关键词:
继续上次的笔记
####判断一个元素是否在列表中
9 in name
print(9 in name) 会返回一个True 或 False 的结果
if 9 in name: #判断一个元素是否在列表中 print("9 is in name")
####判断一个元素出现的次数 count()方法
name =["Alex","Jack","Rain",9,4,3,5,634,34,89,"Eric","Monica","Fiona",3,65,3,2,6,8,2,4,7] if 9 in name: print("9 is in name ") if 9 in name: num_of_ele = name.count(9) print("[%s] 3 is/are in name" % num_of_ele)
####找到某个元素的索引 index() 方法
name = ["Alex","Jack","Rain",9,4,3,5,634,34,89,"Eric","Monica","Fiona",3,65,3,2,6,8,2,4,7] if 9 in name: num_of_ele = name.count(9) posistion_of_ele = name.index(9) #只匹配查找到的一个元素就返回 name[posistion_of_ele] = 999 print("[%s] 9 is/are in name,posistion:[%s]" % (num_of_ele,posistion_of_ele)) for i in range(name.count(9)): ele_index = name.index(9) name[ele_index] = 999 print(name)
####列表扩展 extend
name.extend(name2) 将列表name2 复制到列表name1 后面,可以有重复的元素,复制后列表name2 依然存在。
name = ["Alex","Jack","Rain",9,4,3,5,634,34,89,"Eric","Monica","Fiona",3,65,3,2,6,8,2,4,7] name2 = [‘zhangsan‘,‘LiSi‘,‘ZhaoSha‘,634] name.extend(name2) print(name) print(name2)
执行结果:
[‘Alex‘, ‘Jack‘, ‘Rain‘, 999, 4, 3, 5, 634, 34, 89, ‘Eric‘, ‘Monica‘, ‘Fiona‘, 3, 65, 3, 2, 6, 8, 2, 4, 7, ‘zhangsan‘, ‘LiSi‘, ‘ZhaoSha‘, 634] [‘zhangsan‘,‘LiSi‘,‘ZhaoSha‘,634]
####列表反转 reverse() 方法
name2 = [‘zhangsan‘,‘LiSi‘,‘ZhaoSha‘,‘634‘] name2.reverse() print(name2)
*执行结果*
[‘634‘, ‘ZhaoSha‘, ‘LiSi‘, ‘zhangsan‘]
####列表排序 sort()
**python 2.7 排序。3.0中字符串不能和数字一起排序会报错。**
>>> name = ["Alex","Jack","Rain",9,4,3,5,634,34,89,"Eric","Monica","Fiona",3,65,3,2,6,8,2,4,7] >>> name.sort() >>> print(name) [2, 2, 3, 3, 3, 4, 4, 5, 6, 7, 8, 9, 34, 65, 89, 634, ‘Alex‘, ‘Eric‘, ‘Fiona‘, ‘Jack‘, ‘Monica‘, ‘Rain‘]
**3.0 排序** 将数字转换成字符
name2 = [‘zhangsan‘,‘LiSi‘,‘ZhaoSha‘,‘634‘] name2.sort() print(name2)
*执行结果*
[‘634‘, ‘LiSi‘, ‘ZhaoSha‘, ‘zhangsan‘]
#### 按下标删除元素,并返回 pop()
####列表拷贝 copy()方法
name = [‘zhangsan‘,‘LiSi‘,‘ZhaoSha‘,[1,2,3,4],‘634‘] name2 = name.copy() print(name) print(name2)
*执行结果:*
[‘zhangsan‘, ‘LiSi‘, ‘ZhaoSha‘, [1, 2, 3, 4], ‘634‘] [‘zhangsan‘, ‘LiSi‘, ‘ZhaoSha‘, [1, 2, 3, 4], ‘634‘]
####列表嵌套
**注意:嵌套的列表只是保存了列表的内存入口地址在外层列表中**
如果使用copy()方法 默认只COPY了列表的第一层
name = [‘zhangsan‘,‘LiSi‘,‘ZhaoSha‘,[1,2,3,4],‘634‘] name2 = name.copy() name[0] = "Zhangsan" name[3][2] = 33333333333333 print(name) print(name2)
*执行结果:*
[‘Zhangsan‘, ‘LiSi‘, ‘ZhaoSha‘, [1, 2, 33333333333333, 4], ‘634‘] [‘zhangsan‘, ‘LiSi‘, ‘ZhaoSha‘, [1, 2, 33333333333333, 4], ‘634‘]
**需要完全克隆,需要借助一个标准库copy库来实现**
import copy name = [‘zhangsan‘,‘LiSi‘,‘ZhaoSha‘,[1,2,3,4],‘634‘] name2 = name.copy() name3 = copy.deepcopy(name) name[3][2] = 33333333333333 print(name) print(name2) print("name3",name3)
*执行结果:*
[‘zhangsan‘, ‘LiSi‘, ‘ZhaoSha‘, [1, 2, 33333333333333, 4], ‘634‘] [‘zhangsan‘, ‘LiSi‘, ‘ZhaoSha‘, [1, 2, 33333333333333, 4], ‘634‘] name3 [‘zhangsan‘, ‘LiSi‘, ‘ZhaoSha‘, [1, 2, 3, 4], ‘634‘]
####查看列表长度
len(name4)
**课堂练习**
name = [‘Alex‘,‘jack‘,‘Rain‘,[9,4,3,5,9],634,34,89,9,34]
找出有多少个9,把它改成9999
同时找出所有的34,把它删除
##元租
元组可以理解为只读列表
创建元组
>>> r = (1,2,3,4,5) >>> type(r) <type ‘tuple‘>
两个方法count() index()
##字符串
**常用功能:**
* 移除空白
* 分割
* 长度
* 索引
* 切片
####1 移除空白 strip()
username = input("user:") if username.strip() == ‘alex‘: print("Welcome")
####2 分割
names = "alex,jack,rain" name2 = names.split(",") print(name2)
*执行结果:*
[‘alex‘, ‘jack‘, ‘rain‘]
####字符串合并
names = "alex,jack,rain" name2 = names.split(",") print("|".jion(name2))
*执行结果:*
alex|jack|rain
####判断空格
name = "Alex Li"
print(‘‘ in name)
首字母大写
name = "alex Li"
print(name.capitalize()) #首字母大写
字符串格式化
msg = "Hello, name,it‘s been along age since last time sopke..." msg2 = msg.format(name=‘MingHu‘,age=333) print(msg2)
*执行结果:*
Hello, MingHu,it‘s been along 333 since last time sopke...
另一写法
msg2 = "hahah0,dddd1" print(msg2.format(‘Alex‘,33))
切片
name = "alex li" print(name[2:4])
*执行结果:*
ex
center用法
print(name.center(40,‘-‘))
*执行结果:*
----------------alex li-----------------
find() 方法
name = "alex li" print(name .find(‘l‘)) #找到值返回下标 print(name .find(‘sdfs‘)) #没找到对应值 返回 -1
*执行结果:*
1 -1
判断用户输入是否为数字
age = input("your age:") if age.isdigit(): age = int(age) print(age) else: print("invalid data type")
*执行结果:*
your age:33
33
your age:a
invalid data type
**判断字符串中是否有特殊字符 isalnum()**
ame = ‘alex3*sdf‘ print(name.isalnum()) False name = ‘alex3sdf‘ print(name.isalnum()) True
**判断字符串以什么开始和结束**
startswith()
endswith()
**大小写转换**
upper() 大写
lower() 小写
**数字运算**
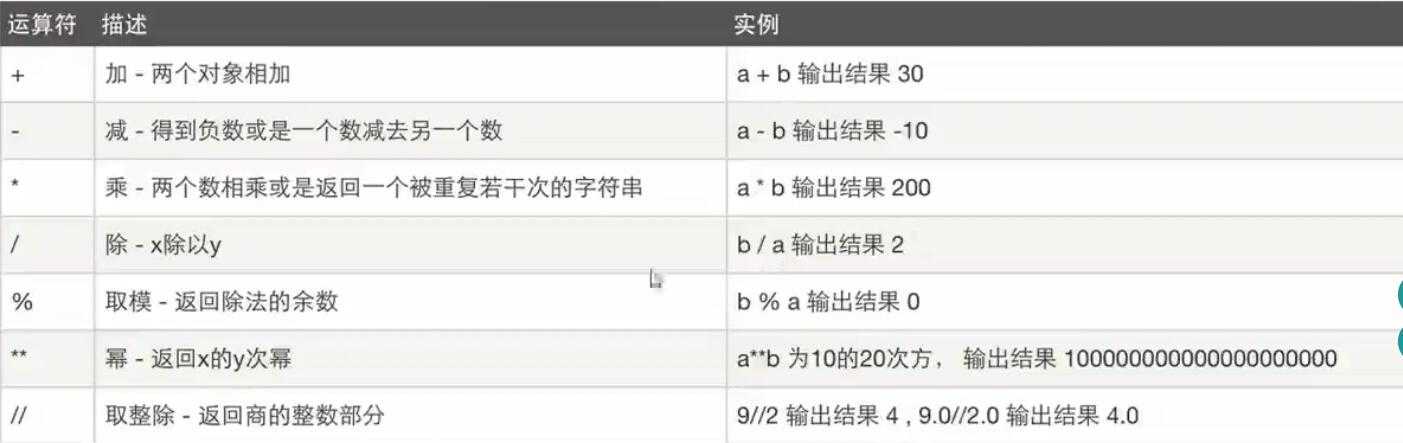
% 返回余数的用法:最简单的求奇偶数的一个用法
**比较运算符**

**赋值运算**
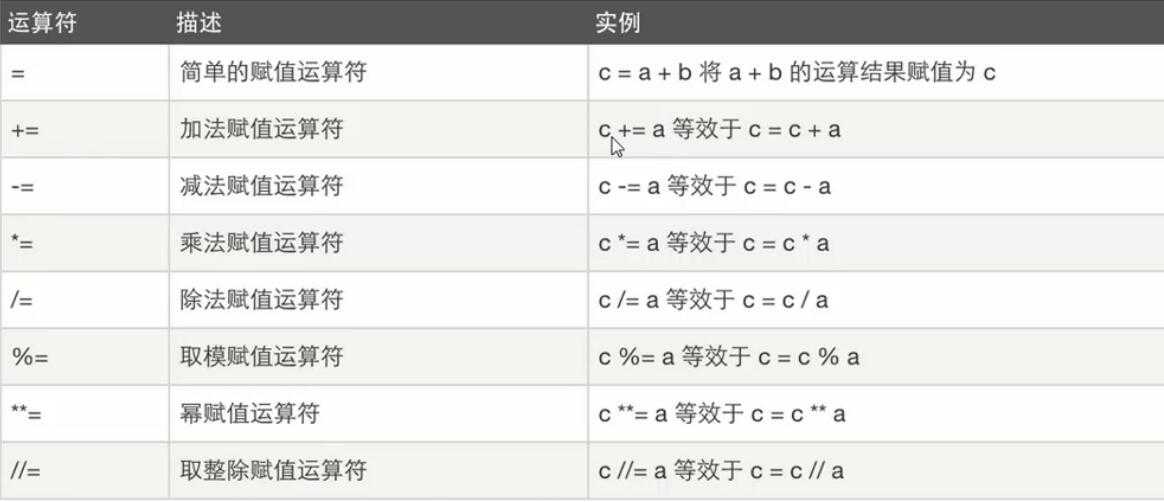
**逻辑运算**

**成员运算**

**身份运算符**

**is 用法**
>>> a = [1,2,3,4] >>> type(a) <type ‘list‘> >>> type(a) is list True
**位运算符**
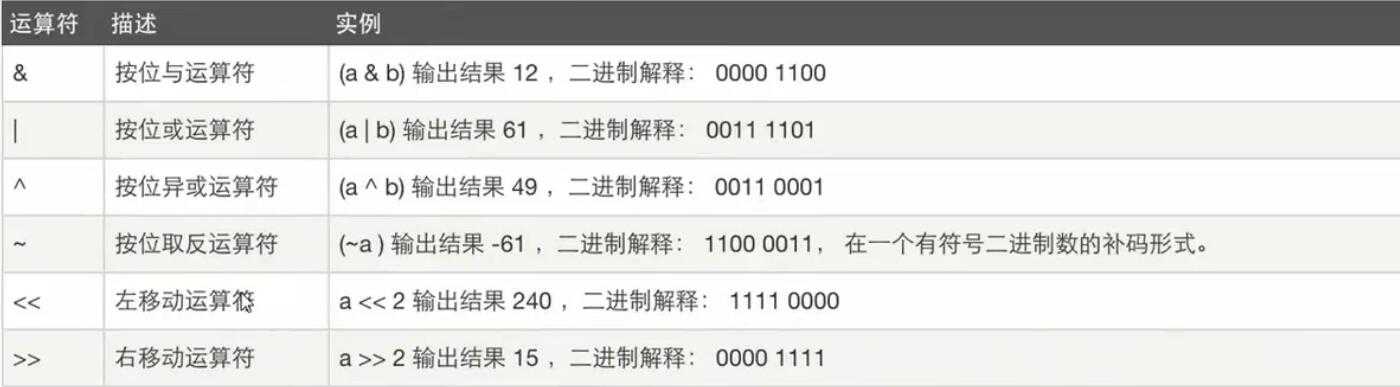
###优先级
###死循环
count =0 while True: print("你是风儿我是沙,缠缠绵绵到天涯",count) count +=1 if count == 100: print("去你妈的风和沙,你们这些脱了裤子是人,穿上裤子是鬼的臭男人..") break
在第50次到60次循环之间不打印
count =0 while True: count +=1 if count > 50 and count <60: continue print("你是风儿我是沙,缠缠绵绵到天涯",count) if count == 100: print("去你妈的风和沙,你们这些脱了裤子是人,穿上裤子是鬼的臭男人..") break
##字典
列表不具备去重的功能,而且操作复杂
字典格式 key:value 结构
id_db = 371471199306143632: ‘name‘:"Alex LI", ‘age‘:20, ‘addr‘:‘shanDong‘, , 220435493306143632: ‘name‘: "ShanPao", ‘age‘: 24, ‘addr‘: ‘DongBei‘, , 220435493306143632: ‘name‘: "DaShanPao", ‘age‘: 24, ‘addr‘: ‘DongBei‘, ,
显示字典内容
print(id_db)
打印某条记录
print(id_db[371471199306143632] )
修改key值
id_db[371471199306143632][‘name‘] = "WangMingHu" #修改已经存在的值 id_db[371471199306143632][‘qq_of_wife‘] = 3823354 #添加一个没有的 key-value id_db[371471199306143632].pop("qq_of_wife") #删除一个key-value
###get() 方法 获取一个key的值
v = id_db .get(371471199306143632) print(v)
*执行结果:*
‘age‘: 20, ‘addr‘: ‘shanDong‘, ‘name‘: ‘Alex LI‘
**注意**
print(id_db[371471199306143632])和 id_db .get(371471199306143632) 如果该键值不存在 直接打印会导致程序报错,而get方法会返回 None
###update 方法
用另一个字段覆盖一个字典
dic2 = ‘name‘: ‘adasdasdasd‘, 220435493306143632: ‘name‘: "WangWang", , id_db.update(dic2) #用dic2 覆盖 id_db 覆盖已经存在的key 添加不存在的key print(id_db)
*执行结果:*
220435493306143631: ‘age‘: 24, ‘addr‘: ‘DongBei‘, ‘name‘: ‘ShanPao‘, 220435493306143632: ‘name‘: ‘WangWang‘, 371471199306143632: ‘age‘: 20, ‘addr‘: ‘shanDong‘, ‘name‘: ‘Alex LI‘, ‘name‘: ‘adasdasdasd‘
items()方法 将字段转换成元组 或 列表 在字典数据量很多的情况下不要这么操作 很耗时
###setdefault()方法
id_db .setdefault() 方法 判断一个key 是否存在于字典中,如过存在就返回,如果不存在就在字典里生成这个key,默认值为None(可以自己指定语法为setdefault(key,"value")
print(id_db .setdefault(371471199306143632))
*执行结果:*
‘age‘: 20, ‘addr‘: ‘shanDong‘, ‘name‘: ‘Alex LI‘
print(id_db .setdefault(37147119930614363200)) print(id_db) *执行结果:* None 220435493306143631: ‘addr‘: ‘DongBei‘, ‘age‘: 24, ‘name‘: ‘ShanPao‘, 220435493306143632: ‘addr‘: ‘DongBei‘, ‘age‘: 24, ‘name‘: ‘DaShanPao‘, 371471199306143632: ‘addr‘: ‘shanDong‘, ‘age‘: 20, ‘name‘: ‘Alex LI‘, 37147119930614363200: None
###fromkeys() 方法
把列表的里每个值拿出来当成字典里的一个key
print(dict .fromkeys([1,2,34,4,5,6],‘dddd‘)) *执行结果:* 1: ‘dddd‘, 2: ‘dddd‘, 4: ‘dddd‘, 5: ‘dddd‘, 6: ‘dddd‘, 34: ‘dddd‘
###popitem()方法
随机删掉个key 并返回这个key的值
print(id_db.popitem()) *执行结果:* (220435493306143631, ‘addr‘: ‘DongBei‘, ‘age‘: 24, ‘name‘: ‘ShanPao‘)
###字典用于循环
方法1:
for k,v in id_db .items(): #效率低,因为要有一个dict to list的转换过程
print(k,v)
方法2:
for key in id_db: #建议使用
print(key,id_db[key])
###购物车练习
# -*- coding:utf-8 -*- #Author:Koala W #shop mall program exercises salary = input("Please input your salary:") if salary.isdigit(): salary = int(salary) else: print("invald data!") exit() welcome_msg = ‘Welcome to Alex Shopping mall‘.center(50,‘-‘) exit_flag = False print(welcome_msg) product_list = [ (‘iphone7‘,5888), (‘MAC pro‘,9888), (‘MAC air‘,7888), (‘XIAOMI 5‘,2499), (‘可口可乐‘,2), (‘IPAD mini‘,3299), (‘Alex Li‘,19.9), (‘Bike‘,700), (‘TOMMIY‘,200), (‘宝马汽车‘,316000),] shop_car = [] while exit_flag is not True: print("product list".center(50,‘-‘)) for item in enumerate(product_list): index = item[0] p_name = item[1][0] p_price = item[1][1] print(index, ‘.‘, p_name, p_price) user_choice = input("[q=quit,c=check]What do you want to buy?:") if user_choice.isdigit(): #输入数字字符必定是选择商品 user_choice = int(user_choice) if user_choice < len(product_list): p_item = product_list[user_choice] if p_item[1]<= salary: #余额是否买得起商品 shop_car.append(p_item) # 放入购物车 salary -= p_item[1] #从余额中扣除商品费用 print("Add [%s] into shop car,you current balance is \033[31;1m[%s]\033[0m" %(p_item,salary)) else: print("Your balance is [%s],cannot afford this.." % salary) else: if user_choice == ‘q‘ or user_choice == ‘quit‘: print("purchased products as below".center(40, ‘*‘)) for item in shop_car: print(item) print("END".center(40, ‘*‘)) print("Your balance is [%s]" % salary) print("Bye!") exit_flag = True elif user_choice == ‘c‘ or user_choice == ‘check‘: print("purchased products as below".center(40, ‘*‘)) for item in shop_car: print(item) print("END".center(40, ‘*‘)) print("Your balance is \033[41;1m[%s]\033[0m" % salary)
python学习第二天(上)(代码片段)
##课前思想###GENTLEMENCODE1* 着装得体* 每天洗澡* 适当用香水* 女士优先* 不随地吐痰、不乱扔垃圾、不在人群众抽烟* 不大声喧哗* 不插队、碰到别人要说抱歉* 不在地铁上吃东西* 尊重别人的职业... 查看详情
python3-基础语法篇(第二天)(代码片段)
本篇博文为Python3零基础学习第二天,本篇博文可以学习到如下知识:1.print输出功能2.input输入功能(包含类型转换)3.字符串的格式化4.range功能5.随机模块random6.流程控制语句(顺序语句,分支语句,循环语句–(while循环,break和continue关键... 查看详情
第二天,ansible源码学习(代码片段)
按照我的理解,源码学习肯定是一边看代码,一边执行程序验证。执行的命令是:ansiblesz003-a"ls-l"下面是ansible.py源码,学习分析以注释的形式出现########################################################from__future__import(absolute_import,divis... 查看详情
社区共读《python编程从入门到实践》第二天阅读建议(代码片段)
...面的数据元素一个个的排好队伍,等待被使用列表是Python中非常重要的一种数据类型这一章节重点学习的内容如下:列表的声明与使用,[]这个符号要熟练;列表的下标,列表的索引, 查看详情
社区共读《python编程从入门到实践》第二天阅读建议(代码片段)
...面的数据元素一个个的排好队伍,等待被使用列表是Python中非常重要的一种数据类型这一章节重点学习的内容如下:列表的声明与使用,[]这个符号要熟练;列表的下标,列表的索引, 查看详情
vue学习第二天------临时笔记(代码片段)
学习链接:vue.js官方文档: https://cn.vuejs.org/v2/guide/index.htmlvue.jsAPI: https://cn.vuejs.org/v2/api/#选项-数据基础案例学习: https://www.mingtern.com/lesson/861068/ 1.使用JavaScript表达式进行运算时,只能使用单个表达式或者链式调... 查看详情
springboot学习:第二天(代码片段)
三、日志1、日志框架小张;开发一个大型系统; 1、System.out.println("");前期将关键数据打印在控制台;去掉?写在一个文件? 2、后来框架来记录系统的一些运行时信息;日志框架;zhanglogging.jar; 3、再后来加高大上... 查看详情
莫烦theano学习自修第二天激励函数(代码片段)
1.代码如下:#!/usr/bin/envpython#!_*_coding:UTF-8_*_importnumpyasnpimporttheano.tensorasTimporttheanox=T.dmatrix(‘x‘)#定义一个激励函数s=1/(1+T.exp(-x))logistic=theano.function([x],s)printlogistic([[0,1],[-2,-3]])# 查看详情
docker的学习第二天(代码片段)
Docker架构图 镜像:image,类似于模板的意思,通过这个模板创建容器服务,如tomcat镜像,---》run--->tomcat1容器,提供给服务器 通过这个镜像可以创建多个容器,最终服务运行或者项目就是在容器中容器:container:Docker... 查看详情
c语言学习第二天(代码片段)
常量字符串常量字符例如:\'f\',\'i\',\'z\',\'a\'编译器为每个字符分配空间。\'f\'\'i\'\'z\'\'a\'字符串例如:"hello"编译器为字符串里的每个字符分配空间以\'\\0\'结束。\'h\'\'e\'\'l\'\'l\'\'o\'\'\\0\'基本类型整数型:shortint,int,longint,longlongin... 查看详情
初识python第二天(代码片段)
一.传递参数2.1新建Python文件,名为hello_args.py,输入以下代码1importsys2print(sys.argv)通过pythonhello_args.py,屏幕打印输出[‘hello_args.py‘]pythonhello_args.pyhelloworld屏幕打印输出[‘hello_args.py‘,‘hello‘,‘world‘]默认文件名本身是argv[0],属... 查看详情
不用看网课就能学到python的文章(第二天)(代码片段)
了解完python的下载不用看网课就能学到python的文章(第一天)_Why_does_it_work的博客-CSDN博客今天正式进入python的学习:python的语法比较简单,首先目录变量type函数了解一下输入与输出关键字运算符变量我们说过编... 查看详情
struts学习之路-第二天(action与servletapi)(代码片段)
Struts作为一款Web框架自然少不了与页面的交互,开发过程中我们最常用的request、application、session等struts都为我们进行了一定的封装与处理一、通过ActionContext获取方法说明voidput(Stringkey,Objectvalue)模拟HttpServletRequest中的setAttribute(... 查看详情
初识python第二天(代码片段)
在Python中,一切事物都是对象,对象是基于类创建的,对象继承了类的属性,方法等。一.传递参数1.1新建python文件,名为twoday_args.py,输出以下代码1importsys2print(sys.argv)34#传入sys模块ViewCode通过pythontwoday_args.py,屏幕打印输出[‘tw... 查看详情
第二天学习进度--文本情感分类(代码片段)
昨天学习了简单的文本处理,之后在课后的练习中实现了包括了对tf-idf的处理和基于朴素贝叶斯简单的文本分类基于tf-idf的数据集在出现多个关键词的时候一般能够相对准确对文本进行分类,但是对于相对具有深层含义的内容,... 查看详情
从零开始学习c语言(第二天)(代码片段)
今天我学习了C语言的常量分为:字面常量、const修饰的常量、#define定义的标识符常量、枚举常量。字符串、strlen、while字面常量:指的是输入程序中的值。表示数字如:3、5、100、3.14.....#include<stdio.h>intmain() inta&... 查看详情
django学习第二天(代码片段)
URL的概念及格式: URL的引入:客户端:知道了url就可以去进行访问; 服务端:设置好了url,别人才能访问到我 URL:网址(全球统一资源定位符);由协议,域名(ipport),路径,参数,锚点等组成 django路由系... 查看详情
学习打卡第二天(代码片段)
1importjava.io.IOException;23publicclassIOTest45publicstaticvoidmain(String[]args)6byte[]buffer=newbyte[1024];7try89intlen=System.in.read(buffer);10Strings=newString(buffer,0,len);11System.out.println("接收到了:"+len+"个字节");12System.out.println(s);13System.out.println("字符串长度为... 查看详情