关键词:
原文地址:http://lixiangfeng.com/blog/article/content/7869717 转载请标明此处,谢谢!
缓存是什么?为什么要使用缓存?
缓存,通过在内存中缓存数据和对象来减少读取数据库的次数,从而提供动态、数据库驱动网站的速度。
缓存工具有哪些?区别在哪里?
缓存工具:Memecached、redis、MongoDB
区别:
- 性能都比较高:总体来讲,TPS(每秒总事务量)方面redis和memcache差不多,要大于 mongodb;
- 操作的便利性:
a) memcache数据结构单一
b) redis丰富一些,数据操作方面,redis更好一些,较少的网络IO次数,
c) mongodb支持丰富的数据表达,索引,最类似关系型数据库,支持的查询语言非常丰富;
- 内存空间的大小和数据量的大小:
a) redis在2.0版本后增加了自己的VM特性,突破物理内存的限制,可以对key value设置过期时间(类似memcache);
b) memcache可以修改最大可用内存,采用LRU算法;
c) mongoDB适合大数据量的存储,依赖操作系统VM做内存管理,吃内存也比较厉害,服务不要和别的服务在一起;
- 可靠性(持久化):
a) redis支持(快照、AOF):依赖快照进行持久化,aof增强了可靠性的同时,对性能有所影响;
b) memcache不支持,通常用在做缓存,提升性能;
c) MongoDB从1.8版本开始采用binlog方式支持持久化的可靠性
- 数据一致性(事务支持):
a) Memcache 在并发场景下,用cas保证一致性;
b) redis事务支持比较弱,只能保证事务中的每个操作连续执行
c) mongoDB不支持事务
- 数据分析:mongoDB内置了数据分析的功能(mapreduce),其他不支持
Memecached详解
Memecached、memecached和memecache的区别:
- 其中首字母大写的Memcached,指的是Memcached服务器,就是独立运行Memcached的后台服务器,用于存储数据的“数据库”;
- 而memcached和memcache指的是Memcached的客户端。其中memcache是独立用php实现的,属于老旧的版本。而memcached是基于原生的c的libmemcached的扩展,更加完善,性能更高一些。
Memecached重点启动设置参数
- –m:默认分配内存大小为64M,32位操作系统下每个进程最大分配内存为2G,所以如果需要分配更多的内存需要使用64位操作系统,但是这个不会一启动就占用,是随着需要逐步分配给各slab的。;
- –I:调整分配page页的大小,默认1M,最小1K,最大128K;
- –f:memcached默认情况下下一个slab的最大值为前一个的1.25倍,可通过此参数来设定;
- –P:TCP端口设置,默认为11211;
- –l(小写L):监听的IP地址,如果为本机可不设置;
- –d:以守护进程的方式运行;
- –u:指定用户;
- –M:禁止LRU策略,内存耗尽时返回错误,而不是删除项;
- –c:最大同时连接数,默认为1024;
- –t:线程数,默认为4;
e.g. /usr/bin/memcached -m 64 -p 11212 -u nobody -c 2048 -f 1.1 -I 1024 -d -l 10.211.55.9
Memecached内存分配策略
当第一次往memcached存储数据时, memcached会去申请1MB的内存(这1M的内存成为page) , 然后把该块内存分割为多个slab,如果可以存储这个数据的最佳的chunk大小为128B,那么memcached会把刚申请的slab以128B为单位进行分割成8192块. 当这页slab的所有chunk都被用完时,并且继续有数据需要存储在128B的chunk里面时,如果已经申请的内存小于最大可申请内存10MB 时,memcached继续去申请1M内存,继续以128B为单位进行分割再进行存储;如果已经无法继续申请内存,那么mamcached会先根据LRU 算法把队列里面最久没有被使用到的chunk进行释放后,再将该chunk用于存储.
Page为内存分配的最小单位
Memcached的内存分配以page为单位,默认情况下一个page是1M,可以通过-I参数在启动时指定。如果需要申请内存时,memcached会划分出一个新的page并分配给需要的slab区域。page一旦被分配在重启前不会被回收或者重新分配
Slabs划分数据空间
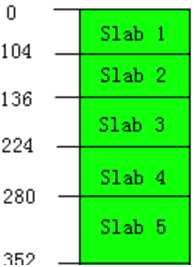
Memecached存储数据时不是直接将数据存储到page中,而是预先划分为一系列的slab,每个slab至负责存储大于上一个slab同时又小于或等于其本身大小的数据,如slab2只负责存储105~136 byte之间大小的数据,每个slab大小是不一样的,默认下一个slab的最大值为前一个的1.25倍(-f)
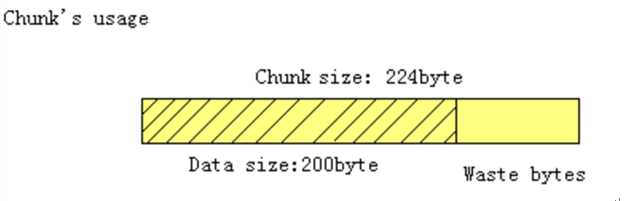
Chunk才是存放缓存数据的单位
Memecached将每个slab划分为一系列相等大小的存储空间,这个空间就叫做chuck。Chunk是Memecached的最小存储单元。同时,如果存储数据大小小于chunk的大小,空余的空间将会被闲置,这个是为了防止内存碎片而设计的。例如下图,chunk size是224byte,而存储的数据只有200byte,剩下的24byte将被闲置。
综合上面的介绍,memcached的内存分配策略就是:按slab需求分配page,各slab按需使用chunk存储。
这里有几个特点要注意:Memcached分配出去的page不会被回收或者重新分配Memcached申请的内存不会被释放slab空闲的chunk不会借给任何其他slab使用
Memecached的static命令详解
使用Telnet客户端连接Memecached后可以使用static命令
|
命令 |
含义说明 |
|
stats slabs |
显示各个slab的信息,包括chunk的大小、数目、使用情况等 |
|
stats items |
显示各个slab中item的数目和最老item的年龄(最后一次访问距离现在的秒数) |
|
stats detail [on|off|dump] |
设置或者显示详细操作记录; 参数为on,打开详细操作记录; 参数为off,关闭详细操作记录; 参数为dump,显示详细操作记录(每一个键值get、set、hit、del的次数) |
|
stats malloc |
打印内存分配信息 |
|
stats sizes |
打印缓存使用信息 |
|
stats reset |
重置统计信息 |
Memecached的分布式算法
当一台Memecached无法满足我们的需求时,我们需要配置多台Memecached服务器,这种用法就叫做Memecached的分布式,但是随之而来的问题是,假设我们有三台服务器A、B、C,需要存一个用户姓名,然后存在了服务器A上,那么当我们要取得时候如何得知我们之前存在哪里了呢?如何解决这个问题就成了Memecached分布式的重点。
通常而言我们有两种方式来实现:
- 哈希取摸(取余数):
a) 简介:假设我们有3台服务器,我们将存入Memecached中的key通过哈希算法得到一个整数,然后将这个整数与3取摸,那么不管这个整数是多少,结果必然是0,1,2中的一个,那么这样一来就可以解决这个问题。
b) 缺点:当我们服务器的数量发生变化时,依靠上述算法结果将会与未变化之前不同,导致原先我们存入的数据丢失无法获取到。
c) 代码示例:
<?php /** * 普通Hash分布 */ //Hash函数 functionmHash($key){ $md5 = substr(md5($key),0,8); $seed = 31; $hash = 0; for($i = 0;$i<8;$i++){ $hash = $hash * $seed + ord($md5{$i}); $i++; } return$hash&0x7FFFFFFF; } //假设有2台Memcached服务器 $servers = array( array(‘host‘ =>‘192.168.1.1‘,‘port‘ =>11211), array(‘host‘ =>‘192.168.1.1‘,‘port‘ =>11211) ); $key = ‘MyBlog‘; $value = ‘http://blog.phpha.com‘; $sc = $servers[mHash($key) % 2]; $memcached = newMemcached($sc); $memcached->set($key,$value); ?>
- 一致性哈希分布算法,一致性Hash分布算法分4个步骤:
a) 将一个32位整数[0 ~ (2^32-1)]想象成一个环,0 作为开头,(2^32-1) 作为结尾,当然这只是想象。
b) 通过Hash函数把KEY处理成整数。这样就可以在环上找到一个位置与之对应。
c) 把Memcached服务器群映射到环上,使用Hash函数处理服务器对应的IP地址即可。
d) 把数据映射到Memcached服务器上。查找一个KEY对应的Memcached服务器位置的方法如下:从当前KEY的位置,沿着圆环顺时针方向出发,查找位置离得最近的一台Memcached服务器,并将KEY对应的数据保存在此服务器上。
e) 代码示例:
<?php /** * 一致性Hash分布 */ classFlexiHash{ //服务器列表 private$serverList = array(); //记录是否已经排序 private$isSorted = FALSE; //添加一台服务器 publicfunctionaddServer($server){ $hash = $this->mHash($server); if(!isset($this->serverList[$hash])){ $this->serverList[$hash] = $server; } //需要重新排序 $this->isSorted = FALSE; returnTRUE; } //移除一台服务器 publicfunctionremoveServer($server){ $hash = $this->mHash($server); if(isset($this->serverList[$hash])){ unset($this->serverList[$hash]); } //需要重新排序 $this->isSorted = FALSE; returnTRUE; } //在当前服务器列表查找合适的服务器 publicfunctionlookup($key){ $hash = $this->mHash($key); //先进行倒序排序操作 if(!$this->isSorted){ krsort($this->serverList,SORT_NUMERIC); $this->isSorted = TRUE; } //圆环上顺时针方向查找当前KEY紧邻的一台服务器 foreach($this->serverList as$pos =>$server){ if($hash>= $pos) return$server; } //没有找到则返回顺时针方向最后一台服务器 return$this->serverList[count($this->serverList) - 1]; } //Hash函数 privatefunctionmHash($key){ $md5 = substr(md5($key),0,8); $seed = 31; $hash = 0; for($i = 0;$i<8;$i++){ $hash = $hash * $seed + ord($md5{$i}); $i++; } return$hash&0x7FFFFFFF; } } ?>
说明:这样一来,当添加或移除某一台服务器时,受影响的数据范围变的更小了。
Memecached的用法
- add、set、replace的区别:
a) add用于添加一个要缓存的数据;
b) set用于设置一个指定key的内容,是add和replace的集合;
c) replace用户替换一个指定key的内容,如果key不存在则返回false;
|
方法 |
当key存在 |
当key不存在 |
|
add |
false |
true |
|
replace |
替换(true) |
false |
|
set |
替换(true) |
true |
- flush用于清除缓存的所有数据;
- cas仅在当前客户端最后一次取值后,该key 对应的值没有被其他客户端修改的情况下,才能够将值写入
- increment和decrement:
a) increment,将元素的值+1,如果元素的值不是数字则按0处理;
b) decrement,将元素的值-1,如果元素的值不是数组则按0处理;
c) 可以通过increment和decrement实现Memecached的队列;
- append和prepend:
a) append 向元素后面追加内容;
b) prepend 向元素前面追加内容;
zookeeper原理详解及常用操作(代码片段)
ZooKeeper是什么?ZooKeeper是一个开源的分布式应用程序协调系统。简称ZK,ZK是一个典型的分布式数据一致性解决方案,分布式应用程序可以基于它实现数据的发布/订阅、负载均衡、名称服务、分布式协调/通知、集群管理、Master选... 查看详情
分布式缓存--系列1--hash环/一致性hash原理
当前,Memcached、Redis这类分布式kv缓存已经非常普遍。从本篇开始,本系列将分析分布式缓存相关的原理、使用策略和最佳实践。我们知道Memcached的分布式其实是一种“伪分布式”,也就是它的服务器结点之间其实是相互无关联... 查看详情
paxos算法原理及理解
...递且具有高度容错特性的一致性算法,是目前公认的解决分布式一致性问题最有效的算法之一,其解决的问题就是在分布式系统中如何就某个值(决议)达成一致。我自己的理解是:不要把这个Paxos算法达到的目的和分布式事务... 查看详情
菜鸟刷面试题(redis篇)
...库数据的一致性?redis持久化有几种方式?redis怎么实现分布式锁?redis分布式锁有什么缺陷?redis如何做内存优化?redis淘汰策略有哪些?redis常见的性能问题有哪些?该如何解决?redis是什么?都有哪些使用场景?1、Redis是一款... 查看详情
一致性hash算法原理白话
...术举例:Memcache1.2、技术瓶颈memcached服务器端本身不提供分布式cache的一致性,由客户端实现提供。以余数分布式算法为例。余数分布式算法是根据添加进入缓存时key的hash值通过特定的算法得出余数,然后根据余数映射到关联的... 查看详情
分布式技术专题「分布式缓存专题」针对于缓存淘汰算法之lru和lfu及fifo原理分析
前提概要无论是浏览器缓存(如果是chrome浏览器,可以通过chrome:://cache查看),还是服务端的缓存(通过memcached或者redis等内存数据库)。缓存不仅可以加速用户的访问,同时也可以降低服务器的负载和压力。那么了解常见的缓存淘汰... 查看详情
guava缓存详解及使用(代码片段)
缓存缓存分为本地缓存与分布式缓存。本地缓存为了保证线程安全问题,一般使用ConcurrentMap的方式保存在内存之中,而常见的分布式缓存则有Redis,MongoDB等。一致性:本地缓存由于数据存储于内存之中,每个... 查看详情
java基础
...据库:Mysql基础,事务隔离,InnoDB存储引擎原理,MVCC和锁分布式缓存:redis、memcache等的原理、协议、区别、集群部署Spring:AOP和IOC分布式系统:CAP、分布式事务、分布式一致性原理MQ消息队列:比如kafka(底层原理,包括数据存... 查看详情
关于一致性hash算法
...个标准开发配置了。在大规模的缓存应用中,应运而生了分布式缓存系统。分布式缓存系统的基本原理,大家也有所耳闻。key-value如何均匀的分散到集群中?说到此,最常规的方式莫过于hash取模的方式。比如集群中可用机器适... 查看详情
分布式锁原理及实现方式(代码片段)
... 目前几乎很多大型网站及应用都是分布式部署的,分布式场景中的数据一致性问题一直是一个比较重要的话题。分布式的CAP理论告诉我们“任何一个分布式系统都无法同时满足一致性(Consistency)、可用性... 查看详情
zookeeper原理及使用
...Keeper是HadoopEcosystem中非常重要的组件,它的主要功能是为分布式系统提供一致性协调(Coordination)服务,与之对应的Google的类似服务叫Chubby。今天这篇文章分为三个部分来介绍ZooKeeper,第一部分介绍ZooKeeper的基本原理,第二部分介... 查看详情
day123.elasticsearch:cap定理集群搭建架构原理及分片倒排索引面试题(代码片段)
...四.优化建议三、相关面试题(建议电商后再看)一、CAP定理分布式系统的最大难点,就是各个节点的状态如何同步。CAP定理是这方面的基本定理,也是理解分布式系统的起点。C:一致性(Consistency) 强一致... 查看详情
分布式技术专题「分布式技术架构」一文带你厘清分布式事务协议及分布式一致性协议的算法原理和核心流程机制(上篇)
...了,要不就是把门槛抬的很高,所以针对于一些分布式角度而言的技术知识点,更是必备条件以及重中之重了。那么今天笔者就针对于分布式协议以及一些算法原理进行详细的分析和原理介绍。分布式体系分布式体系... 查看详情
分布式技术专题「系统功能原理分析」缓存淘汰算法之lru和lfu及fifo介绍(代码片段)
前提概要无论是浏览器缓存(如果是chrome浏览器,可以通过chrome:😕/cache查看),还是服务端的缓存(通过memcached或者redis等内存数据库)。缓存不仅可以加速用户的访问,同时也可以降低服务器的负载和压力。那么了... 查看详情
zookeeper原理及使用(转)
...Keeper是HadoopEcosystem中非常重要的组件,它的主要功能是为分布式系统提供一致性协调(Coordination)服务,与之对应的Google的类似服务叫Chubby。今天这篇文章分为三个部分来介绍ZooKeeper,第一部分介绍ZooKeeper的基本原理,第二部分介... 查看详情
zookeeper的原理及使用
...Keeper是HadoopEcosystem中非常重要的组件,它的主要功能是为分布式系统提供一致性协调(Coordination)服务,与之对应的Google的类似服务叫Chubby。今天这篇文章分为三个部分来介绍ZooKeeper,第一部分介绍ZooKeeper的基本原理,第二部分介... 查看详情
强一致性hash实现java版本及强一致性hash原理
一致性hash分布式过程中我们将服务分散到若干的节点上,以此通过集体的力量提升服务的目的。然而,对于一个客户端来说,该由哪个节点服务呢?或者说对某个节点来说他分配到哪些任务呢?强哈希考虑到单服务器不能承载... 查看详情
大型网站架构系列:缓存在分布式系统中的应用
本文是《缓存在分布式系统中的应用》第三篇文章。上次主要给大家分享了,缓存在分布式系统中的应用,主要从不同的场景,介绍了CDN,反向代理,分布式缓存,本地缓存的常规架构和基本原理。因为时间关于,原计划分享《... 查看详情