关键词:
首发于知乎专栏
本文试图从语义角度来解释Rust所有权的概念,以便帮助降低Rust的学习曲线。
编程语言的内存管理,大概可以分为自动和手动两种。自动管理就是用GC(垃圾回收)来自动管理内存,像Java、Ruby、Golang、Elixir等语言都依赖于GC。而C/C++却是依赖于手工管理内存,程序员使用malloc和free函数来分配释放内存。GC技术经过这么多年的发展,是相对安全的内存管理,也解放了程序员,但是在一些系统级编程领域,实际上是需要避免GC,因为GC会引起“世界暂停”,这将带来性能问题,所以在系统级编程领域C/C++占绝对的霸主地位。但是,有C/C++就够了吗?靠手工来管理内存,会带来很多安全问题,比如悬垂指针,诚然有最佳实践引导,就算经验丰富的熟手也难以避免类似内存安全的错误。
Rust的出现,就是为了解决这个痛点,它强大的所有权系统,就像是黑暗中的明灯。我曾经也对其感到疑虑,这凭空产生的Rust的所有权系统是不是拍脑袋发明的,这真的是解决内存安全问题的“银弹”吗?其实历史上也曾经有过解决内存安全问题的努力,比如Cyclone语言,它是一门对C语言进行安全升级的语言,基于区域(region,有点和Rust所有权系统中的生命周期相类似)的内存管理,避免一些潜在的内存安全问题,但是,功能极其有限,类似的尝试还有ML Kit。就是这些早期的方案,给了Rust语言灵感,才造就现在的所有权系统,所以Rust的所有权系统并非凭空产生。至于是不是“银弹”,还不敢下结论,至少,Rust的所有权系统是迄今为止最精妙最科学的方案了。
语义模型
什么叫语义模型?语义,顾名思义,是指语言的含义。我们在学习一个新概念的时候,首先就要搞明白它的语义。而语义模型,是指语义构建的心智模型,因为概念点不是孤立存在的,彼此之间必然有紧密的联系,我们通过挖掘其语义之间的关联规则,在你的认知中形成一颗“语义树”,这样的理解才是通透的。所有权的“语义树”,如下图所示:
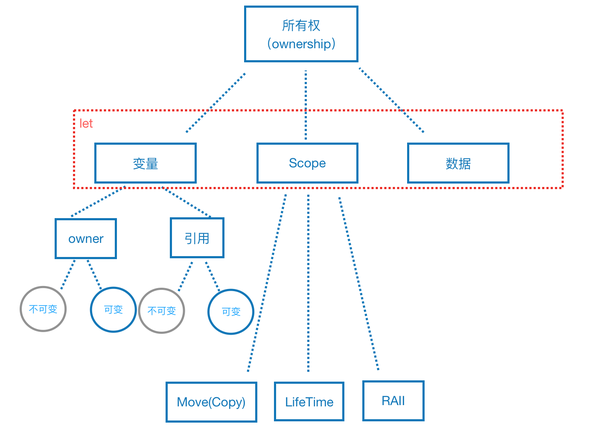
上图中的语义树,主要是想表达下面几层意思:
所有权是有好多个概念系统性组成的一个整体概念。
let绑定,绑定了什么?变量 + 作用域 + 数据(内存)。
move、lifetime、RAII都是和作用域相关的,所以想理解它们就先要理解作用域。
所有权
所有权,顾名思义,至少应该包含两个对象:“所有者”和“所有物”。在Rust中,“所有者”就是变量,“所有物”是数据,抽象来说,就是指某一片内存。let关键字,允许你绑定“所有者”和“所有物”,比如下面代码:
let num = String::from("42");let关键字,让num绑定了42,那么可以说,num拥有42的所有权。但这个所有权,是有范围限制的,这个范围就是作用域(scope)。换句话说,num在当前作用域下,拥有42的所有权。如果它要进入别的作用域,就必须交出所有权。比如下面的代码:
let num = String::from("42");
let num2 = num;let关键字会开启一个隐藏作用域,我们可以借助于MIR来查看,编译这两行代码,查看其MIR:
scope 1 { let _1: std::string::String; // "num" in scope 1 at <anon>:4:8: 4:11 scope 2 { let _2: std::string::String; // "num2" in scope 2 at <anon>:5:8: 5:12 } }Scope 1就是num所在的作用域,scope 2是num2所在的作用域。当你此时想像下面这样使用num的时候:
let num = String::from("42");let num2 = num;println!("{:?}", num);编译器会报错:error[E0382]: use of moved value: `num`。因为num变量的所有权已经转移了。
移动(move)语义
移动,是指所有权的转移。什么时候所有权会转移呢?就是当变量切换作用域的时候,所谓移动,当然是从一个地方挪到另一个地方。其实你也可以这样认为,当变量切换到另一个作用域,它在当前作用域的绑定将会失效,它拥有的数据则会在另一个作用域被重新绑定。
但是对于实现了Copy Trait的类型来说,当移动发生的时候,它们可以Copy的副本代替自己去移动,而自身还保留着所有权。比如,Rust中的基本数字类型都默认实现了Copy Trait,比如下面示例:
let num = 42;
let num2 = num;
println!("{:?}", num);此时,我们打印num,编译器不会报错。num已经move了,但是因为数字类型是默认实现Copy Trait,所以它move的是自身的副本,其所有权还在,并未发生转移,通过编译。不过需要注意的是,Rust 不允许自身或其任何部分实现了Drop trait 的类型使用Copy trait。
当move发生的时候,所有权被转移的变量,将会被释放。
作用域(Scope)
没有GC帮助我们自动管理内存,我们只能依赖所有权这套规则来手工管理内存,这就增加了我们的心智负担。而所有权的这套规则,是依赖于作用域的,所以我们需要对Rust中的作用域有一定了解。
我们在之前的描述中已经见过了隐式作用域,也就是在当前作用域中由let开启的作用域。在Rust中,也有一些特殊的宏,比如println!(),也会产生一个默认的scope,并且会隐式借用变量。除此之外,更明显的作用域 范围则是函数,也就是说,一个函数本身,就是一个显式的作用域。你也可以使用一对花括号({})来创建显式的作用域。
除此之外,一个函数本身就显式的开辟了一个独立的作用域。比如:
fn sum(a: u32, b: u32) -> u32 {
a + b
}
fn main(){
let a = 1;
let b = 2;
sum(a, b);
}上面的代码中,当调用sum函数的时候,a和b当作参数传递过去,此时就会发生所有权move的行为,但是因为a和b都是基本数据类型,实现了Copy Trait,所以它们的所有权没有被转移。如果换了是没有实现Copy Trait的变量,所有权就会被转移。
作用域在Rust中的作用就是制造一个边界,这个边界是所有权的边界。变量走出其所在作用域,所有权会move。如果不想让所有权move,则可以使用“引用”来“出借”变量,而此时作用域的作用就是保证被“借用”的变量准确归还。
引用和借用
有的时候,我们并不想让变量的所有权转移,比如,我写一个函数,该函数只是给某个数组插入一个固定的值:
fn push(vec: &mut Vec<u32>) {
vec.push(1);
}
fn main(){
let mut vec = vec![0, 1, 3, 5];
push(&mut vec);
println!("{:?}", vec);
}此时,我们把数组vec传给push函数,就不希望把所有权转移,所以,只需要传入一个可变引用&mut vec,因为我们需要修改vec,这样push函数就得了vec变量的可变借用,让我们去修改。push函数修改完,会将借用的所有权归还给vec,然后println!函数就可以顺利使用vec来输出打印。
引用非常方便我们使用,但是如果滥用的话,会引起安全问题,比如悬垂指针。看下面示例:
let r;
{
let a = 1;
r = &a;
}
println!("{}", r);上面代码中,当a离开作用域的时候会被释放,但此时r还持有一个a的借用,编译器中的借用检查器就会告诉你:`a` does not live long enough。翻译过来就是:`a`活的不够久。这代表着a的生命周期太短,而无法借用给r,否则&a就指向了一个曾经存在但现在已不再存在的对象,这就是悬垂指针,也有人将其称为野指针。
生命周期
上面的示例中,是在同一个函数作用域下,编译器可以识别出生命周期的问题,但是当我们在函数之间传递引用的时候,编译器就很难自动识别出这些问题了,所以Rust要求我们为这些引用显式的指定生命周期标记,如果你不指定生命周期标记,那么编译器将会“鞭策”你。
struct Foo {
x: &i32,
}
fn main() {
let y = &5;
let f = Foo { x: y };
println!("{}", f.x);
}上面这段代码,编译器会提示你:missing lifetime specifier。这是因为,y这个借用被传递到了 let f = Foo { x: y }所在作用域中。所以需要确保借用y活得比Foo结构体实例长才行,否则,如果借用y被提前释放,Foo结构体实例就会造成悬垂指针了。所以我们需要为其增加生命周期标记:
struct Foo<‘a> {
x: &‘a i32,
}
fn main() {
let y = &5;
let f = Foo { x: y };
println!("{}", f.x);
}加上生命周期标记以后,编译器中的借用检查器就会帮助我们自动比对参数变量的作用域长度,从而确保内存安全。
再来看一个例子:
fn longest<‘a>(x: &‘a str, y: &‘a str) -> &‘a str {
if x.len() > y.len() {
x
} else {
y
}
}
fn main() {
let a = "hello";
let result;
{
let b = String::from("world");
result = longest(a, b.as_str());
}
println!("The longest string is {}", result);
}此段代码,编译器会报错:`b` does not live long enough。这是因为result在外部作用域定义的,result的生命周期是和main函数一样长的,也就是说,在main函数作用域结束之前,result都必须存活。而此时,变量b在花括号定义的作用域中,出了作用域b就会被释放。而根据longest函数签名中的生命周期标注,参数b的生命周期必须和返回值的生命周期一致,所以,借用检查器果断的判断出`b` does not live long enough。
“显式的指定”,这是Rust的设计哲学之一。这对于新手,尤其是习惯了动态语言的人来说,可能是一个心智负担。显式的指定方便了编译器,但是对于程序员来说略显繁琐。不过为了安全考虑,我们就欣然接受这套规则吧。
本文出自 “悟道集” 博客,请务必保留此出处http://blackanger.blog.51cto.com/140924/1946189
rust学习内存安全探秘:变量的所有权引用与借用
...能轻松和其他语言集成。•可靠性-Rust丰富的类型系统和所有权模型保证了内存安全和线程安全,让您在编译期就能够消除各种各样的错误。•生产力-Rust拥有出色的文档、友好的编译器和清晰的错误提示信息,还集成了一流的... 查看详情
最强nlp模型-bert
...下问有关的(Contextual).意思就是,word2vec只是具有词本身的语义信息,而没有包含文本(不是特指某个文本,而是所有跟该词相关的文本信息)上下文信息,BERT却是相反的.目前为止,BERT已经取得了所有NLP任务的最好结果,所以才称之为最强N... 查看详情
潜在语义分析(lsa)
参考技术A潜在语义分析(LatentSemanticAnalysis,LSA)是一种无监督学习方法,主要用于分本的话题分析,其特点是通过矩阵分解发现文本与单词之间的基于话题的语义关系。文本信息处理的一个核心问题是对文本的语义内容进行表示... 查看详情
juc多线程:jmm内存模型与volatile内存语义(代码片段)
一、JMM内存模型:1、什么是JMM内存模型: Java内存模型是Java虚拟机定义的一种多线程访问Java内存各个变量的访问规范,主要围绕如何解决并发过程中的原子性、可见性、有序性这三个问题来解决线程的安... 查看详情
个性化推荐中的隐语义模型
...基于用户的协同过滤算法和基于物品的协同过滤算法。隐语义模型是对矩阵分解的改进,通过矩阵分解建立了用户和隐类之间的关系,物品和隐类之间的关系,最终得到用户对物品的偏好关系。隐语义模型问世之后,诞生了若干... 查看详情
nlp语义标注模型数据准备及实战
NLP语义标注模型数据准备及实战目录NLP语义标注模型数据准备及实战流程示例代码示例 查看详情
Rust 所有权问题
】Rust所有权问题【英文标题】:Rustownershipissues【发布时间】:2021-01-2916:10:51【问题描述】:我对Rust很陌生,我主要是C#、javascript和python开发人员,所以我喜欢以OOP方式处理事情,但是我仍然无法理解rust的所有权。尤其是在OOP... 查看详情
多类语义分割模型评估
】多类语义分割模型评估【英文标题】:Multiclasssemanticsegmentationmodelevaluation【发布时间】:2020-10-0904:24:01【问题描述】:我正在做一个关于多类语义分割的项目。我制定了一个模型,通过降低损失值来输出漂亮的下降分割图像。... 查看详情
新手眼中的rust所有权规则(代码片段)
新手眼中的Rust所有权规则如果你有关注本人博客,那么很明显,从今年年初开始,我便开始学习Rust。此文与之前风格略有不同,旨在总结阅读Rust书籍时遇到的要点。到目前为止,它包含了我对Rust所有权规则的所有理解。Rust的... 查看详情
semanticmonocularslamforhighlydynamicenvironments面向高动态环境的语义单目slam
...往会失败。作者为解决高度动态环境中的问题,提出一种语义单目SLAM架构,结合基于特征和直接方法实现具有挑战的条件下系统的鲁棒性。作者所提出的方法利用专业概率模型从场景中提取的语义信息,使跟踪和建图的概率最... 查看详情
为啥 Rust 需要所有权注释而不是推断它? [复制]
】为啥Rust需要所有权注释而不是推断它?[复制]【英文标题】:WhydoesRustrequireownershipannotationsinsteadofinferringit?[duplicate]为什么Rust需要所有权注释而不是推断它?[复制]【发布时间】:2020-10-1722:31:43【问题描述】:Rust为什么不能完... 查看详情
rust所有权
所有权规则Rust中的每一个值都有一个被称为其所有者(owner)的变量。值在任一时刻有且只有一个所有者。当所有者(变量)离开作用域,这个值将被丢弃。引用和Copy特性赋值过程:包括变量赋值,函数传参,函数返回如果类... 查看详情
如何在 AllenNLP 中训练语义角色标注模型?
】如何在AllenNLP中训练语义角色标注模型?【英文标题】:HowcanItrainthesemanticrolelabelingmodelinAllenNLP?【发布时间】:2019-08-1019:08:37【问题描述】:如何训练semanticrolelabelingmodelinAllenNLP?我知道allennlp.training.trainer函数,但我不知道如... 查看详情
rust所有权进阶部分
为了演示所有权功能,我们需要一些复杂的数据类型,之前介绍的类型都是存储在栈上的并且当离开作用域就被移除栈,不过我们需要一个存储在堆上的数据来探索Rust是如何知道该在何时清理数据的。这里使用String作... 查看详情
语义网的模型定义
参考技术A“资源描述框架”的“数据模型”(外语:RDFDataModel)提供了一个简单但功能强大的模型,通过资源、属性及其相应值来描述特定资源。模型定义为:它包含一系列的节点N;它包含一系列属性类P;每一属性都有一定的... 查看详情
openmmlabai实战营打卡笔记——06语义分割算法基础
...营打卡笔记,想要具体了解可以跳转课程视频:语义分割算法基础目录语义分割1.语义分割基本思路2.深度学习下的语义分割模型3.分割模型的评估方法4.语义分割算法总结语义分割这节课对语义分割算法做了详细的介绍&#x... 查看详情
无法读取 Sagemaker 语义分割模型批量转换输出文件
】无法读取Sagemaker语义分割模型批量转换输出文件【英文标题】:NotabletoreadSagemakerSemanticSegmentationModelBatchTransformationOutputfile【发布时间】:2021-02-0923:06:18【问题描述】:目前我已经部署了一个语义分割模型和一个端点,我可以... 查看详情
如何将图像转换为数据集以进行语义分割
】如何将图像转换为数据集以进行语义分割【英文标题】:Howtoconvertimagesintoadatasetforsemanticsegmentation【发布时间】:2021-05-0104:01:09【问题描述】:我正在尝试制作一个新的语义分割模型,该模型将颗粒状显微图像作为输入并对其... 查看详情