关键词:
- 史上最全 | HBase 知识体系吐血总结 - 腾讯云开发者社区-腾讯云 (tencent.com)
- Hbase系列-2、Hbase基础_技术武器库的博客-CSDN博客
- Hbase系列-3、Hbase高级_技术武器库的博客-CSDN博客
- 【万字长文】Hbase最全知识点整理(建议收藏) - 腾讯云开发者社区-腾讯云 (tencent.com)
- 大数据技术之HBase原理与实战归纳分享-上 - itxiaoshen - 博客园 (cnblogs.com)
- 大数据技术之HBase原理与实战归纳分享-中 - itxiaoshen - 博客园 (cnblogs.com)
- 大数据技术之HBase原理与实战归纳分享-下 - itxiaoshen - 博客园 (cnblogs.com)
一、HBase 基础
1.1 HBase 基本介绍
HBase 是 BigTable 的开源 Java 版本。是建立在 HDFS 之上,提供高可靠性、高性能、列存储、可伸缩、实时读写 NoSql 的数据库系统。
它介于 NoSql 和 RDBMS 之间,仅能通过主键(row key)和主键的 range 来检索数据,仅支持单行事务(可通过 hive 支持来实现多表 join 等复杂操作)。
主要用来存储结构化和半结构化的松散数据。
Hbase 查询数据功能很简单,不支持 join 等复杂操作,不支持复杂的事务(行级的事务) Hbase 中支持的数据类型:byte[] 与 hadoop 一样,Hbase 目标主要依靠横向扩展,通过不断增加廉价的商用服务器,来增加计算和存储能力。
HBase 中的表一般有这样的特点:
- 大:一个表可以有上十亿行,上百万列
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索。
- 稀疏:对于为空(null)的列,并不占用存储空间,因此,表可以设计的非常稀疏。
HBase 的发展历程
HBase 的原型是 Google 的 BigTable 论文,受到了该论文思想的启发,目前作为 Hadoop 的子项目来开发维护,用于支持结构化的数据存储。
官方网站:http://hbase.apache.org
- 2006 年 Google 发表 BigTable 白皮书
- 2006 年开始开发 HBase
- 2008 HBase 成为了 Hadoop 的子项目
- 2010 年 HBase 成为 Apache 顶级项目
1.2 HBase 与 Hadoop 的关系
1.2.1 HDFS
- 为分布式存储提供文件系统
- 针对存储大尺寸的文件进行优化,不需要对 HDFS 上的文件进行随机读写
- 直接使用文件
- 数据模型不灵活
- 使用文件系统和处理框架
- 优化一次写入,多次读取的方式
1.2.2 HBase
- 提供表状的面向列的数据存储
- 针对表状数据的随机读写进行优化
- 使用 key-value 操作数据
- 提供灵活的数据模型
- 使用表状存储,支持 MapReduce,依赖 HDFS
- 优化了多次读,以及多次写
1.3 RDBMS 与 HBase 的对比
| 关系型数据库(结构) | HBase(结构) | 关系型数据库(功能) | HBase(功能) |
|---|---|---|---|
| 数据库以表的形式存在 | 数据库以 region 的形式存在 | 支持向上扩展 | 支持向外扩展 |
| 支持 FAT、NTFS、EXT、文件系统 | 支持 HDFS 文件系统 | 使用 SQL 查询 | 使用 API 和 MapReduce 来访问 HBase 表数据 |
| 使用 Commit log 存储日志 | 使用 WAL(Write-Ahead Logs)存储日志 | 面向行,即每一行都是一个连续单元 | 面向列,即每一列都是一个连续的单元 |
| 参考系统是坐标系统 | 参考系统是 Zookeeper | 数据总量依赖于服务器配置 | 数据总量不依赖具体某台机器,而取决于机器数量 |
| 使用主键(PK) | 使用行键(row key) | 具有 ACID 支持 | HBase 不支持 ACID(Atomicity、Consistency、Isolation、Durability) |
| 支持分区 | 支持分片 | 适合结构化数据 | 适合结构化数据和非结构化数据 |
| 使用行、列、单元格 | 使用行、列、列族和单元格 | 传统关系型数据库一般都是中心化的 | 一般都是分布式的 |
| 支持事务 | HBase 不支持事务 | ||
| 支持 Join | 不支持 Join |
1.4 HBase 特征简要
- 海量存储
Hbase 适合存储 PB 级别的海量数据,在 PB 级别的数据以及采用廉价 PC 存储的情况下,能在几十到百毫秒内返回数据。这与 Hbase 的极易扩展性息息相关。正式因为 Hbase 良好的扩展性,才为海量数据的存储提供了便利。
- 列式存储
这里的列式存储其实说的是列族存储,Hbase 是根据列族来存储数据的。列族下面可以有非常多的列,列族在创建表的时候就必须指定。
- 极易扩展
Hbase 的扩展性主要体现在两个方面,一个是基于上层处理能力(RegionServer)的扩展,一个是基于存储的扩展(HDFS)。通过横向添加 RegionSever 的机器,进行水平扩展,提升 Hbase 上层的处理能力,提升 Hbsae 服务更多 Region 的能力。备注:RegionServer 的作用是管理 region、承接业务的访问,这个后面会详细的介绍通过横向添加 Datanode 的机器,进行存储层扩容,提升 Hbase 的数据存储能力和提升后端存储的读写能力。
- 高并发
由于目前大部分使用 Hbase 的架构,都是采用的廉价 PC,因此单个 IO 的延迟其实并不小,一般在几十到上百 ms 之间。这里说的高并发,主要是在并发的情况下,Hbase 的单个 IO 延迟下降并不多。能获得高并发、低延迟的服务。
- 稀疏
稀疏主要是针对 Hbase 列的灵活性,在列族中,你可以指定任意多的列,在列数据为空的情况下,是不会占用存储空间的。
1.5 Hbase和hive的区别
Hbase和Hive在大数据架构中处在不同位置,Hbase主要解决实时数据查询问题,Hive主要解决海量数据处理和计算问题,一般是配合使用。
Hbase:Hadoop database 的简称,也就是基于Hadoop数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
Hive:Hive是Hadoop数据仓库,严格来说,不是数据库,主要是让开发人员能够通过SQL来计算和处理HDFS上的结构化数据,适用于离线的批量数据计算。
Hbase主要解决实时数据查询问题,Hive主要解决数据处理和计算问题,一般是配合使用。
1.5.1 区别
- Hbase: Hadoop database 的简称,也就是基于Hadoop数据库,是一种NoSQL数据库,主要适用于海量明细数据(十亿、百亿)的随机实时查询,如日志明细、交易清单、轨迹行为等。
- Hive:Hive是Hadoop数据仓库,严格来说,不是数据库,主要是让开发人员能够通过SQL来计算和处理HDFS上的结构化数据,适用于离线的批量数据计算。
- 通过元数据来描述Hdfs上的结构化文本数据,通俗点来说,就是定义一张表来描述HDFS上的结构化文本,包括各列数据名称,数据类型是什么等,方便我们处理数据,当前很多SQL ON Hadoop的计算引擎均用的是hive的元数据,如Spark SQL、Impala等;
- 基于第一点,通过SQL来处理和计算HDFS的数据,Hive会将SQL翻译为Mapreduce来处理数据;
1.5.2 关系
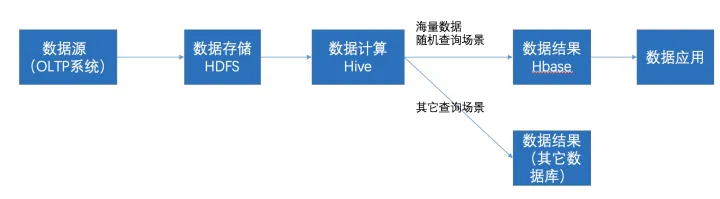
在大数据架构中,Hive和HBase是协作关系,数据流一般如下图:
- 通过ETL工具将数据源抽取到HDFS存储;
- 通过Hive清洗、处理和计算原始数据;
- HIve清洗处理后的结果,如果是面向海量数据随机查询场景的可存入Hbase
- 数据应用从HBase查询数据;
1.6 Hbase适用场景
- 写密集型应用,每天写入量巨大,而相对读数量较小的应用,比如微信的历史消息,游戏日志等等
- 不需要复杂查询条件且有快速随机访问的需求。HBase只支持基于rowkey的查询,对于HBase来说,单条记录或者小范围的查询是可以接受的,大范围的查询由于分布式的原因,可能在性能上有点影响,而对于像SQL的join等查询,HBase无法支持。
- 对性能和可靠性要求非常高的应用,由于HBase本身没有单点故障,可用性非常高。数据量较大,而且增长量无法预估的应用,HBase支持在线扩展,即使在一段时间内数据量呈井喷式增长,也可以通过HBase横向扩展来满足功能。
- 结构化和半结构化的数据,基于Hbase动态列,稀疏存的特性。Hbase支持同一列簇下的列动态扩展,无需提前定义好所有的数据列,并且采用稀疏存的方式方式,在列数据为空的情况下不占用存储空间。
- 网络安全业务数据带有连续性,一个完整的攻击链往往由N多次攻击事件构成,在hive中,一次攻击即为一条数据,无法体现数据的连续性。在Hbase里面,由于其多版本特性,对于任何一个字段,当数据更新后,其旧版本数据仍可访问。所以一次攻击事件可以存储为一条数据,将多次攻击日志叠加更新至此,大大减轻了业务开发人员的取数效率。
二、HBase 基础架构

Zookeeper: Master 的高可用、RegionServer 的监控、元数据的入口以及集群配置的维护等
HDFS: 提供底层数据支撑
2.1 HMaster
功能:
- 监控 RegionServer
- 处理 RegionServer 故障转移
- 处理元数据的变更
- 处理 region 的分配或移除
- 在空闲时间进行数据的负载均衡
- 通过 Zookeeper 发布自己的位置给客户端
2.2 RegionServer
功能:
- 负责存储 HBase 的实际数据
- 处理分配给它的 Region
- 刷新缓存到 HDFS
- 维护 HLog
- 执行压缩
- 负责处理 Region 分片
2.3 组件
2.3.1 Write-Ahead logs
HBase 的修改记录,当对 HBase 读写数据的时候,数据不是直接写进磁盘,它会在内存中保留一段时间(时间以及数据量阈值可以设定)。但把数据保存在内存中可能有更高的概率引起数据丢失,为了解决这个问题,数据会先写在一个叫做 Write-Ahead logfile 的文件中,然后再写入内存中。所以在系统出现故障的时候,数据可以通过这个日志文件重建。
2.3.2 HFile
这是在磁盘上保存原始数据的实际的物理文件,是实际的存储文件。
2.3.3 Store
HFile 存储在 Store 中,一个 Store 对应 HBase 表中的一个列族。
2.3.4 MemStore
顾名思义,就是内存存储,位于内存中,用来保存当前的数据操作,所以当数据保存在 WAL 中之后,RegsionServer 会在内存中存储键值对。
2.3.5 Region
Hbase 表的分片,HBase 表会根据 RowKey 值被切分成不同的 region 存储在 RegionServer 中,在一个 RegionServer 中可以有多个不同的 region。
三、HBase 常用 shell 操作
3.1 添加操作
- 进入 HBase 客户端命令操作界面
$ bin/hbase shell
- 查看帮助命令
hbase(main):001:0> help
- 查看当前数据库中有哪些表
hbase(main):002:0> list
- 创建一张表
创建 user 表,包含 info、data 两个列族
hbase(main):010:0> create 'user', 'info', 'data'
或者
hbase(main):010:0> create 'user', NAME => 'info', VERSIONS => '3',NAME => 'data'
- 添加数据操作
向 user 表中插入信息,row key 为 rk0001,列族 info 中添加 name 列标示符,值为 zhangsan
hbase(main):011:0> put 'user', 'rk0001', 'info:name', 'zhangsan'
向 user 表中插入信息,row key 为 rk0001,列族 info 中添加 gender 列标示符,值为 female
hbase(main):012:0> put 'user', 'rk0001', 'info:gender', 'female'
向 user 表中插入信息,row key 为 rk0001,列族 info 中添加 age 列标示符,值为 20
hbase(main):013:0> put 'user', 'rk0001', 'info:age', 20
向 user 表中插入信息,row key 为 rk0001,列族 data 中添加 pic 列标示符,值为 picture
hbase(main):014:0> put 'user', 'rk0001', 'data:pic', 'picture'
3.2 查询操作
- 通过 rowkey 进行查询
获取 user 表中 row key 为 rk0001 的所有信息
hbase(main):015:0> get 'user', 'rk0001'
- 查看 rowkey 下面的某个列族的信息
获取 user 表中 row key 为 rk0001,info 列族的所有信息
hbase(main):016:0> get 'user', 'rk0001', 'info'
- 查看 rowkey 指定列族指定字段的值
获取 user 表中 row key 为 rk0001,info 列族的 name、age 列标示符的信息
hbase(main):017:0> get 'user', 'rk0001', 'info:name', 'info:age'
- 查看 rowkey 指定多个列族的信息
获取 user 表中 row key 为 rk0001,info、data 列族的信息
hbase(main):018:0> get 'user', 'rk0001', 'info', 'data'
或者这样写
hbase(main):019:0> get 'user', 'rk0001', COLUMN => ['info', 'data']
或者这样写
hbase(main):020:0> get 'user', 'rk0001', COLUMN => ['info:name', 'data:pic']
- 指定 rowkey 与列值查询
获取 user 表中 row key 为 rk0001,cell 的值为 zhangsan 的信息
hbase(main):030:0> get 'user', 'rk0001', FILTER => "ValueFilter(=, 'binary:zhangsan')"
- 指定 rowkey 与列值模糊查询
获取 user 表中 row key 为 rk0001,列标示符中含有 a 的信息
hbase(main):031:0> get 'user', 'rk0001', FILTER => "(QualifierFilter(=,'substring:a'))"
继续插入一批数据
hbase(main):032:0> put 'user', 'rk0002', 'info:name', 'fanbingbing'
hbase(main):033:0> put 'user', 'rk0002', 'info:gender', 'female'
hbase(main):034:0> put 'user', 'rk0002', 'info:nationality', '中国'
hbase(main):035:0> get 'user', 'rk0002', FILTER => "ValueFilter(=, 'binary:中国')"
- 查询所有数据
查询 user 表中的所有信息
scan 'user'
- 列族查询
查询 user 表中列族为 info 的信息
scan 'user', COLUMNS => 'info'
scan 'user', COLUMNS => 'info', RAW => true, VERSIONS => 5
scan 'user', COLUMNS => 'info', RAW => true, VERSIONS => 3
- 多列族查询
查询 user 表中列族为 info 和 data 的信息
scan 'user', COLUMNS => ['info', 'data']
scan 'user', COLUMNS => ['info:name', 'data:pic']
- 指定列族与某个列名查询
查询 user 表中列族为 info、列标示符为 name 的信息
scan 'user', COLUMNS => 'info:name'
- 指定列族与列名以及限定版本查询
查询 user 表中列族为 info、列标示符为 name 的信息,并且版本最新的 5 个
scan 'user', COLUMNS => 'info:name', VERSIONS => 5
- 指定多个列族与按照数据值模糊查询
查询 user 表中列族为 info 和 data 且列标示符中含有 a 字符的信息
scan 'user', COLUMNS => ['info', 'data'], FILTER => "(QualifierFilter(=,'substring:a'))"
- rowkey 的范围值查询
查询 user 表中列族为 info,rk 范围是(rk0001, rk0003)的数据
scan 'user', COLUMNS => 'info', STARTROW => 'rk0001', ENDROW => 'rk0003'
- 指定 rowkey 模糊查询
查询 user 表中 row key 以 rk 字符开头的
scan 'user',FILTER=>"PrefixFilter('rk')"
- 指定数据范围值查询
查询 user 表中指定范围的数据
scan 'user', TIMERANGE => [1392368783980, 1392380169184]
- 统计一张表有多少行数据
count 'user'
3.3 更新操作
- 更新数据值
更新操作同插入操作一模一样,只不过有数据就更新,没数据就添加。
- 更新版本号
将 user 表的 f1 列族版本号改为 5
hbase(main):050:0> alter 'user', NAME => 'info', VERSIONS => 5
3.4 删除操作
- 指定 rowkey 以及列名进行删除
删除 user 表 row key 为 rk0001,列标示符为 info:name 的数据
hbase(main):045:0> delete 'user', 'rk0001', 'info:name'
- 指定 rowkey,列名以及字段值进行删除
删除 user 表 row key 为 rk0001,列标示符为 info:name,timestamp 为 1392383705316 的数据
delete 'user', 'rk0001', 'info:name', 1392383705316
- 删除一个列族
alter 'user', NAME => 'info', METHOD => 'delete'
或者
alter 'user', NAME => 'info', METHOD => 'delete'
- 清空表数据
hbase(main):017:0> truncate 'user'
- 删除表
首先需要先让该表为 disable 状态,使用命令:
hbase(main):049:0> disable 'user
然后才能 drop 这个表,使用命令:
hbase(main):050:0> drop 'user'
注意:如果直接 drop 表,会报错:Drop the named table. Table must first be disabled
四、HBase运维
4.1 HBase 的高级 shell 管理命令
- status
例如:显示服务器状态
hbase(main):058:0> status 'node01'
- whoami
显示 HBase 当前用户,例如:
hbase> whoami
- list
显示当前所有的表
hbase> list
- count
统计指定表的记录数,例如:
hbase> count 'user'
- describe
展示表结构信息
hbase> describe 'user'
- exists
检查表是否存在,适用于表量特别多的情况
hbase> exists 'user'
- is_enabled、is_disabled
检查表是否启用或禁用
hbase> is_enabled 'user'
- alter
该命令可以改变表和列族的模式,例如:
为当前表增加列族:
hbase> alter 'user', NAME => 'CF2', VERSIONS => 2
为当前表删除列族:
hbase(main):002:0> alter 'user', 'delete' => 'CF2'
- disable/enable
禁用一张表/启用一张表
- drop
删除一张表,记得在删除表之前必须先禁用
- truncate
清空表
4.2 HBase数据压缩
4.2.1 HBase数据压缩方式的介绍
为了提高 HBase存储的利用率,很多 HBase使用者会对 HBase 表中的数据进行压缩。目前 HBase 可以支持的压缩方式有 GZ(GZIP)、LZO、LZ4 以及 Snappy。它们之间的区别如下:
- GZ:用于冷数据压缩,与 Snappy 和 LZO 相比,GZIP 的压缩率更高,但是更消耗 CPU,解压/压缩速度更慢。
- Snappy 和 LZO:用于热数据压缩,占用 CPU 少,解压/压缩速度比 GZ 快,但是压缩率不如 GZ 高。
- Snappy 与 LZO 相比,Snappy 整体性能优于 LZO,Snappy 压缩率比 LZO 更低,但是解压/压缩速度更快。
- LZ4 与 LZO 相比,LZ4 的压缩率和 LZO 的压缩率相差不多,但是LZ4的解压/压缩速度更快。
各种压缩各有不同的特点,我们需要根据业务需求(解压和压缩速率、压缩率等)选择不同的压缩格式。多数情况下,选择Snppy或LZ0是比较好的选择,因为它们的压缩开销底,能节省空间。这里介绍一下 HBase 中使用 Snappy 的方法,其他的压缩设置方法和这个类似。
4.2.2 创建表时指定压缩格式
在创建 HBase 表的时候我们可以指定数据的压缩格式,如下;
hbase(main):010:0> create 'iteblog',NAME=>'f1', NAME=>'f2',COMPRESSION=>'Snappy'
Created table iteblog
Took 1.2539 seconds
=> Hbase::Table - iteblog
hbase(main):011:0> describe 'iteblog'
Table iteblog is ENABLED
iteblog
COLUMN FAMILIES DESCRIPTION
NAME => 'f1', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY =>'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'NONE', BLOCKCACHE => 'true', BLOCKSIZE => '65536'
NAME => 'f2', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY =>'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'SNAPPY', BLOCKCACHE => 'true', BLOCKSIZE => '65536'
2 row(s)
Took 0.0522 seconds
上面例子的表 iteblog 有两个列族,我们选择对 f2 列族进行 Snappy 压缩, f1 列族数据不压缩。
4.2.3 对已有的表设置压缩
当然,如果我们表已经创建了,同样也可以对其进行压缩,方式如下:
hbase(main):001:0> alter 'iteblog', NAME => 'f', COMPRESSION => 'snappy'
Updating all regions with the new schema...
27/27 regions updated.
Done.
Took 9.5146 seconds
hbase(main):003:0> describe 'iteblog'
Table iteblog is ENABLED
iteblog
COLUMN FAMILIES DESCRIPTION
NAME => 'f', VERSIONS => '1', EVICT_BLOCKS_ON_CLOSE => 'false', NEW_VERSION_BEHAVIOR => 'false', KEEP_DELETED_CELLS => 'FALSE', CACHE_DATA_ON_WRITE => 'false', DATA_BLOCK_ENCODING => 'NONE', TTL => 'FOREVER', MIN_VERSIONS => '0', REPLICATION_SCOPE => '0', BLOOMFILTER => 'ROW', CACHE_INDEX_ON_WRITE => 'false', IN_MEMORY => 'false', CACHE_BLOOMS_ON_WRITE => 'false', PREFETCH_BLOCKS_ON_OPEN => 'false', COMPRESSION => 'SNAPPY', BLOCKCACHE => 'true', BLOCKSIZE => '65536'
1 row(s)
Took 0.0782 seconds
设置完之后,其实数据并没有被压缩,我们需要对当前表执行 major_compact 命令手动进行压缩:
hbase(main):002:0> major_compact 'iteblog'
Took 1.2255 seconds
这样,iteblog 表的数据就可以被压缩了。
五、HBase 的 Java API 开发
5.1 开发 javaAPI 操作 HBase 表数据
- 创建表 myuser
@Test
public void createTable() throws IOException
//创建配置文件对象,并指定zookeeper的连接地址
Configuration configuration = HBaseConfiguration.create();
configuration.set("hbase.zookeeper.property.clientPort", "2181");
configuration.set("hbase.zookeeper.quorum", "node01,node02,node03");
//集群配置↓
//configuration.set("hbase.zookeeper.quorum", "101.236.39.141,101.236.46.114,101.236.46.113");
configuration.set("hbase.master", "node01:60000");
Connection connection = ConnectionFactory.createConnection(configuration);
Admin admin = connection.getAdmin()数据同步工具datax和dataweb知识手册,datax优化(代码片段)
大数据Hadoop之——数据同步工具DataX-掘金(juejin.cn)一、概述DataX是阿里云DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX实现了包括MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、A... 查看详情
数据同步工具datax和dataweb知识手册,datax优化(代码片段)
大数据Hadoop之——数据同步工具DataX-掘金(juejin.cn)一、概述DataX是阿里云DataWorks数据集成的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX实现了包括MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、A... 查看详情
超详细梳理hbase核心知识点(上)建议收藏(代码片段)
...不会发困的书,very奈斯。本文就是整理了这本书上的知识点而形成的文章,准备分为上下两篇文章系统梳理HBase核心知识点,如果你想了解HBase, 查看详情
分布式nosql列存储数据库hbase(代码片段)
文章目录分布式NoSQL列存储数据库Hbase(六)知识点01:回顾知识点02:目标知识点03:SQLonHbase知识点04:HiveonHbase介绍知识点05:HiveonHbase配置知识点06:HiveonHbase实现知识点07:二级索引问题知识... 查看详情
前端技能树,面试复习——风中劲草:知识要点精讲精炼手册(代码片段)
如果说前面56章节是书本,那么《风中劲草:知识要点精讲精炼手册》就是对前面章节知识点的浓缩版本,便于大家背诵。这也是本专栏的一大特色,方便一些急需参加面试、在短时间内无法充分准备的同学。同时,在精讲精炼... 查看详情
一linux指令手册及知识入门(代码片段)
目录速查一、指令总结lspwdcdtouchmkdirrm&rmdirmancp-拷贝mv-改名&移动cat&tacmorelesshead&tail(打印)grep(行过滤)echodatecal(日历查询)find(查找)whichwhereiszip 查看详情
分享知识-快乐自己:运行(wordcount)案例(代码片段)
运行wordcount案例:一):大数据(hadoop)初始化环境搭建二):大数据(hadoop)环境搭建三):运行wordcount案例四):揭秘HDFS五):揭秘MapReduce六):揭秘HBase七):HBase编程-----------------------------------------------------------------Hadoo... 查看详情
网格布局的基础知识|cssgridlayout:basicconceptsofgridlayout(gridlayout)-css中文开发手册-break易站(代码片段
??CSS中文开发手册网格布局的基础知识|CSSGridLayout:BasicConceptsofGridLayout(GridLayout)-CSS中文开发手册CSS网格布局将二维网格系统引入到CSS中.。网格可用于布局主要页面区域或小用户界面元素。本文介绍了CSSGrid布局和CSSGrid布局级别1规... 查看详情
python3自学速查手册,324页内容,最全知识整理(代码片段)
...thon3获取全部资料《Python3自学速查手册》。这是我见过的知识点最全面,匹配案例最多的合集。每个函数均附有详细描述、语法参考、参数、返回值以及案例。共计324页内容。堪称Python3大字典,有书签更方便查,哪... 查看详情
算法通关手册刷题笔记1数组基础(代码片段)
...数组基础数组操作题目0189轮转数组AC自己的解法其他解法知识点查漏补缺关于python中的数组赋值python中对象的引用0066加一AC自己的解法其他解法知识点查漏补缺0724寻找数组的中心下标AC自己的解法其他做法0485最大连续1的个数AC... 查看详情
kafka3.x核心知识速查手册-一快速上手篇(代码片段)
文章目录一、Kafka介绍1、MQ的作用:2、Kafka的适用场景:二、Kafka快速上手1、实验环境2、单机服务体验3、搭建集群服务4、理解Topic、Partition和Broker5、Kraft集群--了解Kafka3.x速查手册一、快速上手篇--楼兰各种操作尽量玩... 查看详情
内含面试|一文搞懂hbase的基本原理(代码片段)
...景HBase的数据模型和基本原理客户端API的基本使用易混淆知识点面试总结温馨提示:本文内容较长,如果觉得有用,建议收藏。另外记得分享、点赞、在看,素质三连哦!从BigTable说起HBase是在谷歌BigTable的基础之上进行开源实现的... 查看详情
flutter开发手册(代码片段)
...库(Icon)5、设计基础6、Flutter技术介绍7、Flutter知识点总结-基础篇8、Flutter知识点总结-进阶篇9、Flutter常见问题总结喜欢记得点个赞哟,我是王睿,很高兴认识大家 查看详情
2021年大数据hbase(十五):hbase的bulkload批量加载操作(代码片段)
...文章都已经列出历史文章目录,帮助大家回顾前面的知识重点。目录系列历史文章HBase的BulkLoad批量加载操作一、BulkLoad基本介绍二、需求说明三、准备工作1、在hbase中创建名称空间,并创建hbase的表2、创建maven项目加载相关的p... 查看详情
hbase最新官方文档中文翻译与注解1-10|hbase简介与配置信息等(代码片段)
注意:翻译的Hbase官方手册,文中黑色加粗的是官方文档中提醒用户应该注意的地方。红色加粗是作者个人经验总结分享,非官方文档里的内容。一、简介2.快速入门-独立HBaseApacheHBase配置3.配置文件4.基本条件5.HBase运... 查看详情
hbase最新官方文档中文翻译与注解1-10|hbase简介与配置信息等(代码片段)
注意:翻译的Hbase官方手册,文中黑色加粗的是官方文档中提醒用户应该注意的地方。红色加粗是作者个人经验总结分享,非官方文档里的内容。一、简介2.快速入门-独立HBaseApacheHBase配置3.配置文件4.基本条件5.HBase运... 查看详情
2021年大数据hbase:apachephoenix的安装(代码片段)
...文章都已经列出历史文章目录,帮助大家回顾前面的知识重点。目录前言系列历史文章安装Phoenix一、下载二、安装1、上传安装包到Linux系统,并解压2、将phoenix的所有jar包添加到所有HBase RegionServer和Master的复制到HBase的li... 查看详情
2021年大数据hbase(十六):hbase的协处理器(coprocessor)(代码片段)
...文章都已经列出历史文章目录,帮助大家回顾前面的知识重点。目录系列历史文章HBase的协处理器(Coprocessor)一、起源二、协处理器主要的分类三、HBase的协处理器_ObServer四、HBase的协处理器_Endpoint五、概念总结六、加载的方式... 查看详情