关键词:
先扯点没用的
收集日志的目的是有效的利用日志,有效利用日志的前提是日志经过格式化符合我们的要求,这样才能真正的高效利用收集到elasticsearch平台的日志。默认的日志到达elasticsearch 是原始格式,乱的让人抓狂,这个时候你会发现Logstash filter的可爱之处,它很像一块橡皮泥,如果我们手巧的话就会塑造出来让自己舒舒服服的作品,but 如果你没搞好的话那就另说了,本文的宗旨就是带你一起飞,搞定这块橡皮泥。当你搞定之后你会觉得kibana 的世界瞬间清爽了很多!
FIlebeat 的4大金刚
Filebeat 有4个非常重要的概念需要我们知道,
Prospector(矿工);
Harvest (收割者);
libeat (汇聚层);
registry(注册计入者);
Prospector 负责探索日志所在地,就如矿工一样要找矿,而Harvest如矿主一样的收割者矿工们的劳动成果,哎,世界无处不剥削啊!每个Prospector 都有一个对应的Harvest,然后他们有一个共同的老大叫做Libbeat,这个家伙会汇总所有的东西,然后把所有的日志传送给指定的客户,这其中还有个非常重要的角色”registry“,这个家伙相当于一个会计,它会记录Harvest 都收割了些啥,收割到哪里了,这样一但有问题了之后,harvest就会跑到会计哪里问:“上次老子的活干到那块了”?Registry 会告诉Harvest 你Y的上次干到哪里了,去哪里接着干就行了。这样就避免了数据重复收集的问题!
FIlebeat 详细配置:
filebeat.prospectors:
- input_type: log
enabled: True
paths:
- /var/log/mysql-slow-*
#这个地方是关键,我们给上边日志加上了tags,方便在logstash里边通过这个tags 过滤并格式化自己想要的内容;
tags: ["mysql_slow_logs"]
#有的时候日志不是一行输出的,如果不用multiline的话,会导致一条日志被分割成多条收集过来,形成不完整日志,这样的日志对于我们来说是没有用的!通过正则匹配语句开头,这样multiline 会在匹配开头
之后,一直到下一个这样开通的语句合并成一条语句。
#pattern:多行日志开始的那一行匹配的pattern
#negate:是否需要对pattern条件转置使用,不翻转设为true,反转设置为false
#match:匹配pattern后,与前面(before)还是后面(after)的内容合并为一条日志
#max_lines:合并的最多行数(包含匹配pattern的那一行 默认值是500行
#timeout:到了timeout之后,即使没有匹配一个新的pattern(发生一个新的事件),也把已经匹配的日志事件发送出去
multiline.pattern: ‘^\d4/\d2/\d2‘ (2018\05\01 我的匹配是已这样的日期开头的)
multiline.negate: true
multiline.match: after
multiline.Max_lines:20
multiline.timeout: 10s
- input_type: log
paths:
- /var/log/mysql-sql-*
tags: ["mysql_sql_logs"]
multiline.pattern: ‘^\d4/\d2/\d2‘
multiline.negate: true
multiline.match: after
multiline.timeout: 10s
encoding: utf-8
document_type: mysql-proxy
scan_frequency: 20s
harverster_buffer_size: 16384
max_bytes: 10485760
tail_files: true
#tail_files:如果设置为true,Filebeat从文件尾开始监控文件新增内容,把新增的每一行文件作为一个事件依次发送,而不是从文件开始处重新发送所有内容。默认是false;Logstash 的详细配置
input
kafka
topics_pattern => "mysql.*"
bootstrap_servers => "x.x.x.x:9092"
#auto_offset_rest => "latest"
codec => json
group_id => "logstash-g1"
#终于到了关键的地方了,logstash的filter ,使用filter 过滤出来我们想要的日志,
filter
#if 还可以使用or 或者and 作为条件语句,举个栗子: if “a” or “b” or “c” in [tags],这样就可以过滤多个tags 的标签了,我们这个主要用在同型号的交换设备的日志正规化,比如说你有5台交换机,把日志指定到了同一个syslog-ng 上,收集日志的时候只能通过同一个filebeat,多个prospector加不同的tags。这个时候过滤就可以通过判断相应的tags来完成了。
if "mysql_slow_logs" in [tags]
grok
#grok 里边有定义好的现场的模板你可以用,但是更多的是自定义模板,规则是这样的,小括号里边包含所有一个key和value,例子:(?<key>value),比如以下的信息,第一个我定义的key是data,表示方法为:?<key> 前边一个问号,然后用<>把key包含在里边去。value就是纯正则了,这个我就不举例子了。这个有个在线的调试库,可以供大家参考,http://grokdebug.herokuapp.com/
match => "message" => "(?<date>\d4/\d2/\d2\s(?<datetime>%TIME))\s-\s(?<status>\w2)\s-\s(?<respond_time>\d+)\.\d+\w2\s-\s%IP:client:(?<client-port>\d+)\[\d+\]->%IP:server:(?<server-port>\d+).*:(?<databases><\w+>):(?<SQL>.*)"
#过滤完成之后把之前的message 移出掉,节约磁盘空间。
remove_field => ["message"]
else if "mysql_sql_logs" in [tags]
grok
match => "message" => "(?<date>\d4/\d2/\d2\s(?<datetime>%TIME))\s-\s(?<status>\w2)\s-\s(?<respond_time>\d+\.\d+)\w2\s-\s%IP:client:(?<client-port>\d+)\[\d+\]->%IP:server:(?<server-port>\d+).*:(?<databases><\w+>):(?<SQL>.*)"
remove_field => ["message"]
我要过滤的日志样本:
2018/05/01 16:16:01.892 - OK - 759.2ms - 172.29.1.7:35184[485388]->172.7.1.39:3306[1525162561129639717]:<DB>:select count(*) from test[];
过滤后的结果如下:
"date": [
[
"2018/05/01 16:16:01.892"
]
],
"datetime": [
[
"16:16:01.892"
]
],
"TIME": [
[
"16:16:01.892"
]
],
"HOUR": [
[
"16"
]
],
"MINUTE": [
[
"16"
]
],
"SECOND": [
[
"01.892"
]
],
"status": [
[
"OK"
]
],
"respond_time": [
[
"759"
]
],
"client": [
[
"172.29.1.7"
]
],
"IPV6": [
[
null,
null
]
],
"IPV4": [
[
"172.29.1.7",
"172.7.1.39"
]
],
"client-port": [
[
"35184"
]
],
"server": [
[
"172.7.1.39"
]
],
"server-port": [
[
"3306"
]
],
"databases": [
[
"<DB>"
]
],
"SQL": [
[
"select count(*) from test[];"
]
]
#有图有真相: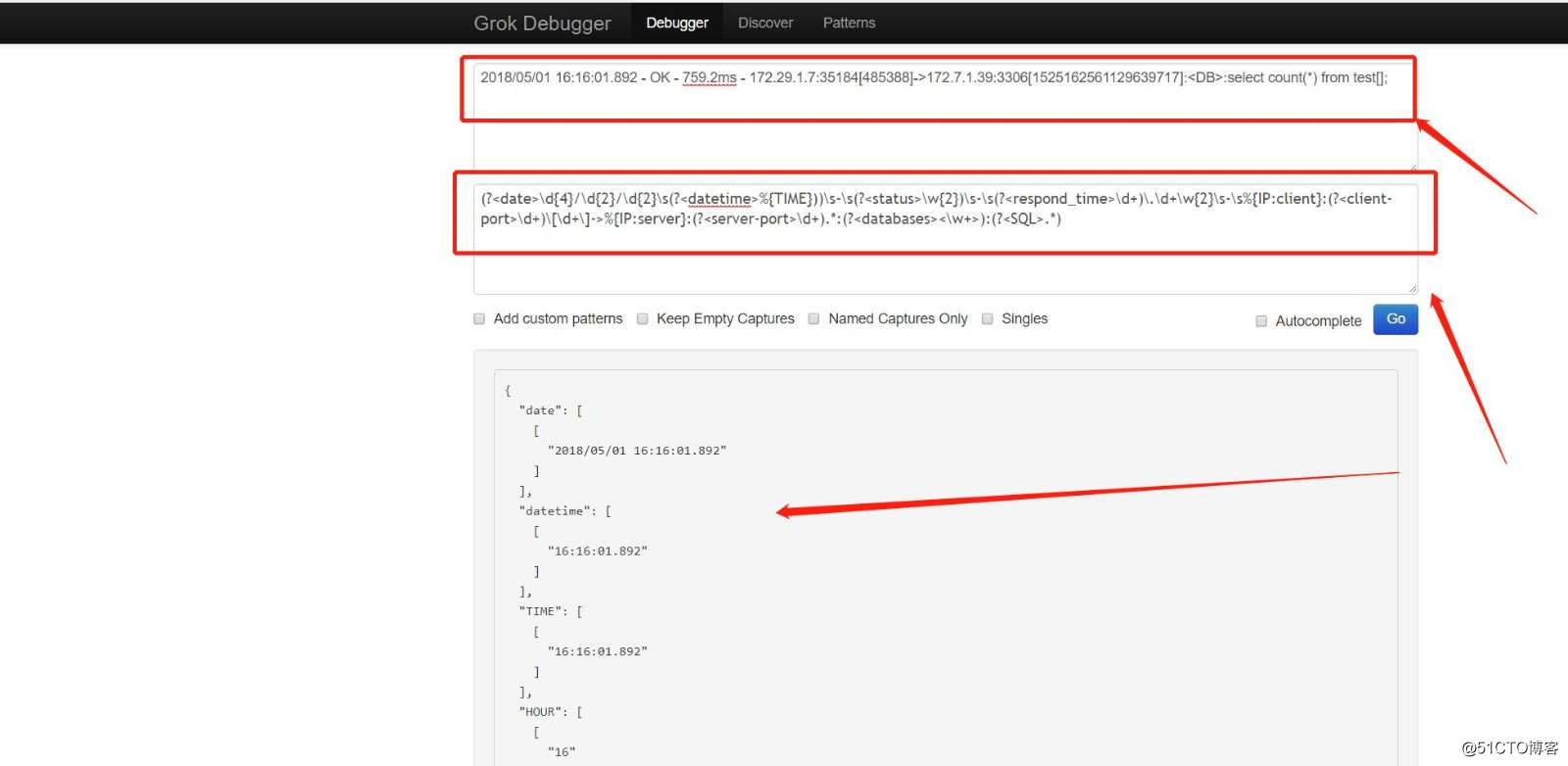
elk之数据收集传输过滤filebeat+logstash部署
...#前端和消息队列搞定之后,我们需要安装数据采集工具filebeats和数据过滤机运输工具Logstash,一般情况我们都使用filebeats用来收集日志文件,我自定义了一个log文件,文件内容如下:55.3.244.1GET/index.html158240.04355.3.244.1GET/index. 查看详情
海量日志下的日志架构优化:filebeat+logstash+kafka+elk(代码片段)
前言:实验需求说明在前面的日志收集中,都是使用的filebeat+ELK的日志架构。但是如果业务每天会产生海量的日志,就有可能引发logstash和elasticsearch的性能瓶颈问题。因此改善这一问题的方法就是filebeat+logstash+kafka+ELK,也就是将... 查看详情
etl工具之日志采集filebeat+logstash
...志文件,需要进行日志收集并进行可视化展示,一般使用filebeat和logstash组合。Logstash是具有实时收集日志功能,可以动态统一来自不同来源的数据,任何类型的事件都可以通过各种各样的输入,过滤功能和输出插件来丰富和转换... 查看详情
elk之logstash(代码片段)
...:设置数据来源; 常用:File、syslog、redis、beats(如:Filebeats) filter:对数据进行一定的加工处理过滤,但不建议做复杂的处理逻辑。此步骤不是必须的;常用:grok、mutate、drop、clone、geoip output:设... 查看详情
filebeat+logstash对message提取指定字段
参考技术Afilebeat中message要么是一段字符串,要么在日志生成的时候拼接成json然后在filebeat中指定为json。但是大部分系统日志无法去修改日志格式,filebeat则无法通过正则去匹配出对应的field,这时需要结合logstash的grok来过滤,架... 查看详情
elasticsearch:elk架构(代码片段)
...ogstash导入数据到ES同步数据库数据到Elasticsearch什么是BeatsFileBeat简介FileBeat的工作原理logstashvsFileBeatFilebeat安装ELK整合实战案例:采集tomcat服务器日志使用FileBeats将日志发送到Logstash配置Logstash接收FileBeat收集的数据并打印Logstas... 查看详情
ELK 堆栈中的 Logstash 和 filebeat
】ELK堆栈中的Logstash和filebeat【英文标题】:LogstashandfilebeatintheELKstack【发布时间】:2019-08-1620:14:04【问题描述】:我们正在服务器上设置elasticsearch、kibana、logstash和filebeat,以分析来自许多应用程序的日志文件。由于原因*,每个... 查看详情
日志分析系统elk(elasticsearch+logstash+kibana+filebeat)
...;二、安装Logstash三、安装Kibana四、安装Filebeat五、集群模式搭建日志分析系统ELK(elasticsearch+logstash+kibana+filebeat)这里先介绍ELK的安装 首先下载ELK在官网下载:https://www.elastic.co/cn/downloads/ 查看详情
elk入门-简单实现日志收集(代码片段)
...WEB配置Elasticsearch配置通过nginx访问elasticsearch和kibana扩展:filebeatinput配置排错方法组件简介和作用filebeat收集日志->logstash过滤/格式化->elasticsearch存储->kibana展示#个人理解其实logstash和filebeat都可以收集日志并且直接输出到elas... 查看详情
elk的logstash怎么过滤出报错的模块
...采集灵活性是我们选择日志采集方案更看重的因素,所以logstash属于首先方案,它可以兼顾多种不同系统和应用类型等因素的差异,从源头上进行一些初步的日志预处理。logstash唯一的小缺憾是它的不轻便,因为它是使用jruby开发... 查看详情
elk做日志分析(filebeat+logstash+elasticsearch)配置(代码片段)
利用Filebeat去读取日志发送到Logstash,再由Logstash处理后发送给Elasticsearch。一、Filebeat项目日志文件:利用Filebeat去读取文件,paths下面配置路径地址,Filebeat会自动去读取/data/share/business_log/TA-*/debug.log文件#===========================Filebea... 查看详情
elk应用之filebeat
参考技术AFilebeat是本地文件的日志数据采集器,可监控日志目录或特定日志文件(tailfile),并将它们转发给Elasticsearch或Logstatsh进行索引、kafka等。带有内部模块(auditd,Apache,Nginx,System和MySQL),可通过一个指定命令来简化通... 查看详情
elk(代码片段)
...综合实验案例一:单机ELK部署案例二.JAVA环境配置,部署filebeat+Elasticsearch收集apache日志nginx日志收集配置mysqlslow慢日志收集elk简介ELK是三个开源软件的缩写,分别表示:Elasticsearch,Logstash,Kibana,它们都是开源软件。新增了一个FileBea... 查看详情
日志分析系统elk之logstash(代码片段)
Logstash什么是ELKLogstash简介Logstash组成1、输入2、过滤器(可选)3、输出Logstash安装与配置通过命令行运行Logstash参数-e参数-f日志输出到文件日志上传到elasticsearchLogstash伪装为日志服务器grok过滤插件分割命令行的信息输出... 查看详情
在 ELK 堆栈中调试 Filebeat
】在ELK堆栈中调试Filebeat【英文标题】:DebuggingFilebeatintheELKstack【发布时间】:2018-04-1420:22:56【问题描述】:我的ELK系统出现了一些问题。客户端工作如下:Filebeat->Logstash-->Elastic-->Kibana我们的部分日志不会从特定机器到达... 查看详情
elk之logstash学习(代码片段)
Logstash最强大的功能在于丰富的过滤器插件。此过滤器提供的并不单单是过滤的功能,还可以对进入过滤器的原始数据进行复杂的逻辑处理。甚至添加独特的事件到后续流程中。1、logstash基本语法组成logstash主要由三部分组成:in... 查看详情
filebeat、logstash过滤器实例
参考技术A主要描述filebeat和logstash的过滤器使用。参考: filebeat: https://www.elastic.co/guide/en/beats/filebeat/6.8/defining-processors.html logstash: https://www.elastic.co/guide/en/logstash/6.8/filter-plugins.html版本:elastics... 查看详情
elk
#环境centos7.4,ELK6,单节点 #服务端Logstash收集,过滤 Elasticsearch存储,索引日志Kibana可视化 #客户端filebeat监控、转发,作为agentfilebeat-->Logstash-->Elasticsearch-->Kibana #内核echo‘*hardnofile65536* 查看详情