关键词:
作者:
vivo - 人工智能推荐团队:何鑫、李恒、周健、黄金宝
背景
vivo 人工智能推荐算法团队在深耕业务同时,也在积极探索适用于搜索/广告/推荐大规模性稀疏性算法训练框架。分别探索了 tensornet/XDL/tfra 等框架及组件,这些框架组件在分布式、稀疏性功能上做了扩展,能够弥补 tensorflow 在搜索/广告/推荐大规模性稀疏性场景不足,但是在通用性、易用性以及功能特点上,这些框架存在各种不足。
DeepRec 是阿里巴巴集团提供的针对搜索、推荐、广告场景模型的训练/预测引擎,在分布式、图优化、算子、Runtime 等方面对稀疏模型进行了深度性能优化,提供了丰富的高维稀疏特征功能的支持。基于 DeepRec 进行模型迭代不仅能带来更好的业务效果,同时在 Training/Inference 性能有明显的性能提升。
作为 DeepRec 最早的一批社区用户,vivo 在 DeepRec 还是内部项目时,就与 DeepRec 开发者保持密切的合作。经过一年积累与打磨,DeepRec 赋能 vivo 各个业务增长,vivo 也作为 DeepRec 深度用户,将业务中的需求以及使用中的问题积极回馈到 DeepRec 开源社区。

业务介绍
vivo 人工智能推荐算法组的业务包含了信息流、视频、音乐、广告等搜索/广告/推荐各类业务,基本涵盖了搜广推各类型的业务。
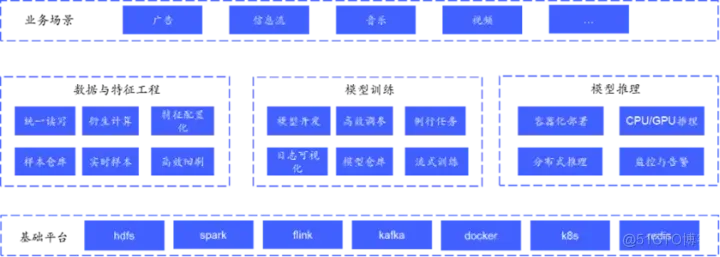
为了支撑上述场景的算法开发上线,vivo 自研了集特征数据、模型开发、模型推理等流程于一体的推荐服务平台。通过成熟、规范的推荐组件及服务,该平台为 vivo 内各推荐业务(广告、信息流等)提供一站式的推荐解决方案,便于业务快速构建推荐服务及算法策略高效迭代。
稀疏模型训练
3.1 稀疏功能
3.1.1 痛点
在实际业务实践发现,TensorFlow 原生 Embedding Layer 存在以下问题:

1.静态 Embedding OOV 问题
在构建 Embedding Layer 的时候,TensorFlow 需要首先构建一个静态 shape[Vocab_size, Embedding size ] 的 Variable,然后利用 Lookup 的算子将特征值的 Embedding 向量查询出。在增量或者流式训练中,会出现 OOV 的问题。
2. 静态 Embedding hash 特征冲突
为了规避上述的 OOV 问题,通常做法是将特征值 hash 到一定的范围,但是又会引入 hash 冲突的问题,导致不同的特征值共用同一个 Embedding,会造成信息丢失,对模型训练是有损的。
3. 静态 Embedding 内存浪费
为了缓解 hash 冲突,通常会设置比真实的特征值个数 N 大一到两倍的 hash 范围,而这又会强行地增加模型的体积。
4. 低频特征冗余
在引入稀疏特征时,出现频次较低以及许久未出现的特征 ID 对于模型而言是冗余的。此外,交叉特征占据了大量的存储,可以在不影响训练效果的前提下过滤掉这些特征 ID。因此,迫切需求特征淘汰以及准入机制。
总的来讲,TensorFlow 的 Embedding Layer 对真实的业务场景有几个不太友好的点,第一是可拓展性差,第二是 hash 冲突导致模型训练有损,第三是无法处理冗余的稀疏特征。而 DeepRec 巧妙地解决了上述问题,主要提供了基于 Embedding Variable 的动态 Embeeding 功能和特征准入/淘汰功能。
3.1.2 Embedding Variable

DeepRec 中的 EmbeddingVariable 以 HashTable 作为内部存储的基本结构,动态的创建/释放 Embedding 向量,适配了 Embedding 前向查询,反向更新等 OP,从而解决了用户的痛点。
在构建 Embedding Layer 时使用 DeepRec的Embedding Variable。利用 Embedding Variable 具有动态维度的特性,模型训练对新增的特征值无感知。此外,由于摒弃了 hash 的操作,训练的模型也是无损的,同时模型的体积也会缩小。
3.1.3 特征准入/淘汰
1. 特征准入:
DeepRec 提供了基于 BloomFilter 和 Counter 两种策略的准入机制。特征准入可以避免模型稀疏特征的快速增长,拒绝低频特征进入模型,影响模型收敛效果。
2. 特征淘汰:
DeepRec 支持两种淘汰策略,一种是按照 global step 进行淘汰,一种是按照 L2 weight 进行淘汰,它们将不符合规则的特征从模型参数中剔除,保证特征的有效性。
3.1.4 收益
1. 静态 Embedding 升级到动态 Embedding
使用 DeepRec 的动态 Eembedding 替换 TensorFlow 的静态 Embedding 后,保证所有特征 Embedding 无冲突,离线auc提升 0.5%,线上点击率提升 1.2%,同时模型体积缩小 20%。
2. ID 特征的利用
在使用 TensorFlow 时,vivo 尝试过对 ID 特征进行 hash 处理输入模型,实验表明这种操作对比基线具有负收益。这是由于 ID 特征过于稀疏,同时 ID 具有唯一指示性,hash 处理会带来大量的 Embedding 冲突。基于动态 Embedding,使用 ID 特征离线 auc 提升 0.4%,线上点击率提升 1%;同时配合 global step 特征淘汰,离线 auc 提升 0.2%,线上点击率提升 0.5%。
3.2 IO优化
3.2.1 痛点
目前 vivo 内部使用的是 TFRecord 数据格式存储训练数据,这种存储格式存在以下缺陷:
1. 占用存储空间大
由于 TFRecord 采用 protocol buffer 结构化数据存储,存储不够紧凑,占用空间比较大,在训练时 I/O 开销也非常大。vivo 尝试过利用 prebatch 的方式存储 TFRecord 以节省存储空间,但是此方案解析相对复杂,I/O 开销进一步加剧。
2. 非明文存储
由于 TFRecord 以二进制格式存储,无法直接查看数据内容,存在解析困难、不便进行数据分析的问题。
3.2.2 Parquet Dataset
Parquet 是一种列式存储的数据格式,能够节省存储资源,加快数据读取速度。DeepRec 的 Parquet Dataset 支持读取 Parquet 文件,开箱即用,无需额外安装第三库,使用简单方便。同时,Parquet Dataset 能够加快数据读取速度,提高模型训练的 I/O 性能。
3.2.3 收益
vivo 内部尝试使用 Parquet Dataset 来替换现有 TFRecord,提高训练速度 30%,减少样本存储成本 38%,降低带宽成本。同时,vivo 内部支持 hive 查询 Parquet 文件,算法工程师能够高效快捷地分析样本数据。
高性能推理框架
在业务逐渐发展过程中,广告召回量增长 3.5 倍,同时目标预估数增加两倍,推理计算复杂度增加,超时率超过 5%,严重影响线上服务可用性以及业务指标。因此,vivo 尝试探索升级改造现有推理服务,保证业务可持续发展。vivo 借助 DeepRec 开源的诸多推理优化功能,在 CPU 推理改造以及 GPU 推理升级方面进行探索,并取得一定收益。
4.1 CPU 推理优化
vivo 直接使用 TensorFlow 提供的 C++ 接口调用 Session::Run,无法实现多 Session 并发处理 Request,导致单 Session 无法实现 CPU 的有效利用。如果通过多 Instance 方式(多进程),无法共享底层的 Variable,导致大量使用内存,并且每个 Instance 各自加载一遍模型,严重影响资源的使用率和模型加载效率。为了提高 CPU 使用率,也尝试多组 Session Intra/Inter,均会导致 latency升高,服务可用性降低。
基于 ShareNothing 架构的 SessionGroup
DeepRec 提供的 SessionGroup 能够有效地解决上述问题,其基本架构如下图所示:
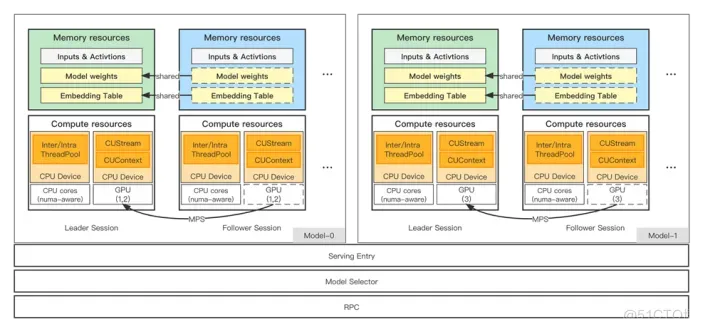
SessionGroup 可配置一组 Session,并且通过 Round Robin (支持用户自定义策略)方式将用户请求分发到某一个 Session。SessionGroup 对不同 Session 之间的资源进行隔离,每个 Session 拥有私有的线程池,并且支持每个线程池绑定底层的 CPU Core(numa-aware),可以最大程度地避免共享资源导致的锁冲突开销。SessionGroup 中唯一共享的资源是 Variable,所有 Session 共享底层的 Variable,并且模型加载只需要加载一次。
在使用 SessionGroup 功能后,CPU 使用率低的问题明显得到缓解,在保证 latency 的前提下极大提高 QPS,单机 QPS 提升高达 80%,单机 CPU 利用率提升 75%。
4.2 GPU 推理优化
经过 SessionGroup 的优化,虽然 CPU 推理性能得到改善,但是超时率依旧无法得到缓解。由于以下几点原因,vivo 尝试探索 GPU 推理来优化线上性能。
1. 多目标模型目标塔数较多
2. 模型中使用 Attention、LayerNorm、GateNet 等复杂结构
3. 特征多,存在大量稀疏特征
4.2.1 Device Placement Optimization
通常,对于稀疏特征的处理一般是将其 Embedding 化,由于模型中存在大量的稀疏特征,因此 vivo 的广告模型使用大量的 Embedding 算子。从推理的 timeline 可以看出,Embedding 算子分散在 timeline 的各个阶段,导致大量的 GPU kernel launch 以及数据拷贝,因此图计算非常耗时。
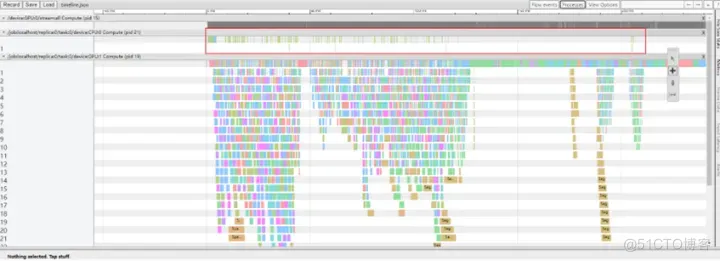
Device Placement Optimization 完全将 Embedding Layer placed 到 CPU 上,解决Embedding layer 内部存在的 CPU 和 GPU 之间大量数据拷贝问题。

Device Placement Optimization 性能优化明显,CPU 算子(主要是 Embedding Layer)的计算集中在 timeline 的最开端,之后 GPU 主要负责网络层的计算。相较于 CPU 推理,Device Placement Optimization P99 降低 35%。
4.2.2 CUDA Multi-Stream 功能
在推理过程中,vivo 发现 GPU 利用率低,GPU 算力浪费。DeepRec 支持用户使用 multi-stream 功能,多 stream 并发计算,提升 GPU 利用率。多线程并发 launch kernel 时,存在较大的锁开销,极大影响了 kernel launch 的效率,这里的锁与 CUDA Driver 中 Context 相关。因此可以通过使用 MPS/Multi-context 来避免 launch 过程中锁开销,从而进一步提升 GPU 有效利用率。

此外,模型中存在大量的 H2D 以及 D2H 的数据拷贝,在原生代码中,计算 stream 和拷贝 stream 是独立的,这会导致 stream 之间存在大量同步开销,同时对于在 Recv 算子之后的计算算子,必须等到 MemCopy 完成之后才能被 launch 执行,MemCopy 和 launch 难以 overlap 执行。基于以上问题,NV 专家计算团队的同学在 multi-stream 功能基础上进一步优化,开发了 MergeStream 功能,允许 MemCopy 和计算使用相同的 stream,从而减少上述的同步开销以及允许 Recv 之后计算算子 launch 开销被 overlap。

vivo 在线上推理服务中使用了 multi-stream 功能,P99 降低 18%。更进一步地,在使用 merge stream 功能后,P99 降低 11%。
4.2.3 编译优化-BladeDISC
BladeDISC 是阿里集团自主研发的、原生支持存在动态尺寸模型的深度学习编译器。DeepRec 中集成了 BladeDISC,通过使用 BladeDISC 内置的 aStitch 大尺度算子融合技术对于存在较多访存密集型算子的模型有显著的效果。利用 BladeDISC 对模型进行编译优化,推理性能得到大幅度提升。
BladeDISC 将大量访存密集型算子编译成一个大的融合算子,可以大大减少框架调度和 kernel launch 的开销。区别于其他深度学习编译器的是,BladeDISC 还会通过优化 GPU 不同层次存储(特别是 SharedMemory)的使用来提升了访存操作和 Op 间数据交换的性能。图中可以看到,绿色是 Blade DISC 优化合并的算子替代了原图中大量的算子。
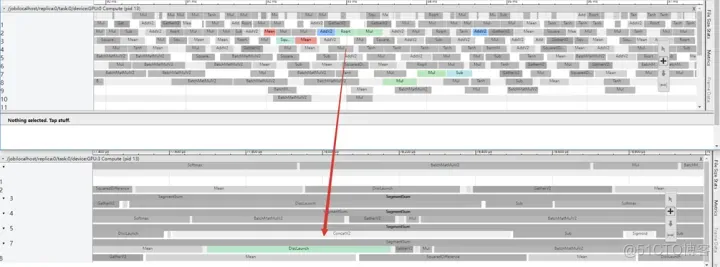

另外,由于线上模型比较复杂,为了进一步减少编译耗时、提升部署效率,vivo 启用了 BladeDISC 的编译缓存功能。开启此功能时,BladeDISC 仅会在新旧版本模型的 Graph 结构发生改变时触发编译,如果新旧模型仅有权重变更则复用之前的编译结果。经过验证,编译缓存在保证正确性的同时,几乎掩盖了编译模型的开销,模型更新速度与之前几乎相同。在使用 BladeDISC 功能后,线上服务 P99 降低 21%。
4.2.4 总结
DeepRec 提供大量的解决方案可以帮助用户快速实施 GPU 推理。经过一系列优化,相较于 CPU 推理,GPU 推理 P99 降低 50%,GPU 利用率平均在 60% 以上。此外,线上一张英伟达 T4 显卡的推理性能超过两台 CPU 机器,节省了大量的机器资源,机器成本降低 60%。
未来规划
基于 CPU 的分布式异步训练存在两个问题:一是异步训练会损失训练精度,模型难以收敛到最佳;二是随着模型结构逐渐复杂,训练性能会急剧下降。未来,vivo 打算尝试基于 GPU 的同步训练来加速复杂模型训练。DeepRec 支持两种 GPU 同步框架——SparseOperationKit(SOK)和HybridBackend。后续 vivo 将尝试这两种 GPU 同步训练来加速模型训练。
DeepRec开源地址:https://github.com/alibaba/Deep
全链路设计与实践
背景随着公司业务的高速发展,公司服务之间的调用关系愈加复杂,如何理清并跟踪它们之间的调用关系就显的比较关键。线上每一个请求会经过多个业务系统,并产生对各种缓存或者DB的访问,但是这些分散的数据对于问题排... 查看详情
vivo互联网机器学习平台的建设与实践
vivo互联网产品团队-Wangxiao随着广告和内容等推荐场景的扩展,算法模型也在不断演进迭代中。业务的不断增长,模型的训练、产出迫切需要进行平台化管理。vivo互联网机器学习平台主要业务场景包括游戏分发、商店、商城、内... 查看详情
全链路压测自动化实践
背景与意义境内度假是一个低频、与节假日典型相关的业务,流量在节假日较平日会上涨五到十几倍,会给生产系统带来非常大的风险。因此,在2018年春节前,我们把整个境内度假业务接入了全链路压测,来系统性地评估容量... 查看详情
redis内存优化在vivo的探索与实践
...相关的优化措施。分享vivo互联网技术干货与沙龙活动,推荐最新行业动态与热门会议。 查看详情
vivo服务端监控体系建设实践
...产品矩阵日趋完善,在vivo终端庞大的用户群体下,承载业务运行的服务数量众多,监控服务体系是业务可用性保障的重要一环,监控产品全场景覆盖生产环境各个环节。从事前发现,事中告警、定位、恢复,事后复盘总结,监... 查看详情
全链路压测(14):生产全链路压测sop
...全链路压测在技术实现上没有太多新花样,但要在不同的业务和企业落地,就各有各的实践路径。对于没有太多经验的同学来说,全链路压测的落地,大多还是基于个人的经验和熟悉的领域,即都是在局部作战,缺乏全局的视角... 查看详情
skywalking全链路监控集群和动态部署(代码片段)
随着近几年微服务的流行,各种业务的相互调用越来越频繁,对业务性能优化和故障诊断也会显的更加复杂。skywalking监控主要用于用户请求链路和路径的监控(拓扑图),能追踪到调用链路各个环节是否正常(错误的原因)和... 查看详情
04web前端性能优化
...生产场景、系统环境、模拟海量的用户请求和数据对整个业务链进行压力测试,并持续调优的过程2)解决的问题:针对业务场景越发复杂、海量数据冲击下整个业务系统链的可用性、服务能力的瓶颈,让技术更好的服务业务,... 查看详情
tensorflow在推荐系统中的分布式训练优化实践
...流水线优化、算子优化融合等多维度进行了深度优化。在推荐系统场景中,分布式扩展性提升10倍以上,单位算力性能也有显著提升,并在美团内部业务中大量使用,本文介绍了相关的优化与实践工作。1背景2大规模训练优化挑... 查看详情
深度粗排模型的gmv优化实践:基于全空间-子空间联合建模的蒸馏校准模型
...果。本文是对粗排模型优化的阶段性总结。背景在搜索、推荐、广告等大规模信息检索场景中,通常会将检索分为召回、粗排、精排三个阶段,每个阶段处理的数据量和目标各有不同。召回阶段,一般由多路召回构成... 查看详情
redis大集群扩容性能优化实践
...—YuanJianwei一、背景在现网环境,一些使用Redis集群的业务随着业务量的上涨,往往需要进行节点扩容操作。之前有了解到运维同学对一些节点数比较大的Redis集群进行扩容操作后,业务侧反映集群性能下降,具体... 查看详情
端到端qoe优化实践,视频播放体验优化,视频评测体系构建,基于大数据的vmaf质量计算...
...实践》王道环 vivo互联网研发经理随着vivo互联网在视频业务领域的不断扩展,在多样化的业务场景下,如何提升每个用户的视频播放体验,保障最优的播放流畅度和清晰度,vivo互联网技术团队做了很多尝试与突... 查看详情
性能测试的一些资料
...空间时间可靠性 HTTPS优化探索与实践 阿里巴巴全链路压测 HTTPS中S带来的性能损失 web应用内存分析与内存泄漏定位 有赞全链路压测方案设计与实施详解 京东全链路压测系统(ForceBot)架构解密&n 查看详情
redis在vivo推送平台的应用与优化实践
作者:vivo互联网服务器团队-YuQuan一、推送平台特点vivo推送平台是vivo公司向开发者提供的消息推送服务,通过在云端与客户端之间建立一条稳定、可靠的长连接,为开发者提供向客户端应用实时推送消息的服务,支持百亿级的... 查看详情
饿了么全链路压测平台的实现与原理
...我们曾介绍过饿了么的全链路压测的探索与实践,重点是业务模型的梳理与数据模型的构建,在形成脚本之后需要人工触发执行并分析数据和排查问题,整个过程实践下来主要还存在以下问题:测试成本较高,几乎每个环节都需... 查看详情
分布式链路追踪在字节跳动的实践
...基础上实现了新一代的一站式全链路观测诊断平台,帮助业务解决监控排障、链路梳理、性能分析等问题。本文将会介绍字节跳动链路追踪系统的整体功能和技术架构,以及实践过程中我们 查看详情
httpclient在vivo内销浏览器的高并发实践优化
...如果再遇到网络波动,如何保证连接被高效利用,有哪些优化空间。一、问题现象北京时间X月X日,浏览器信息流服务监控出现异常,主要表现在以下 查看详情
全链路异步,让你的springcloud性能优化10倍+(代码片段)
背景随着业务的发展,微服务应用的流量越来越大,使用到的资源也越来越多。在微服务架构下,大量的应用都是SpringCloud分布式架构,这种架构,总体是全链路同步模式。同步编程模式不仅造成了资源的极大... 查看详情