关键词:
一、背景介绍:
例如原来顺序是: 10 20 30 40 插入顺序如下 10 20 10 30 20 10 40 30 20 10
二、存在的问题:
采用队头插入的方式,导致了HashMap在“多线程环境下”的死循环问题
问题的症状
从前我们的Java代码因为一些原因使用了HashMap这个东西,但是当时的程序是单线程的,一切都没有问题。后来,我们的程序性能有问题,所以需要变成多线程的,于是,变成多线程后到了线上,发现程序经常占了100%的CPU,查看堆栈,你会发现程序都Hang在了HashMap.get()这个方法上了,重启程序后问题消失。但是过段时间又会来。而且,这个问题在测试环境里可能很难重现。
我们简单的看一下我们自己的代码,我们就知道HashMap被多个线程操作。而Java的文档说HashMap是非线程安全的,应该用ConcurrentHashMap。
但是在这里我们可以来研究一下原因。
Hash表数据结构
HashMap通常会用一个指针数组(假设为table[])来做分散所有的key,当一个key被加入时,会通过Hash算法通过key算出这个数组的下标i,然后就把这个<key, value>插到table[i]中,如果有两个不同的key被算在了同一个i,那么就叫冲突,又叫碰撞,这样会在table[i]上形成一个链表。
我们知道,如果table[]的尺寸很小,比如只有2个,如果要放进10个keys的话,那么碰撞非常频繁,于是一个O(1)的查找算法,就变成了链表遍历,性能变成了O(n),这是Hash表的缺陷。
所以,Hash表的尺寸和容量非常的重要。一般来说,Hash表这个容器当有数据要插入时,都会检查容量有没有超过设定的thredhold,如果超过,需要增大Hash表的尺寸,但是这样一来,整个Hash表里的无素都需要被重算一遍。这叫rehash,这个成本相当的大。
相信大家对这个基础知识已经很熟悉了。
HashMap的rehash源代码
void transfer(Entry[] newTable, boolean rehash) int newCapacity = newTable.length; //for循环中的代码,逐个遍历链表,重新计算索引位置,将老数组数据复制到新数组中去(数组不存储实际数据,所以仅仅是拷贝引用而已)和 arraylist 或者 linkedlist 中的clone方法是一样的 都是浅拷贝关系 foreach (Entry<K,V> e : table) while(null != e) Entry<K,V> next = e.next; if (rehash) e.hash = null == e.key ? 0 : hash(e.key); int i = indexFor(e.hash, newCapacity); //将当前entry的next链指向新的索引位置,newTable[i]有可能为空,有可能也是个entry链,如果是entry链,直接在链表头部插入。
//第一次时 newTable[i] = null
e.next = newTable[i]; newTable[i] = e; e = next;
好了,这个代码算是比较正常的。而且没有什么问题。
正常的ReHash的过程
画了个图做了个演示。
- 我假设了我们的hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)。
- 最上面的是old hash 表,其中的Hash表的size=2, 所以key = 3, 7, 5,在mod 2以后都冲突在table[1]这里了。
- 接下来的三个步骤是Hash表 resize成4,然后所有的<key,value> 重新rehash的过程
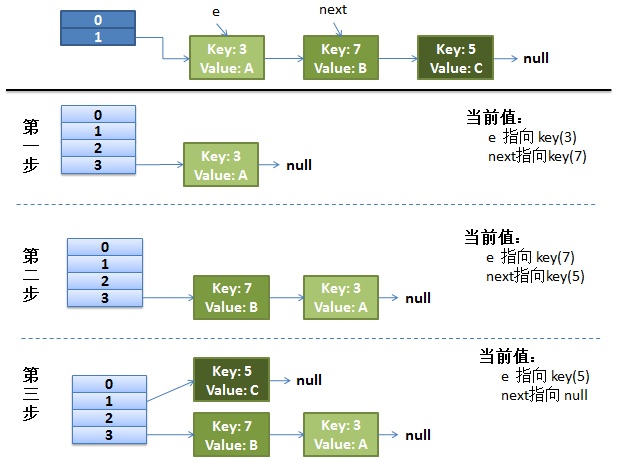
并发下的Rehash
1)假设我们有两个线程。我用红色和浅蓝色标注了一下。
我们再回头看一下我们的 transfer代码中的这个细节:
int i = indexFor(e.hash, newCapacity); //假设线程一执行到这 失去了运行权限 //将当前entry的next链指向新的索引位置,newTable[i]有可能为空,有可能也是个entry链,如果是entry链,直接在链表头部插入。 //第一次时 newTable[i] = null e.next = newTable[i]; newTable[i] = e; e = next;
而我们的线程二执行完成了。于是我们有下面的这个样子。
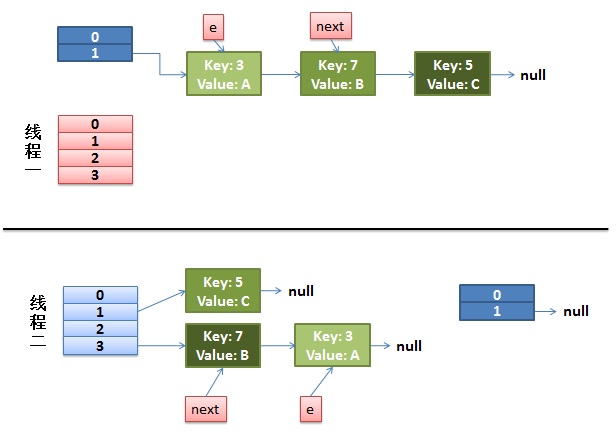
注意,因为Thread1的 e 指向了key(3),而next指向了key(7),其在线程二rehash后,指向了线程二重组后的链表。我们可以看到链表的顺序被反转后。
2)线程一被调度回来执行。
- 先是执行 newTalbe[i] = e;
- 然后是e = next,导致了e指向了key(7),
- 而下一次循环的next = e.next导致了next指向了key(3)
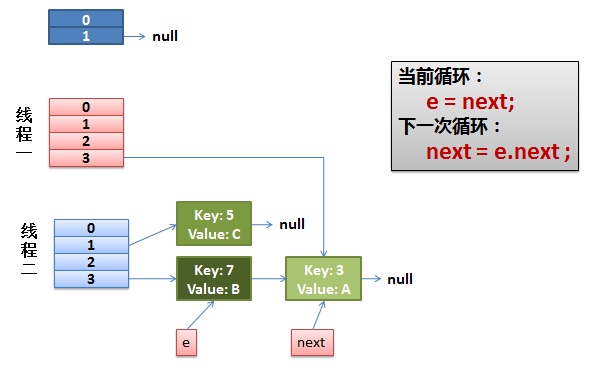
3)一切安好。
线程一接着工作。把key(7)摘下来,放到newTable[i]的第一个,然后把e和next往下移。
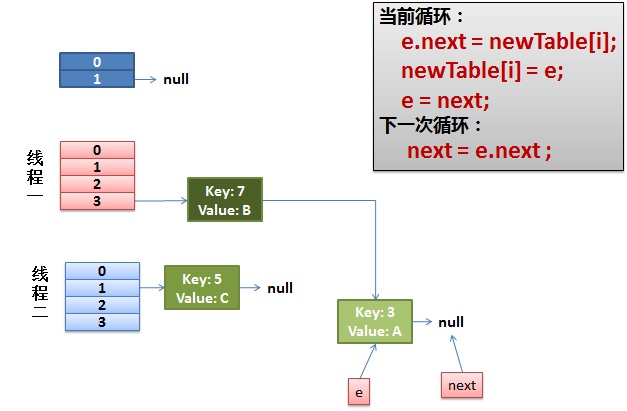
4)环形链接出现。
e.next = newTable[i] 导致 key(3).next 指向了 key(7)
注意:此时的key(7).next 已经指向了key(3), 环形链表就这样出现了。
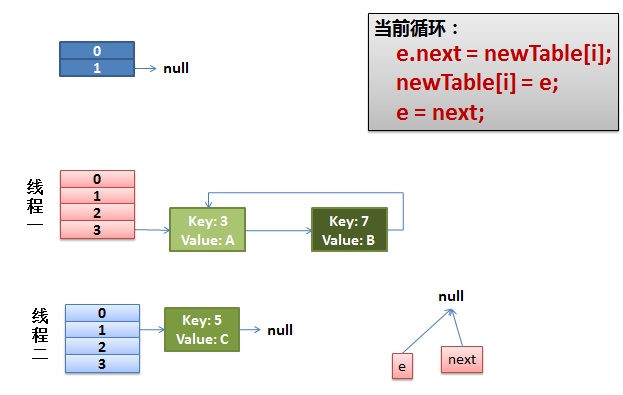
于是,当我们的线程一调用到,HashTable.get(11)时,悲剧就出现了——Infinite Loop。
三、问题解决:
if (oldTab != null) for (int j = 0; j < oldCap; ++j) Node<K,V> e; if ((e = oldTab[j]) != null) oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else // preserve order Node<K,V> loHead = null, loTail = null; // JDK1.8改进了rehash算法,扩容时,容量翻倍,新扩容部分,标识为hi,原来old的部分标识为lo Node<K,V> hiHead = null, hiTail = null; // 声明了队尾和队头指针。 Node<K,V> next; do next = e.next; if ((e.hash & oldCap) == 0) if (loTail == null) loHead = e; else loTail.next = e; loTail = e; else if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; while ((e = next) != null); if (loTail != null) loTail.next = null; newTab[j] = loHead; if (hiTail != null) hiTail.next = null; newTab[j + oldCap] = hiHead;
在 JavaScript 中循环遍历“Hashmap”
】在JavaScript中循环遍历“Hashmap”【英文标题】:Loopthrougha\'Hashmap\'inJavaScript【发布时间】:2011-10-0814:13:11【问题描述】:我正在使用this方法在javascript中制作人工“哈希图”。我的目标是键|值对,实际运行时间并不重要。下面... 查看详情
hashmap和list遍历方法总结及如何遍历删除
(一)List的遍历方法及如何实现遍历删除我们造一个list出来,接下来用不同方法遍历删除,如下代码:List<String>list=newArrayList<String>();famous.add("zs");famous.add("ls");famous.add("ww");famous.add("dz");1... 查看详情
集合hashmap来统计单个字在字符串中出现的次数(用hashmap来统计)
/* *统计单个字在字符串中出现的次数(用hashmap来统计) * *分析: * 1.先建立一个字符串 * 2.把字符串转换为数组 * 3.创建一个hashmap * 4.遍历数组,得到每个字符 * 5、拿得到的字符作为健到集合中去找值。得到返回值 * 是null:... 查看详情
三种方法任君挑选leetcode_136只出现一次的数字(代码片段)
LeetCode_136一、题目信息二、题解2.1、HashMap2.2、HashSet2.3、异或运算一、题目信息一个数组中有一个数只出现了一次,请你找到它。要求是具有线性的时间复杂度。二、题解2.1、HashMap用HashMap遍历数组,对每个数字记录他们... 查看详情
遍历hashmap的方法
1Mapmap=newHashMap();23for(Iteratoriter=map.entrySet().iterator();iter.hasNext();){45Map.Entryentry=(Map.Entry)iter.next();67Objectkey=entry.getKey();//得键89Objectval=entry.getValue();//得值1011}1213或者:1 查看详情
java中Entry接口的使用,而不是遍历HashMap类对象
】java中Entry接口的使用,而不是遍历HashMap类对象【英文标题】:UseofEntryinterfaceinjavaotherthaniteratingoverHashMapclassobjects【发布时间】:2021-10-1723:15:58【问题描述】:Entry接口用于在entrySet()和keySet()方法的帮助下迭代HashMap、LinkedHashMap... 查看详情
java中遍历hashmap的5种方式
本教程将为你展示Java中HashMap的几种典型遍历方式。如果你使用Java8,由于该版本JDK支持lambda表达式,可以采用第5种方式来遍历。如果你想使用泛型,可以参考方法3。如果你使用旧版JDK不支持泛型可以参考方法4。1、... 查看详情
java中hashmap的基本方法使用
遍历,添加词,等等packagetest;importjava.util.HashMap;importjava.util.Iterator;importjava.util.ArrayList;importjava.util.Collection;importjava.util.Map.Entry;importjava.util.Set;publicclasstest6{ publicstaticv 查看详情
java_hashmap的遍历方法_4种
1.通过接收keySet来遍历:HashMap<String,String>map=newHashMap<>();map.put("bb","12");map.put("aa","13");for(Stringeach:map.keySet()){System.out.println("key:"+each+"value:"+map.get(each));} 输出 查看详情
java中hashmap详解(代码片段)
HashMap详细解析HashMap的工作方式HashMap的实现原理HashMap的数据结构HashMap构造函数HashMap重要方法hash(K)put(K,V)resize()treeifyBin()get(K)Hash冲突HashMap总结HashMap中MAXIMUM_CAPACITY设置为1<<30HashMap中容量设置为2的整数幂次方HashMap中的负载因... 查看详情
剑指offer39.数组中出现次数超过一半的数字(代码片段)
...法一:哈希表哈希表:1.我们使用哈希映射(HashMap)来存储每个元素以及出现的次数。key表示匀速,vlaue表示次数2.我们用一个循环遍历数组nums并将数组中的每个元素加入到哈希映射中。3.之后我们遍历哈希映射中... 查看详情
链表中环的入口结点(代码片段)
...,直接返回即可classSolutionpublic:unordered_map<ListNode*,int>hashmap;//记录指针及其出现的次数+1ListNode*entryNodeOfLoop(ListNode*head)autop=head;intid=1;//因为hashmap默认就是0,如果id初值为0,造成混淆while(p)//无环将在这里退出if(hashmap[p])returnp;//... 查看详情
关于向hashmap存放数据出现顺序混乱的问题
...前三十天的所有日期(包括今天),然后存在“map”这个HashMap中,最后打印出来理论上应该是20181215 20181214 2018121320181212.....这样一天天往回倒过去但实际结果是。。。:完全不是按照顺序的,这是因为hashMap是不会保证你... 查看详情
使用hashmap计算一个字符串中每个字符出现的次数(代码片段)
...字符作为key,再定义一个计数器count作为value存储到一个HashMap集合中,若这个key只出现一次,则将value赋值为1,若key重复出现,则用后一个key覆盖前面的key,value值count++。逻辑代码如下:packagecom.lxx.Day06;importjav 查看详情
使用hashmap计算一个字符串中每个字符出现的次数(代码片段)
...字符作为key,再定义一个计数器count作为value存储到一个HashMap集合中,若这个key只出现一次,则将value赋值为1,若key重复出现,则用后一个key覆盖前面的key,value值count++。逻辑代码如下:packagecom.lxx.Day06;importjav 查看详情
linkedhashmap和hashmap的区别以及使用方法
顾名思义LinkedHashMap是比HashMap多了一个链表的结构。与HashMap相比LinkedHashMap维护的是一个具有双重链表的HashMap,LinkedHashMap支持2中排序一种是插入排序,一种是使用排序,最近使用的会移至尾部例如M1M2M3M4,使用M3后为M1M2M4M3了,Li... 查看详情
在java中遍历hashmap的5种最佳方式
原文地址:https://www.javaguides.net/2020/03/5-best-ways-to-iterate-over-hashmap-in-java.html作者:RameshFadatare翻译:高行行在本文中,我们将通过示例讨论在Java上遍历?HashMap?的五种最佳方式。使用?Iterator?遍历HashMapEntrySet使用?Iterator?遍历HashMap 查看详情
hashmap底层源码解析下(超详细图解)(代码片段)
前情回顾HashMap底层源码解析上文章目录前言HashMap成员方法put(Kkey,Vvalue)解读上述hash方法:resize扩容方法扩容机制resize源码remove源码get方法源码遍历HashMap集合的几种方式1.分别遍历key和Values2.使用iterator迭代器迭代3.通过get方式... 查看详情