关键词:
该文章是基于 Hadoop2.7.6_01_部署 进行的
Flume官方文档:FlumeUserGuide
常见问题:记flume部署过程中遇到的问题以及解决方法(持续更新)
1. 前言
在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集、结果数据导出、任务调度等不可或缺的辅助系统,而这些辅助工具在hadoop生态体系中都有便捷的开源框架,如图所示:

2. Flume介绍
2.1. 概述
- Flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。
- Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到HDFS、hbase、hive、kafka等众多外部存储系统中
- 一般的采集需求,通过对flume的简单配置即可实现
- Flume针对特殊场景也具备良好的自定义扩展能力,因此,flume可以适用于大部分的日常数据采集场景
2.2. 运行机制
1、 Flume分布式系统中最核心的角色是agent,flume采集系统就是由一个个agent所连接起来形成
2、 每一个agent相当于一个数据传递员,内部有三个组件:
注意:Source 到 Channel 到 Sink之间传递数据的形式是Event事件;Event事件是一个数据流单元。
a) Source:采集源,用于跟数据源对接,以获取数据
b) Sink:下沉地,采集数据的传送目的,用于往下一级agent传递数据或者往最终存储系统传递数据
c)Channel:angent内部的数据传输通道,用于从source将数据传递到sink

3. Flume采集系统结构图
3.1. 简单结构
单个agent采集数据

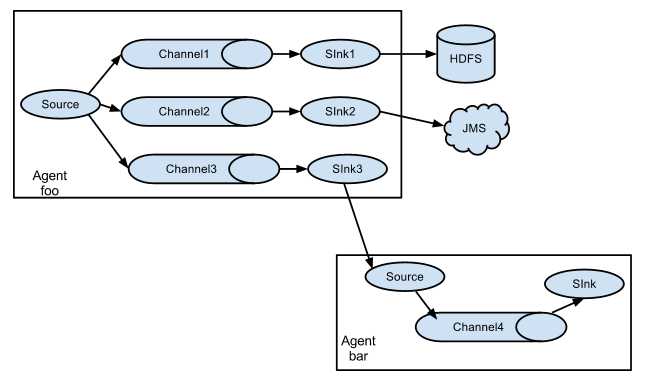
3.2. 复杂结构
多级agent之间串联

4. Flume的安装部署
4.1. 软件部署
1 [[email protected] software]$ pwd 2 /app/software 3 [[email protected] software]$ tar xf apache-flume-1.8.0-bin.tar.gz 4 [[email protected] software]$ mv apache-flume-1.8.0-bin /app/flume-1.8.0 5 [[email protected] software]$ cd /app/ 6 [[email protected] ~]$ ln -s flume-1.8.0 flume # 建立软连接 7 [[email protected] ~]$ ll 8 total 28 9 lrwxrwxrwx 1 yun yun 11 Jul 25 21:54 flume -> flume-1.8.0 10 drwxrwxr-x 7 yun yun 187 Jul 25 21:53 flume-1.8.0 11 ………………
4.2. 环境变量
1 [[email protected] profile.d]# pwd 2 /etc/profile.d 3 [[email protected] profile.d]# cat flume.sh 4 export FLUME_HOME="/app/flume" 5 export PATH=$FLUME_HOME/bin:$PATH 6 [[email protected] profile.d]# logout 7 [[email protected] ~]$ source /etc/profile # 环境变量生效
5. 采集案例
5.1. 简单案例——从网络端口接收数据下沉到logger
配置文件
1 [[email protected] conf]$ pwd 2 /app/flume/conf 3 [[email protected] conf]$ ll 4 total 20 5 -rw-r--r-- 1 yun yun 1661 Sep 15 2017 flume-conf.properties.template 6 -rw-r--r-- 1 yun yun 1455 Sep 15 2017 flume-env.ps1.template 7 -rw-r--r-- 1 yun yun 1568 Sep 15 2017 flume-env.sh.template 8 -rw-r--r-- 1 yun yun 3107 Sep 15 2017 log4j.properties 9 -rw-rw-r-- 1 yun yun 741 Jul 25 22:12 netcat-logger.conf 10 [[email protected] conf]$ cat netcat-logger.conf 11 # Name the components on this agent 12 a1.sources = r1 13 a1.sinks = k1 14 a1.channels = c1 15 16 # Describe/configure the source 17 a1.sources.r1.type = netcat 18 a1.sources.r1.bind = localhost 19 a1.sources.r1.port = 44444 20 # bind = localhost 绑定的是本地端口 21 22 # Describe the sink 23 a1.sinks.k1.type = logger 24 25 # Use a channel which buffers events in memory 26 #下沉的时候是一批一批的, 下沉的时候是一个个eventChannel参数解释: 27 #capacity:默认该通道中最大的可以存储的event数量 28 #trasactionCapacity:每次最大可以从source中拿到或者送到sink中的event数量 29 a1.channels.c1.type = memory 30 a1.channels.c1.capacity = 1000 31 a1.channels.c1.transactionCapacity = 100 32 33 # Bind the source and sink to the channel 34 a1.sources.r1.channels = c1 35 a1.sinks.k1.channel = c1
flume启动
1 [[email protected] conf]$ pwd 2 /app/flume/conf 3 # 其中--conf-file 指定的配置文件可以为相对路径也可以是绝对路径 4 [[email protected] conf]$ flume-ng agent --conf conf --conf-file netcat-logger.conf --name a1 -Dflume.root.logger=INFO,console 5 ……………… 6 18/07/25 22:19:23 INFO node.Application: Starting Channel c1 7 18/07/25 22:19:23 INFO instrumentation.MonitoredCounterGroup: Monitored counter group for type: CHANNEL, name: c1: Successfully registered new MBean. 8 18/07/25 22:19:23 INFO instrumentation.MonitoredCounterGroup: Component type: CHANNEL, name: c1 started 9 18/07/25 22:19:23 INFO node.Application: Starting Sink k1 10 18/07/25 22:19:23 INFO node.Application: Starting Source r1 11 18/07/25 22:19:23 INFO source.NetcatSource: Source starting 12 18/07/25 22:19:23 INFO source.NetcatSource: Created serverSocket:sun.nio.ch.ServerSocketChannelImpl[/127.0.0.1:44444]
source端的Telnet输入
1 [[email protected] ~]$ telnet localhost 44444 2 Trying ::1... 3 telnet: connect to address ::1: Connection refused 4 Trying 127.0.0.1... 5 Connected to localhost. 6 Escape character is ‘^]‘. 7 111 8 OK 9 222 10 OK 11 334334634geg 12 OK 13 gwegweg 14 OK 15 ^] 16 telnet> quit 17 Connection closed.
当在Telnet端输入,logger显示
1 18/07/25 22:20:09 INFO sink.LoggerSink: Event: headers: body: 31 31 31 0D 111. 2 18/07/25 22:20:10 INFO sink.LoggerSink: Event: headers: body: 32 32 32 0D 222. 3 18/07/25 22:20:13 INFO sink.LoggerSink: Event: headers: body: 33 33 34 33 33 34 36 33 34 67 65 67 0D 334334634geg. 4 18/07/25 22:20:14 INFO sink.LoggerSink: Event: headers: body: 67 77 65 67 77 65 67 0D gwegweg.
5.2. 监视文件夹——下沉到logger
配置文件
1 [[email protected] conf]$ pwd 2 /app/flume/conf 3 [[email protected] conf]$ ll 4 total 20 5 -rw-r--r-- 1 yun yun 1661 Sep 15 2017 flume-conf.properties.template 6 -rw-r--r-- 1 yun yun 1455 Sep 15 2017 flume-env.ps1.template 7 -rw-r--r-- 1 yun yun 1568 Sep 15 2017 flume-env.sh.template 8 -rw-r--r-- 1 yun yun 3107 Sep 15 2017 log4j.properties 9 -rw-rw-r-- 1 yun yun 741 Jul 25 22:12 netcat-logger.conf 10 -rw-rw-r-- 1 yun yun 597 Jul 25 22:29 spooldir-logger.conf 11 [[email protected] conf]$ cat spooldir-logger.conf 12 # Name the components on this agent 13 a1.sources = r1 14 a1.sinks = k1 15 a1.channels = c1 16 17 # Describe/configure the source 18 #监听目录,spoolDir指定目录, fileHeader要不要给文件夹前坠名 19 a1.sources.r1.type = spooldir 20 a1.sources.r1.spoolDir = /app/software/flume 21 a1.sources.r1.fileHeader = true 22 23 # Describe the sink 24 a1.sinks.k1.type = logger 25 26 # Use a channel which buffers events in memory 27 a1.channels.c1.type = memory 28 a1.channels.c1.capacity = 1000 29 a1.channels.c1.transactionCapacity = 100 30 31 # Bind the source and sink to the channel 32 a1.sources.r1.channels = c1 33 a1.sinks.k1.channel = c1
flume启动
1 [[email protected] conf]$ pwd 2 /app/flume/conf 3 [[email protected] conf]$ flume-ng agent --conf conf --conf-file spooldir-logger.conf --name a1 -Dflume.root.logger=INFO,console 4 ……………… 5 18/07/25 23:01:04 INFO instrumentation.MonitoredCounterGroup: Component type: CHANNEL, name: c1 started 6 18/07/25 23:01:04 INFO node.Application: Starting Sink k1 7 18/07/25 23:01:04 INFO node.Application: Starting Source r1 8 18/07/25 23:01:04 INFO source.SpoolDirectorySource: SpoolDirectorySource source starting with directory: /app/software/flume 9 18/07/25 23:01:04 INFO instrumentation.MonitoredCounterGroup: Monitored counter group for type: SOURCE, name: r1: Successfully registered new MBean. 10 18/07/25 23:01:04 INFO instrumentation.MonitoredCounterGroup: Component type: SOURCE, name: r1 started
往/app/software/flume目录加入文件
1 # 原文件目录 2 [[email protected] hive]$ pwd 3 /app/software/hive 4 [[email protected] hive]$ ll 5 total 48 6 -rw-rw-r-- 1 yun yun 71 Jul 12 21:53 t_sz01.dat 7 -rw-rw-r-- 1 yun yun 71 Jul 12 21:53 t_sz01.dat2 8 -rw-rw-r-- 1 yun yun 79 Jul 12 22:15 t_sz02_ext.dat 9 -rw-rw-r-- 1 yun yun 52 Jul 12 23:09 t_sz03_20180711.dat1 10 -rw-rw-r-- 1 yun yun 52 Jul 12 23:09 t_sz03_20180711.dat2 11 -rw-rw-r-- 1 yun yun 52 Jul 12 23:09 t_sz03_20180712.dat1 12 -rw-rw-r-- 1 yun yun 52 Jul 12 23:09 t_sz03_20180712.dat2 13 -rw-rw-r-- 1 yun yun 753 Jul 14 10:36 t_sz05_buck.dat 14 -rw-rw-r-- 1 yun yun 507 Jul 14 10:07 t_sz05_buck.dat.bak 15 [[email protected] hive]$ cp -a t_access_times.dat t_sz01.dat t_sz01.dat2 ../flume/ 16 [[email protected] hive]$ cp -a t_sz05_buck.dat t_sz05_buck.dat2 ../flume/ 17 ############################################ 18 # 对应的flume目录 注意文件名不能重复,否则flume会报错,也不能是一个目录 19 [[email protected] flume]$ pwd 20 /app/software/flume 21 [[email protected] flume]$ ll 22 total 20 23 -rw-rw-r-- 1 yun yun 288 Jul 18 14:20 t_access_times.dat.COMPLETED 24 -rw-rw-r-- 1 yun yun 71 Jul 12 21:53 t_sz01.dat2.COMPLETED 25 -rw-rw-r-- 1 yun yun 71 Jul 12 21:53 t_sz01.dat.COMPLETED 26 -rw-rw-r-- 1 yun yun 753 Jul 14 10:36 t_sz05_buck.dat 27 -rw-rw-r-- 1 yun yun 753 Jul 14 10:36 t_sz05_buck.dat.COMPLETED
5.3. 用tail命令获取数据,下沉到HDFS
配置文件
1 [[email protected] conf]$ pwd 2 /app/flume/conf 3 [[email protected] conf]$ ll 4 total 28 5 -rw-r--r-- 1 yun yun 1661 Sep 15 2017 flume-conf.properties.template 6 -rw-r--r-- 1 yun yun 1455 Sep 15 2017 flume-env.ps1.template 7 -rw-r--r-- 1 yun yun 1568 Sep 15 2017 flume-env.sh.template 8 -rw-r--r-- 1 yun yun 3107 Sep 15 2017 log4j.properties 9 -rw-rw-r-- 1 yun yun 741 Jul 25 22:12 netcat-logger.conf 10 -rw-rw-r-- 1 yun yun 593 Jul 25 22:30 spooldir-logger.conf 11 -rw-rw-r-- 1 yun yun 1275 Jul 25 23:29 tail-hdfs.conf 12 [[email protected] conf]$ cat tail-hdfs.conf 13 # Name the components on this agent 14 a1.sources = r1 15 a1.sinks = k1 16 a1.channels = c1 17 18 # Describe/configure the source 19 a1.sources.r1.type = exec 20 a1.sources.r1.command = tail -F /app/webservice/logs/access.log 21 a1.sources.r1.channels = c1 22 23 # Describe the sink 24 a1.sinks.k1.type = hdfs 25 a1.sinks.k1.channel = c1 26 a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/ 27 a1.sinks.k1.hdfs.filePrefix = events- 28 # 以下3项表示每隔10分钟切换目录存储 29 a1.sinks.k1.hdfs.round = true 30 a1.sinks.k1.hdfs.roundValue = 10 31 a1.sinks.k1.hdfs.roundUnit = minute 32 # 滚动当前文件前等待的秒数 33 a1.sinks.k1.hdfs.rollInterval = 30 34 # 文件大小以字节为单位触发滚动 35 a1.sinks.k1.hdfs.rollSize = 1024 36 # 在滚动之前写入文件的事件数 37 a1.sinks.k1.hdfs.rollCount = 500 38 # 在它被刷新到HDFS之前写入文件的事件数量。100个事件为一个批次 39 a1.sinks.k1.hdfs.batchSize = 100 40 a1.sinks.k1.hdfs.useLocalTimeStamp = true 41 #生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本 42 a1.sinks.k1.hdfs.fileType = DataStream 43 44 # Use a channel which buffers events in memory 45 a1.channels.c1.type = memory 46 a1.channels.c1.capacity = 1000 47 a1.channels.c1.transactionCapacity = 100 48 49 # Bind the source and sink to the channel 50 a1.sources.r1.channels = c1 51 a1.sinks.k1.channel = c1
flume启动
1 [[email protected] conf]$ flume-ng agent -c conf -f tail-hdfs.conf -n a1
启动jar包打印日志
1 [[email protected] webservice]$ pwd 2 /app/webservice 3 [[email protected] webservice]$ java -jar testlog.jar &
可参见:Hadoop2.7.6_02_HDFS常用操作 ----- 3.3. web日志模拟
浏览器查看flume下沉的数据


5.4. 级联下沉到HDFS
由mini01 的flume发送数据到mini02的flume,然后由mini02的flume下沉到HDFS。
其中mini02的flume安装过程略。
配置文件mini01
1 [[email protected] conf]$ pwd 2 /app/flume/conf 3 [[email protected] conf]$ ll 4 total 32 5 -rw-r--r-- 1 yun yun 1661 Sep 15 2017 flume-conf.properties.template 6 -rw-r--r-- 1 yun yun 1455 Sep 15 2017 flume-env.ps1.template 7 -rw-r--r-- 1 yun yun 1568 Sep 15 2017 flume-env.sh.template 8 -rw-r--r-- 1 yun yun 3107 Sep 15 2017 log4j.properties 9 -rw-rw-r-- 1 yun yun 741 Jul 25 22:12 netcat-logger.conf 10 -rw-rw-r-- 1 yun yun 593 Jul 25 22:30 spooldir-logger.conf 11 -rw-rw-r-- 1 yun yun 789 Jul 26 22:31 tail-avro-avro-logger.conf 12 -rw-rw-r-- 1 yun yun 1283 Jul 25 23:41 tail-hdfs.conf 13 [[email protected] conf]$ cat tail-avro-avro-logger.conf 14 # Name the components on this agent 15 a1.sources = r1 16 a1.sinks = k1 17 a1.channels = c1 18 19 # Describe/configure the source 20 a1.sources.r1.type = exec 21 a1.sources.r1.command = tail -F /app/webservice/logs/access.log 22 a1.sources.r1.channels = c1 23 24 # Describe the sink 25 #绑定的不是本机, 是另外一台机器的服务地址, sink端的avro是一个发送端, avro的客户端, 往mini02这个机器上发 26 a1.sinks = k1 27 a1.sinks.k1.type = avro 28 a1.sinks.k1.channel = c1 29 a1.sinks.k1.hostname = mini02 30 a1.sinks.k1.port = 4141 31 a1.sinks.k1.batch-size = 2 32 33 # Use a channel which buffers events in memory 34 a1.channels.c1.type = memory 35 a1.channels.c1.capacity = 1000 36 a1.channels.c1.transactionCapacity = 100 37 38 # Bind the source and sink to the channel 39 a1.sources.r1.channels = c1 40 a1.sinks.k1.channel = c1
配置文件mini02
1 [[email protected] conf]$ pwd 2 /app/flume/conf 3 [[email protected] conf]$ ll 4 total 20 5 -rw-rw-r-- 1 yun yun 1357 Jul 26 22:39 avro-hdfs.conf 6 -rw-r--r-- 1 yun yun 1661 Sep 15 2017 flume-conf.properties.template 7 -rw-r--r-- 1 yun yun 1455 Sep 15 2017 flume-env.ps1.template 8 -rw-r--r-- 1 yun yun 1568 Sep 15 2017 flume-env.sh.template 9 -rw-r--r-- 1 yun yun 3107 Sep 15 2017 log4j.properties 10 [[email protected] conf]$ cat avro-hdfs.conf 11 # Name the components on this agent 12 a1.sources = r1 13 a1.sinks = k1 14 a1.channels = c1 15 16 # Describe/configure the source 17 #source中的avro组件是接收者服务, 绑定本机 18 a1.sources.r1.type = avro 19 a1.sources.r1.channels = c1 20 a1.sources.r1.bind = 0.0.0.0 21 a1.sources.r1.port = 4141 22 23 # Describe the sink 24 a1.sinks.k1.type = hdfs 25 a1.sinks.k1.channel = c1 26 a1.sinks.k1.hdfs.path = /flume/new-events/%y-%m-%d/%H%M/ 27 a1.sinks.k1.hdfs.filePrefix = events- 28 # 以下3项表示每隔10分钟切换目录存储 29 a1.sinks.k1.hdfs.round = true 30 a1.sinks.k1.hdfs.roundValue = 10 31 a1.sinks.k1.hdfs.roundUnit = minute 32 # 滚动当前文件前等待的秒数 33 a1.sinks.k1.hdfs.rollInterval = 30 34 # 文件大小以字节为单位触发滚动 35 a1.sinks.k1.hdfs.rollSize = 204800 36 # 在滚动之前写入文件的事件数 37 a1.sinks.k1.hdfs.rollCount = 500 38 # 在它被刷新到HDFS之前写入文件的事件数量,每批次事件最大数 39 a1.sinks.k1.hdfs.batchSize = 100 40 a1.sinks.k1.hdfs.useLocalTimeStamp = true 41 #生成的文件类型,默认是Sequencefile,可用DataStream,则为普通文本 42 a1.sinks.k1.hdfs.fileType = DataStream 43 44 # Use a channel which buffers events in memory 45 a1.channels.c1.type = memory 46 a1.channels.c1.capacity = 1000 47 a1.channels.c1.transactionCapacity = 100 48 49 # Bind the source and sink to the channel 50 a1.sources.r1.channels = c1 51 a1.sinks.k1.channel = c1
启动flume
1 # 启动mini02的flume 2 3 4 # 启动mini01的flume
启动jar包打印日志
1 [[email protected] webservice]$ pwd 2 /app/webservice 3 [[email protected] webservice]$ java -jar testlog.jar &
可参见:Hadoop2.7.6_02_HDFS常用操作 ----- 3.3. web日志模拟
浏览器查看flume下沉的数据


6. 更多source和sink组件
Flume支持众多的source和sink类型,详细手册可参考官方文档
flume环境安装(代码片段)
源码包下载:http://archive.apache.org/dist/flume/1.8.0/ 集群环境:master192.168.1.99slave1192.168.1.100slave2192.168.1.101 下载安装包:#Masterwgethttp://archive.apache.org/dist/flume/1.8.0/apache-flume 查看详情
flume的安装(代码片段)
一、下载flume并解压1、手动下载flume安装包下载地址下载flume2.将安装包上传到虚拟机上,并解压tar-zxvfapache-flume-1.8.0-bin.tar.gz-C/export/software/3.重命名mvapache-flume-1.8.0-binflume4.修改环境变量5.修改配置文件cdflume/conf/mvflume-env.sh.templ 查看详情
flume的安装(代码片段)
一、下载flume并解压1、手动下载flume安装包下载地址下载flume2.将安装包上传到虚拟机上,并解压tar-zxvfapache-flume-1.8.0-bin.tar.gz-C/export/software/3.重命名mvapache-flume-1.8.0-binflume4.修改环境变量5.修改配置文件cdflume/conf/mvflume-env.sh.templ 查看详情
flume的安装(代码片段)
一、下载flume并解压1、手动下载flume安装包下载地址下载flume2.将安装包上传到虚拟机上,并解压tar-zxvfapache-flume-1.8.0-bin.tar.gz-C/export/software/3.重命名mvapache-flume-1.8.0-binflume4.修改环境变量5.修改配置文件cdflume/conf/mvflume-env.sh.templ... 查看详情
object对象常用方法-案例(代码片段)
create创建一个对象constobj=Object.create(a:1,b:value:2)第一个参数为对象,对象为函数调用之后返回新对象的原型对象,第二个参数为对象本身的实例方法(默认不能修改,不能枚举)obj.__proto__.a===1//trueobj.b=... 查看详情
flume读取日志文件并存储到hdfs(代码片段)
配置hadoop环境配置flume环境配置flume文件D:Softapache-flume-1.8.0-binconf 将flume-conf.properties.template重新命名为 hdfs.properties#组装agenta1.sources=s1a1.channels=c1a1.sinks=k1#配置source:从目录中读取文件a1.sources.s1.type=spooldira1.sources.s1.channels=c... 查看详情
flume安装配置
1 下载安装包并解压下载地址:http://flume.apache.org/download.html解压:tarzxvfapache-flume-1.8.0-bin.tar.gz 2配置环境变量 vi~/.bashrc配置环境变量:exportFLUME_HOME=/hmaster/flume/apache-flume-1.8.0-binexportF 查看详情
常用sql案例(代码片段)
一、开窗函数1.开窗函数求占比selectcity_name,type,id_cnt_by_city_name,count(distinctid)id_cnt,--type分组ID数count(distinctid)/id_cnt_by_basrate--占比from(selecttype,city_name,id,count(id)over(partitionbycity_name)id_cnt_by_city_name--求城市总id数fromtable_Name)xxxgroupbycity_na... 查看详情
window下安装flume
本教程是在已经安装了jdk1.8以后的基础上进行的操作.1.登陆官网http://flume.apache.org/download.html下载apache-flume-1.8.0-bin.tar.gz2.解压apache-flume-1.8.0-bin.tar.gz3.在conf文件夹中新建example.conf文件#example.conf:Asingle-nodeFlumeconfigu 查看详情
python类的常用魔法方法(代码片段)
文章目录一.`__init__()`二.`__str__()`三.`__del__()`四.`__repr__()`五.使用案例一.__init__()#在Python类中,有一类方法,这类方法以两个下划线开头和结尾,并且在满足某个特定条件的情况下会自动调用,这类方法称为魔法... 查看详情
python面向对象微案例_钻石问题与super(代码片段)
Python面向对象微案例_钻石问题与super钻石问题子类继承多个父类且在子类里调用在父类及基类里都重写的方法时的执行会出现基类被调用多次(两次及以上)。因为子类及父类、基类的继承关系形如钻石,因此该问题又称之为... 查看详情
asm字节码操作工具类与常用类classremapper介绍类映射代码混淆(代码片段)
...4.总结1.概述在上一篇文章:【ASM】字节码操作工具类与常用类InstructionAdapter介绍我们知道了,对于InstructionAdapter类来说,它的特点是“添加了许多与opc 查看详情
100天精通python(数据分析篇)——第62天:pandas常用统计方法与案例(代码片段)
文章目录每篇前言一、常用统计方法与案例1.求和(sum)2.求平均值(mean)3.求最小值(min)4.求最大值(max)5.求中位数(median)6.求众数(mode)7.求方差(var)8.求标准 查看详情
kafka_2.11-2.0.0_安装部署(代码片段)
参考博文:kafka配置文件参数详解参考博文:Kafka【第一篇】Kafka集群搭建参考博文:如何为Kafka集群选择合适的Partitions数量参考博文:KafkaServer.properties参考博文:kafka常用配置【重要】参考博文:kafka常用配置 1.主... 查看详情
2021年最新最全flink系列教程__flink综合案例(代码片段)
...e数据仓库订单自动好评综合案例FlinkFileSink落地写入到HDFS常用的文件存储格式TextFilecsvrcFileparquetorcsequenceFile支持流批一体的写入到HDFSFileSink需求将流数据写入到HDFSpackagecn.itcast.flink.filesink 查看详情
linux❀nginx基础解释与服务部署搭建(代码片段)
文章目录1、基础概念2、安装Nginx3、Nginx主配置文件4、Nginx常用命令1、基础概念反向代理负载均衡动静分离2、安装Nginx查看NginxRPM安装包信息;[root@localhost~]#yumlist|grepnginxnginx.x86_641:1.14.1-9.module+el8.0.0+4108+af250afe@A 查看详情
jquery_案例1_广告显示和隐藏与jquery_案例2_抽奖_演示(代码片段)
JQuery_案例1_广告显示和隐藏 <!DOCTYPEhtml><html><head><metacharset="UTF-8"><title>广告的自动显示与隐藏</title><style>#contentwidth:100%;height:500px;background:#999</style><!--引入jquery--><scripttype="text/javascript... 查看详情
docker及常用软件的安装部署(代码片段)
....安装与运行2.常用命令3.镜像相关命令4.创建与启动容器5.部署应用内容简介本篇文章介绍Docker安装部署和在Docker安装一些常用软件。首先介绍一下什么是Docker摘自百度百科:Docker是一个开源的应用容器引擎,让开发者可... 查看详情