态:五Filebeat如何保证事件至少被输出一次六安装Filebeat七使用Filebeatfilebeat.yml编写八最后一Filebeat介绍filebeat是Beats中的一员。 Beats在是一个轻量级日... 查看详情
运用elasticstack收集docker容器日志(代码片段)
...将使用docker来安装ElasticStack。我将演示如何使用docker安装Filebeat并收集容器的日志。在我之前的文章“Beats:为Filebeat配置inputs”,我展示了如何使用Filebeat来收集container里的日志数据。在那篇文章中,Filebeat的安装并... 查看详情
elk使用filebeat替代logstash收集日志(代码片段)
使用beats采集日志之前也介绍过beats是ELK体系中新增的一个工具,它属于一个轻量的日志采集器,以上我们使用的日志采集工具是logstash,但是logstash占用的资源比较大,没有beats轻量,所以官方也推荐使用beats来作为日志采集工具... 查看详情
k8s通过sidecar模式收集pod的容器日志至elk
...群https://blog.51cto.com/yht1990/6081518准备sidecar镜像(filebeat)找一台服务器打镜像[root@yw-testfilebeat]#catDockerfileFROMdocker.elastic.co/beats/filebeat:7.9.0COPYfilebeat.yml/usr/share/filebeat/filebeat.ymlUSERrootRUNchownroot:filebeat/usr/share/filebeat/filebeat.ymlUSER... 查看详情
filebeat采集k8s日志-软链接(自定义docker目录使用此方法)(代码片段)
文章目录1、安装2、配置3、执行4、kafka消息格式5、集群日志目录1、安装1、下载filebeathttps://artifacts.elastic.co/downloads/beats/filebeat/filebeat-8.4.0-linux-x86_64.tar.gz2、上传服务器,解压tar-zxvffilebeat-8.4.0-linux-x86_64.tar.gzcd 查看详情
elastic(elk)stack实战教程06filebeat日志收集实践(下)(代码片段)
目录一、Filebeat收集Nginx日志实践1.1为什么收集Nginx日志1.2Nginx日志收集架构图1.3Nginx日志收集实践1.3.1安装Nginx 1.3.2配置filebeat1.3.3kibana展示1.4Nginxjson日志收集实践1.4.1收集问题1.4.2解决方案1.4.3配置json1.4.4配置Filebeat1.4.5Kibana展示1.5N... 查看详情
efk之filebeat线上使用方法个人线上应用及参考地址--我带你入门到成f神(代码片段)
Filebeat是一个轻量级的托运人,用于转发和集中日志数据。Filebeat作为代理安装在服务器上,监视您指定的日志文件或位置,收集日志事件,并将它们转发到Elasticsearch或Logstash进行索引。以下是Filebeat的工作原理:启动Filebeat时,... 查看详情
elk-filebeat收集docker容器日志(代码片段)
目录使用docker搭建elkfilebeat安装与配置docker容器设置参考文章首发地址使用docker搭建elk1、使用docker-compose文件构建elk。文件如下:version:‘3‘services:elk:image:sebp/elk:640ports:-"5601:5601"-"9200:9200"-"5044:5044"environment:-ES_JAVA_OPTS= 查看详情
部署elk+kafka+filebeat日志收集分析系统(代码片段)
ELK+Kafka+Filebeat日志系统文章目录ELK+Kafka+Filebeat日志系统1.环境规划2.部署elasticsearch集群2.1.配置es-1节点2.2.配置es-2节点2.3.配置es-3节点2.4.使用es-head插件查看集群状态3.部署kibana4.部署zookeeper4.1.配置zookeeper-1节点4.2.配置zo... 查看详情
使用filebeat采集日志结合logstash过滤出你想要的日志
...ithub.com/deviantony/docker-elk这里对es不做过多描述,主要针对filebeat和logstash讲解。Filebeat是一个轻量级的托运人,用于转发和集中日志数据。Filebeat作为代理安装在服务器上,监视您指定的日志文件或位置,收集日志事件,并将它们... 查看详情
elk日志系统设计方案-filebeat日志收集推送kafka(代码片段)
...目部署至服务器,运行服务后会生成日志文件。通过Filebeat监控相关文件夹,当有新日志产生,就读取新日志,将日志输送到Kafka中。经由Logstash消费Kafka生产的数据,进行加工过滤后输出到ElasticSearch进行日志... 查看详情
通过kafka和filebeat收集日志再保存到clickhouse最后通过grafana展现(代码片段)
日志就是一个大数据库 使用到golangclickhousekafkafilebeatgrafana filebeatfilebeat是通过docker部署的,把要收集的日志目录持到容器中,filebeat自动读取文件并送到kafka中去.日志格式为json.filebeat按行读取通过docker-compose部署filebeat文件... 查看详情
etl工具之日志采集filebeat+logstash
...志文件,需要进行日志收集并进行可视化展示,一般使用filebeat和logstash组合。Logstash是具有实时收集日志功能,可以动态统一来自不同来源的数据,任何类型的事件都可以通过各种各样的输入,过滤功能和输出插件来丰富和转换... 查看详情
docker容器日志收集方案(方案一filebeat+本地日志收集)(代码片段)
filebeat不用多说就是扫描本地磁盘日志文件,读取文件内容然后远程传输。docker容器日志默认记录方式为json-file就是将日志以json格式记录在磁盘上格式如下: "log":"2018-11-1601:24:30.372 INFO[demo1,786a42d3b893168f,786a42d3b893168f,false]1... 查看详情
filebeat+logstash+elasticsearch收集haproxy日志
filebeat用于是日志收集,感觉和flume相同,但是用go开发,性能比较好在2.4版本中,客户机部署logstash收集匹配日志,传输到kafka,在用logstash从消息队列中抓取日志存储到elasticsearch中。但是在5.5版本中,使用filebeat收集日志,减少... 查看详情
elk日志系统设计方案-filebeat日志收集推送kafka(代码片段)
...目部署至服务器,运行服务后会生成日志文件。通过Filebeat监控相关文件夹,当有新日志产生,就读取新日志,将日志输送到Kafka中。经由Logstash消费Kafka生产的数据,进行加工过滤后输出到ElasticSearch进行日志... 查看详情
elk日志系统设计方案-filebeat日志收集推送kafka(代码片段)
...目部署至服务器,运行服务后会生成日志文件。通过Filebeat监控相关文件夹,当有新日志产生,就读取新日志,将日志输送到Kafka中。经由Logstash消费Kafka生产的数据,进行加工过滤后输出到ElasticSearch进行日志... 查看详情