关键词:
题记:
技术交流群中有小伙伴提及:“es 节点默认1000 个分片的限制”?这引发了我对Elasticsearch 默认值的关注。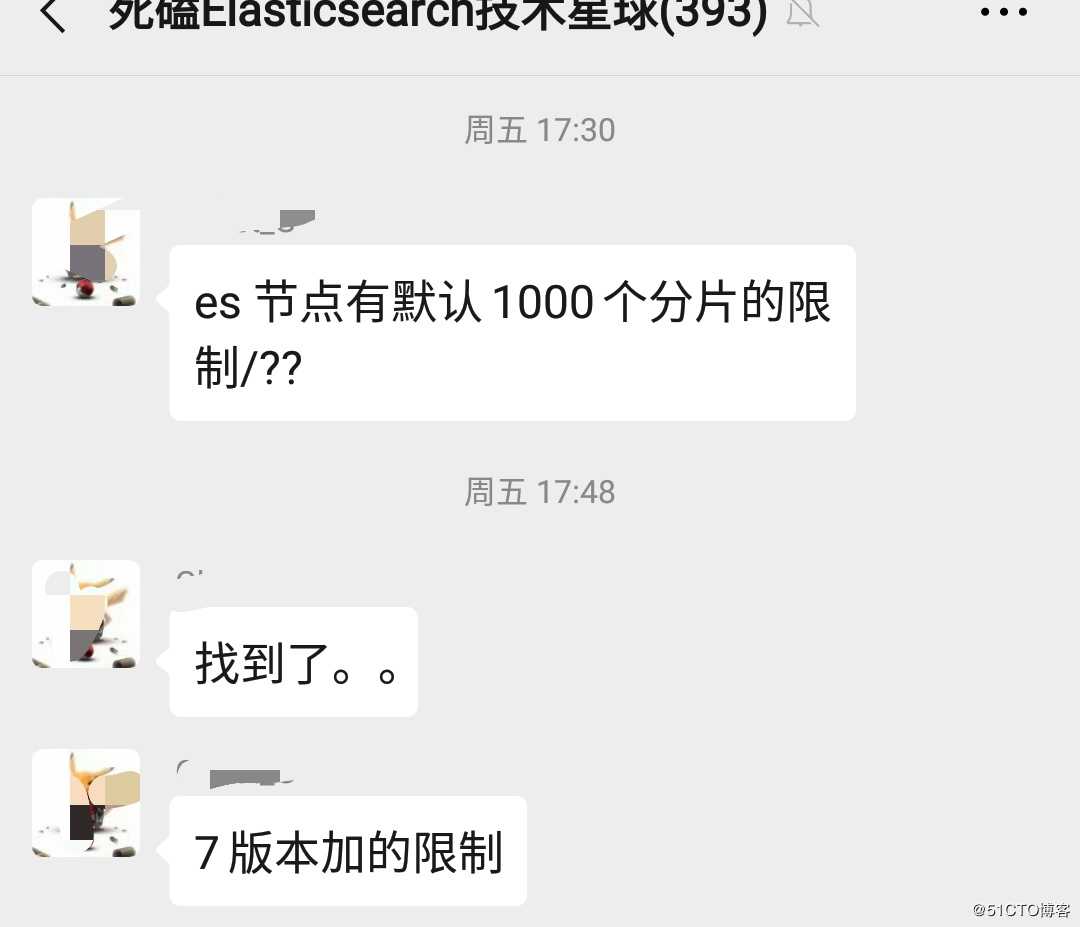
我一搜不要紧:聊天记录中涉及“默认”关键词的讨论接近 400 多处。
这些默认值对于架构选型、开发实战、运维排查性能问题等都有很好的借鉴价值,虽官方文档都有详细论述,但散落在各个角度。
处于本能的好奇心,我认为非常有必要结合自己的实战经历梳理出 Elasticsearch 最常用的默认值的适用场景、参数、默认值大小、静态/动态参数类型、实战建议等知识点。
没别的,让更多人提前建立全局(相对)认知、少走弯路。
0、参数类型以及静态和动态参数的区别?
0.1参数类型
参数类型分为:集群级别参数、索引级别、Maping级别参数等。
0.1.1集群级别参数
举例1 :cluster.max_shards_per_node
前缀是:cluster.*,修改针对集群生效。
举例2:indices.query.bool.max_clause_count
需要在: elasticsearch.yml 配置文件中设置,重启 ES 生效。
0.1.2 索引级别参数
举例:index.number_of_shards
前缀是:index.*,修改针对索引生效。
0.2 区分静态参数和动态参数
Elasticsearch 主分片数在索引创建之后,不可以修改(除非reindex)
index.number_of_shards 是静态参数。
但副本分片数,可以动态的借助:update-index-settings API 任意调整。
index.number_of_replicas 是动态参数。
以下内容分别从:集群层面、索引层面、映射层面、其他常用逐步展开讲解。
1、ES 集群 bool 类型默认支持最大子句个数?
适用场景:N 多子句的bool 组合查询,实现类似规则过滤的功能。
参数:indices.query.bool.max_clause_count。
参数类型:静态参数(需要在elasticsearch.yml 中设置)
默认最大值:1024。
限制原因:为了防止搜索子句过多而占用过多的CPU和内存,导致集群性能下降 。
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-settings.html
2、ES 集群数据节点支持默认分片数个数?
适用场景:大数据量的集群分片选型。
参数:cluster.max_shards_per_node
默认最大值:1000(7.X版本后)。
扩展知识:(1)超大规模集群会遇到这个问题:
1)每个节点可以存储的分片数和可用的堆内存大小成正比关系。
2)Elastic 官方博客文章建议:堆内存和分片的配置比例为1:20,举例:30GB堆内存,最多可有600个分片。
https://www.elastic.co/guide/en/elasticsearch/reference/7.0/misc-cluster.html#cluster-shard-limit
https://github.com/elastic/kibana/issues/35529
(2)不合理分配可能问题:
1)分片数量过多,写入放大,导致 bulk queue打满,拒绝率上升;
2)一定数据量级后,分片数量过少,无法充分利用多节点资源,机器资源不均衡。
3、ES 集群 index_buffer 默认比例是多少?
适用场景:堆内存中索引缓冲区用于存储新索引的文档。填满后,缓冲区中的文档将写入磁盘上的某个段。它在节点上的所有分片之间划分。
参数:
(1) indices.memory.index_buffer_size
(2) indices.memory.min_index_buffer_size
(3) indices.memory.max_index_buffer_size
参数类型:静态参数(需要在elasticsearch.yml 中设置)
默认值:
(1)indices.memory.index_buffer_size: 10%
(2)indices.memory.min_index_buffer_size : 48 Mb
使用建议:
(1)必须在集群中的每个数据节点上进行配置。
(2)写入优化中首选的优化参数之一,有助于提高写入性能和稳定性。
https://www.elastic.co/guide/en/elasticsearch/reference/current/indexing-buffer.html
4、ES 默认磁盘使用率 85% 不再支持写入数据吗?
适用场景:基于磁盘分配分片的参数之一,控制磁盘的使用率低警戒水位线值。
参数:cluster.routing.allocation.disk.watermark.low/high/flood_stage
默认值
(1)cluster.routing.allocation.disk.watermark.low:85%
(2)cluster.routing.allocation.disk.watermark.high:90%
(3)cluster.routing.allocation.disk.watermark.flood_stage:95%
参数类型:集群动态参数
使用建议
(1)85%:禁止写入;90%:索引分片迁移到其他可用节点;95%:索引只读。
(2)磁盘使用率也是监控的一个核心指标之一。
5、ES 集群 默认的 gc 方式?
适用场景:写入到可搜索的最小时间间隔(单位s)。
默认参数:
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=75
-XX:+UseCMSInitiatingOccupancyOnly
使用建议
(1)官方建议:
目前,我们仍然认为CMS垃圾收集器是大多数部署的最佳选择,但是自ES 6.5.0(如果在JDK 11或更高版本上运行)以来,我们现在也支持G1GC。
https://github.com/elastic/elasticsearch/issues/44321
(2)配置位置:jvm.options, 优化参考 wood 大叔建议:更改为
-XX:+UseG1GC
-XX:MaxGCPauseMillis=50
其中 -XX:MaxGCPauseMillis 是控制预期的最高GC时长,默认值为 200ms ,如果线上业务特性对于GC停顿非常敏感,可以适当设置低一些。但是 这个值如果设置过小,可能会带来比较高的cpu消耗。
G1 对于集群正常运作的情况下减轻 G1 停顿对服务时延的影响还是很有效的,但是如果是 GC 导致集群卡死,那么很有可能换G1 也无法根本上解决问题。通常都是集群的数据模型或者 Query 需要优化。
https://elasticsearch.cn/question/4589
6、ES 索引默认主分片分片大小?
适用场景:数据存储。
参数:index.number_of_shards
参数类型:静态参数。
默认值:1(7.X版本,早期版本是5);单索引最大支持分片数:1024。
使用建议:
(1)只能在创建索引时设置此值。
(2)单索引1024个最大分片数的限制是一项安全限制,可防止因资源分配问题导致集群不稳定。
(3)可通过在每个节点上指定export ES_JAVA_OPTS =“-Des.index.max_number_of_shards = 128”系统属性来修改此限制。
7、ES 索引默认压缩算法是?
适用场景:写入数据压缩。
参数:index.codec
参数类型:静态参数。
默认值:LZ4
使用建议:
(1)可以将其设置为best_compression,它使用DEFLATE以获得更高的压缩率,但代价是存储字段的性能较慢。
(2)不追求压缩效率,追求磁盘占用比低的用户推荐 best_compression 压缩。
8、ES 索引默认副本分片数?
适用场景:确保业务数据的高可用性。
参数:index.number_of_replicas
参数类型:动态参数
默认值:1
使用建议:
根据业务需要合理设置副本,基于数据安全性考虑,建议副本至少设置1。
9、ES 索引默认的刷新频率?
适用场景:写入到可搜索的最小时间间隔(单位s)。
参数:index.refresh_interval
参数类型:动态参数。
默认最小值:1s。
使用建议:对于实时性要求不高且想优化写入的业务场景,建议根据业务实际调大刷新频率。
10、ES 索引 terms 默认最大支持的长度是?
适用场景:Terms query。
参数:index.max_terms_count
参数类型:动态参数
默认最大值:65536
使用建议:一般不会超过此最大值。
11、ES 索引默认分页返回最大条数?
适用场景:搜索的深度翻页。
参数:index.max_result_window
参数类型:动态参数。
默认最大值:10000。
使用建议:
(1)深度翻页的机制,决定了越往后越慢。除非特殊业务需求,不建议修改默认值,可以参考百度和google的实现。
(2)全部数据遍历推荐scroll API。仅支持向后翻页推荐:Search After API。
12、ES 索引默认管道有必要设置吗?
适用场景:索引默认写入数据环节加上 ETL 操作。
参数:index.default_pipeline
参数类型:动态参数
默认值:自定义管道
使用建议:
(1)结合实际业务需要,一些基础需要ETL的功能建议加上。
(2)如果不加index.default_pipeline也可以,update_by_query + 自定义 pipeline 结合也能实现。不过(1)是更周全、简练的方案。
13、ES 索引 Mapping 默认支持最大字段数?
使用场景:防止索引Maping 横向无限增大,导致内存泄露等异常。
参数:index.mapping.total_fields.limit
参数类型:动态参数
默认最大值:1000
使用建议;不建议修改
14、ES 索引 Mapping字段默认的最大深度?
使用场景:防止索引Maping 纵向无限增大,导致异常。
参数:index.mapping.depth.limit
参数类型:动态参数
默认最大值:20
使用建议;不建议修改
计算依据:例如,如果所有字段都在根对象级别定义,则深度为1。如果有一个对象映射,则深度为2,依此类推。默认值为20。
15、ES 索引 Mapping nested 默认支持大小?
适用场景:nested 类型选型。
参数:
(1)index.mapping.nested_fields.limit
一个索引最大支持的nested类型个数
(2)index.mapping.nested_objects.limit
一个nested类型支持的最大对象数
参数类型:动态参数(已验证)
默认值:
(1)index.mapping.nested_fields.limit : 50
(2)index.mapping.nested_objects.limit : 10000
使用建议:
(1)nested 的可能的性能问题不容小觑。
nested本质:每个嵌套对象都被索引为一个单独的Lucene文档。如果我们为包含100个用户对象的单个文档建立索引,则将创建101个Lucene文档。
(2) nested 较 父子文档不同之处:
如果子文档频繁更新,建议使用父子文档。
如果子文档不频繁更新,查询频繁建议 nested类型。
16、ES 索引动态Mapping条件下,匹配的字符串默认匹配的是?
适用场景:不提前设置Mapping精准字段的场景。
默认类型:text + keyword类型。
实战举例如下:
"my_index_0001" :
"mappings" :
"properties" :
"cont" :
"type" : "text",
"fields" :
"keyword" :
"type" : "keyword",
"ignore_above" : 256
实际建议:建议结合业务需要,提前精准设置Mapping,并优化数据建模。
17、ES 默认的评分机制是?
默认值:BM 25
除非业务需要,否则不建议修改。https://www.elastic.co/guide/en/elasticsearch/reference/current/similarity.html
18、ES keyword类型默认支持的字符数是多少?
1)ES5.X版本以后,keyword支持的最大长度为32766个UTF-8字符,text对字符长度没有限制。
2)设置ignore_above后,超过给定长度后的数据将不被索引,无法通过term精确匹配检索返回结果。
https://blog.csdn.net/laoyang360/article/details/78207980
19、为什么说,ES 默认不适用别名,不算入门ES?
一句话概括:别名可以零停机改造(经典技巧,无缝切换)。https://www.elastic.co/guide/en/elasticsearch/reference/6.8/indices-aliases.html
20、ES 集群节点默认属性值?
默认:候选主节点、数据节点、Ingest节点、协调节点、机器学习节点(如果付费)的角色。
建议:集群规模到达一定量级后,一定要独立设置专有的主节点、协调节点、数据节点。角色划分清楚。
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html
21、ES客户端请求的节点默认是?
如果不明确指定协调节点,默认请求的节点充当协调节点的角色。
每个节点都隐式地是一个协调节点。协调节点:需要具有足够的内存和CPU才能处理收集阶段。
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-node.html
22、ES 默认分词器?
适用场景:不明确指定分词器的场景。
默认类型:analyzer 分词器。
实战举例如下:
POST /_analyze
"text": "屹立在东方之林",
"analyzer": "standard"
切分结果:
屹
立
在
东
方
之
林
实战建议:_analyze API 在解决分词问题中的作用巨大!
23、ES 聚合默认UTC时间,可以修改吗?
可以聚合时候修改,设置时区 time_zone即可解决。
"+08:00": 代表东8区。
GET my_index/_search?size=0
"aggs":
"by_day":
"date_histogram":
"field": "date",
"calendar_interval": "day",
"time_zone": "+08:00"
24、ES 默认堆内存大小?
默认值:2gB,建议一定结合实际机器环境修改。
ES 建议独立机器环境部署,不和其他进程:如logstash,hadoop,redis等共享机器资源。
JVM设置建议:min(31GB, 机器内存的一半)
25、ES JDK 什么版本开始默认自带的?
7.0 版本。7.0 版本之后开始默认捆绑了 JDK(安装包里自带JDK),因此我们可以不单独安装 JDK。
小结
没有别的,我就是好奇!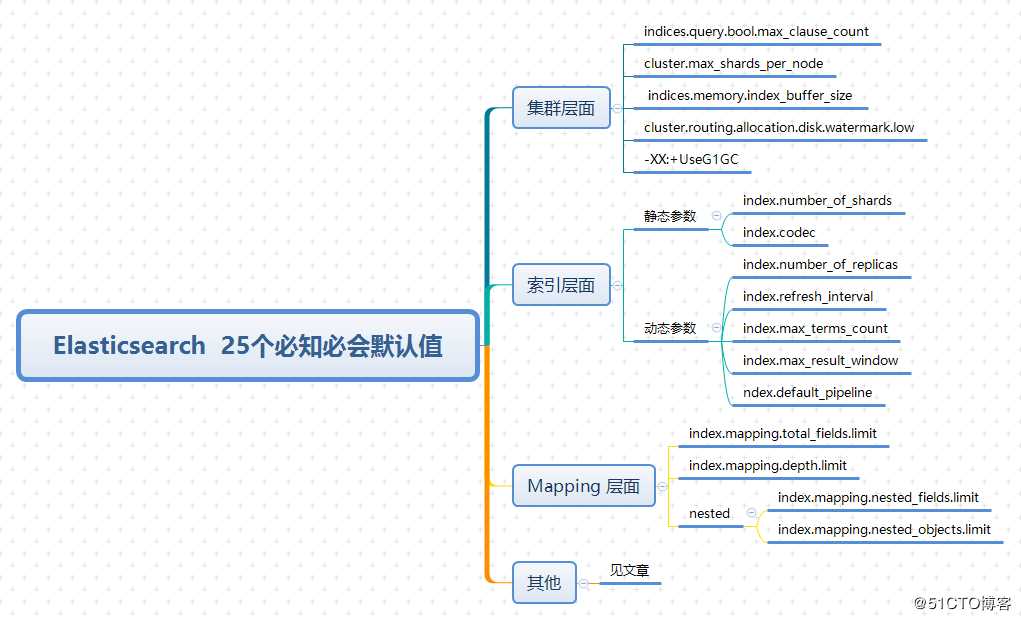
大而全的建议参考官方文档,上述25个默认值都是死磕Elasticsearch交流群中提到的实战问题。
10个必知必会的统计学问题
...么?假设检验的内涵和步骤?这篇文章带你来看10个必知必会的统计学问题。正文来源:计量经济学1、问:自由度是什么?怎样确定?答:ÿ 查看详情
省时提效!5个必知必会的sql窗口函数!(代码片段)
SQL是数据世界中的通用语言,是作为数据科学人员必备技能。它之所以如此重要,是因为许多数据探索、数据操作、管道开发和仪表板创建都是通过SQL完成的。想要利用SQL高效处理数据任务,掌握一些窗口函数非常有... 查看详情
5个必知必会的python数据合并技巧(代码片段)
大家好,前不久在我们技术交流群有群友提到最近他面试阿里70万总包的数据岗位,对方问Pandas的5种数据合并的函数,结果他只答出了2个。那么,究竟是哪五个呢?今天,我们就来带大家了解一下!想... 查看详情
elasticsearch必知必会的干货知识二:es索引操作技巧(代码片段)
该系列上一篇文章《Elasticsearch必知必会的干货知识一:ES索引文档的CRUD》讲了如何进行index的增删改查,本篇则侧重讲解说明如何对index进行创建、更改、迁移、查询配置信息等。仅创建索引:PUTindexPUT/index添加字段设置(mappings... 查看详情
架构实践架构师必知必会的5种业界主流的架构风格
【架构实践】架构师必知必会的5种业界主流的架构风格目录 【架构实践】架构师必知必会的5种业界主流的架构风格 查看详情
架构实践架构师必知必会的5种业界主流的架构风格
【架构实践】架构师必知必会的5种业界主流的架构风格目录 【架构实践】架构师必知必会的5种业界主流的架构风格 查看详情
tcp/ip,必知必会的
...TCP拥塞控制 0前言本文整理了一些TCP/IP协议簇中需要必知必会的十大问题,既是面试高频问题,又是程序员必备基础素养。 1TCP/IP模型TCP/IP协议模型(TransmissionControlProtocol/InternetProtocol 查看详情
必知必会的设计原则——合成复用原则(代码片段)
设计原则系列文章 必知必会的设计原则——单一职责原则必知必会的设计原则——开放封闭原则必知必会的设计原则——依赖倒置原则必知必会的设计原则——里氏替换原则必知必会的设计原则——接口隔离原则必知必... 查看详情
6个必知必会高效python编程技巧
编写更好的Python代码需要遵循Python社区制定的最佳实践和指南。遵守这些标准可以使您的代码更具可读性、可维护性和效率。本文将展示一些技巧,帮助您编写更好的Python代码文章目录遵循PEP8风格指南1.遵守PEP8命名约定2.使... 查看详情
大数据必知必会的-linux命令(代码片段)
用户的创建和删除命令用户创建和密码设置useradd用户名passwd用户名useradditheima#创建新用户itheimapasswditheima#设置用户itheima密码用户删除user-r用户名userdel-ritheima#删除用户itheima权限管理命令文件权限概述Linux操作系统是多任务多用... 查看详情
大数据必知必会的-linux命令(代码片段)
用户的创建和删除命令用户创建和密码设置useradd用户名passwd用户名useradditheima#创建新用户itheimapasswditheima#设置用户itheima密码用户删除user-r用户名userdel-ritheima#删除用户itheima权限管理命令文件权限概述Linux操作系统是多任务多用... 查看详情
zookeeper必知必会的知识点
ZooKeeper是什么?ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,它是集群的管理者,监视着集群中各个节点的状态根据节点提交的反馈进行下一步合理操作。最终,将简单易用的接... 查看详情
大数据必知必会的-linux命令(代码片段)
终端命令格式command[-options][parameter]说明:command:命令名,相应功能的英文单词或单词的缩写[-options]:选项,可用来对命令进行控制,也可以省略parameter:传给命令的参数,可以是零个、一个或者多个显示文件列表命令ls是英文单词list的简... 查看详情
大数据必知必会的-linux命令(代码片段)
终端命令格式command[-options][parameter]说明:command:命令名,相应功能的英文单词或单词的缩写[-options]:选项,可用来对命令进行控制,也可以省略parameter:传给命令的参数,可以是零个、一个或者多个显示文件列表命令ls是英文单词list的简... 查看详情
大数据必知必会的-linux命令(代码片段)
文件操作命令touch命令touch命令创建文件touch文件路径toucha.txt#在当前目录创建a.txt文件touch/root/a.txt#在/root目录创建a.txt文件mv命令通过mv命令可以用来移动文件或目录,也可以给文件或目录重命名1)将文件移动另一个目录中... 查看详情
flink必知必会的重要基本知识
一、Flink基本知识1.1、Flink介绍ApacheFlink是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态计算。Flink官网:https://flink.apache.org/Flink的中文官网:https://flink.apache.org/zh/1.2、有界与无界1.2.1、有界数据... 查看详情
flink必知必会的重要基本知识
一、Flink基本知识1.1、Flink介绍ApacheFlink是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态计算。Flink官网:https://flink.apache.org/Flink的中文官网:https://flink.apache.org/zh/1.2、有界与无界1.2.1、有界数据... 查看详情
必知必会的目录和文件的作用安装软件方法运行级别
作者:Georgekai归档:学习笔记2017/12/28 目 录第1章 ctrl+11 1.2 /etc/目录1 1.2.1 网卡配置文件和DNS配 查看详情