关键词:
5分钟理解Focal Loss与GHM——解决样本不平衡利器
------------------------------2019.12.10 更新了代码解析------------------------------------
Focal Loss for Dense Object Detection 是ICCV2017的Best student paper,文章思路很简单但非常具有开拓性意义,效果也非常令人称赞。
GHM(gradient harmonizing mechanism) 发表于 “Gradient Harmonized Single-stage Detector",AAAI2019,是基于Focal loss的改进,也是个人推荐的一篇深度学习必读文章。
第一部分 Focal Loss
Focal Loss的引入主要是为了解决难易样本数量不平衡(注意,有区别于正负样本数量不平衡)的问题,实际可以使用的范围非常广泛,为了方便解释,还是拿目标检测的应用场景来说明:
单阶段的目标检测器通常会产生高达100k的候选目标,只有极少数是正样本,正负样本数量非常不平衡。我们在计算分类的时候常用的损失——交叉熵的公式如下:
(1)
为了解决正负样本不平衡的问题,我们通常会在交叉熵损失的前面加上一个参数 ,即:
(2)
但这并不能解决全部问题。根据正、负、难、易,样本一共可以分为以下四类:
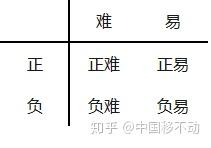
尽管 平衡了正负样本,但对难易样本的不平衡没有任何帮助。而实际上,目标检测中大量的候选目标都是像下图一样的易分样本。
这些样本的损失很低,但是由于数量极不平衡,易分样本的数量相对来讲太多,最终主导了总的损失。而本文的作者认为,易分样本(即,置信度高的样本)对模型的提升效果非常小,模型应该主要关注与那些难分样本(这个假设是有问题的,是GHM的主要改进对象)
这时候,Focal Loss就上场了!
一个简单的思想:把高置信度(p)样本的损失再降低一些不就好了吗!
(3)
举个例, 取2时,如果
,
,损失衰减了1000倍!
Focal Loss的最终形式结合了上面的公式(2). 这很好理解,公式(3)解决了难易样本的不平衡,公式(2)解决了正负样本的不平衡,将公式(2)与(3)结合使用,同时解决正负难易2个问题!
最终的Focal Loss形式如下:
实验表明 取2,
取0.25的时候效果最佳。

这样以来,训练过程关注对象的排序为正难>负难>正易>负易。
这就是Focal Loss,简单明了但特别有用。
Focal Loss的实现:
def py_sigmoid_focal_loss(pred,
target,
weight=None,
gamma=2.0,
alpha=0.25,
reduction=‘mean‘,
avg_factor=None):
pred_sigmoid = pred.sigmoid()
target = target.type_as(pred)
pt = (1 - pred_sigmoid) * target + pred_sigmoid * (1 - target)
focal_weight = (alpha * target + (1 - alpha) *
(1 - target)) * pt.pow(gamma)
loss = F.binary_cross_entropy_with_logits(
pred, target, reduction=‘none‘) * focal_weight
loss = weight_reduce_loss(loss, weight, reduction, avg_factor)
return loss这个代码很容易理解,
先定义一个pt:
然后计算:
focal_weight = (alpha * target + (1 - alpha) *(1 - target)) * pt.pow(gamma)也就是这个公式:
再把BCE损失*focal_weight就行了
代码来自于mmdetectionmmdetmodelslosses,这个python版的sigmoid_focal_loss实现就是让你拿去学习的,真正使用的是cuda编程版。真是个人性化的好框架
第二部分 GHM
那么,Focal Loss存在什么问题呢?
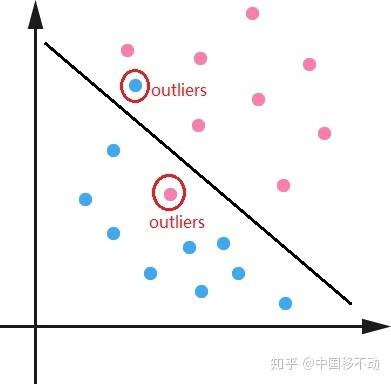
首先,让模型过多关注那些特别难分的样本肯定是存在问题的,样本中有离群点(outliers),可能模型已经收敛了但是这些离群点还是会被判断错误,让模型去关注这样的样本,怎么可能是最好的呢?
其次, 与
的取值全凭实验得出,且
和
要联合起来一起实验才行(也就是说,
和
的取值会相互影响)。
GHM(gradient harmonizing mechanism) 解决了上述两个问题。
Focal Loss是从置信度p的角度入手衰减loss,而GHM是一定范围置信度p的样本数量的角度衰减loss。
文章先定义了一个梯度模长g:
代码如下:
g = torch.abs(pred.sigmoid().detach() - target)其中 是模型预测的概率,
是 ground-truth的标签,
的取值为0或1.
g正比于检测的难易程度,g越大则检测难度越大。
至于为什么叫梯度模长,因为g是从交叉熵损失求梯度得来的:
假定 是样本的输出
,我们知道
,
那么 ,可以求出
看下图梯度模长与样本数量的关系:
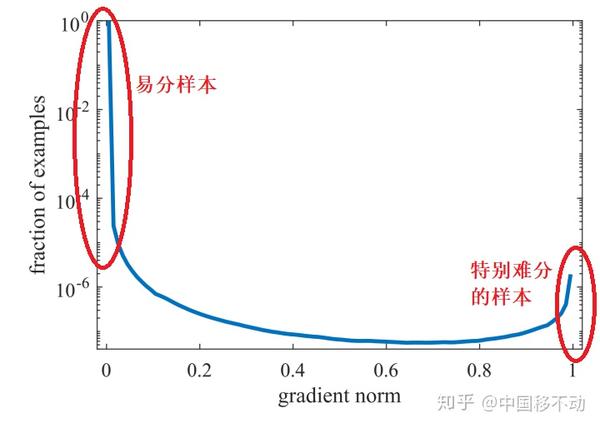
可以看到,梯度模长接近于0的样本数量最多,随着梯度模长的增长,样本数量迅速减少,但是在梯度模长接近于1时,样本数量也挺多。
GHM的想法是,我们确实不应该过多关注易分样本,但是特别难分的样本(outliers,离群点)也不该关注啊!
这些离群点的梯度模长d要比一般的样本大很多,如果模型被迫去关注这些样本,反而有可能降低模型的准确度!况且,这些样本的数量也很多!
那怎么同时衰减易分样本和特别难分的样本呢?太简单了,谁的数量多衰减谁呗!那怎么衰减数量多的呢?简单啊,定义一个变量,让这个变量能衡量出一定梯度范围内的样本数量——这不就是物理上密度的概念吗?
于是,作者定义了梯度密度 ——本文最重要的公式:
表明了样本1~N中,梯度模长分布在
范围内的样本个数,
代表了
区间的长度。
因此梯度密度 的物理含义是:单位梯度模长g部分的样本个数。
接下来就简单了,对于每个样本,把交叉熵CE×该样本梯度密度的倒数即可!
用于分类的GHM损失
, N是总的样本数量。
梯度密度的详细计算过程如下:
首先,把梯度模长范围划分成10个区域,这里要求输入必须经过sigmoid计算,这样梯度模长的范围就限制在0~1之间:
class GHMC(nn.Module):
def __init__(self, bins=10, ......):
self.bins = bins
edges = torch.arange(bins + 1).float() / bins
......
>>> edges = tensor([0.0000, 0.1000, 0.2000, 0.3000, 0.4000,
0.5000, 0.6000, 0.7000, 0.8000,0.9000, 1.0000])edges是每个区域的边界,有了边界就很容易计算出梯度模长落入哪个区间内。
然后根据网络输出pred和ground true计算loss:
注意,不管是Focal Loss还是GHM其实都是对不同样本赋予不同的权重,所以该代码前面计算的都是样本权重,最后计算GHM Loss就是调用了Pytorch自带的binary_cross_entropy_with_logits,将样本权重填进去。
# 计算梯度模长
g = torch.abs(pred.sigmoid().detach() - target)
# n 用来统计有效的区间数。
# 假如某个区间没有落入任何梯度模长,密度为0,需要额外考虑,不然取个倒数就无穷了。
n = 0 # n valid bins
# 通过循环计算落入10个bins的梯度模长数量
for i in range(self.bins):
inds = (g >= edges[i]) & (g < edges[i + 1]) & valid
num_in_bin = inds.sum().item()
if num_in_bin > 0:
# 重点,所谓的梯度密度就是1/num_in_bin
weights[inds] = num_labels / num_in_bin
n += 1
if n > 0:
weights = weights / n
# 把上面计算的weights填到binary_cross_entropy_with_logits里就行了
loss = torch.nn.functional.binary_cross_entropy_with_logits(
pred, target, weights, reduction=‘sum‘) / num_labels
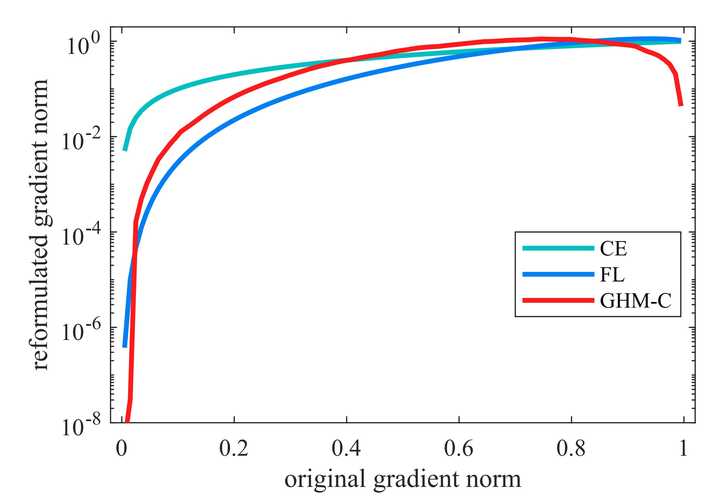
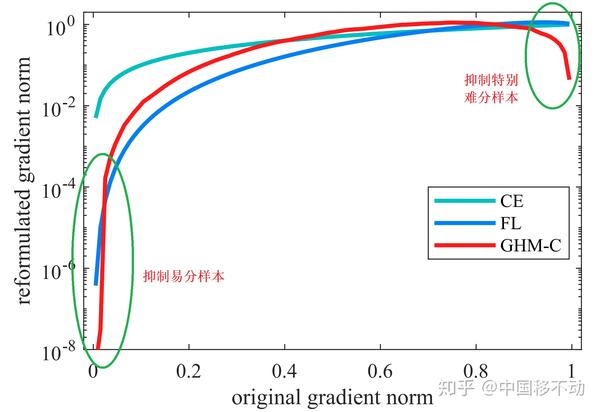
看看抑制的效果吧,也就是文章开头的这张图片:
同样,对于回归损失:
,其中
为修正的smooth L1 loss.
End~
因为本文着重论文的理解,很多细节没有写出,大家还是要去看一下原文的。
如果文中有错误还请批评指出!
参考资料:
Focal Loss for Dense Object DetectionGradient harmonized single-stage detector目标检测中的样本不平衡处理方法——ohem,focalloss,ghm,pisa
参考技术AGitHubCSDN目前。计算机视觉中的性能最好的目标检测方法主要分为两种:one-stage和two-stage方法。two-stage方法分为两步,第一步为候选区域生成阶段(Proposalstage),通过如SelectiveSearch、EdgeBoxes等方法可以生成数量相对较小候选... 查看详情
focalloss
...:https://www.cnblogs.com/king-lps/p/9497836.html在yolov3中可以使用focalloss,这是什么东西呢,这个loss主要是解决正负样本不均衡的问题的,该损失函数降低了大量简单负样本在训练中所占的权重,也可理解为一种困难样本挖掘。原来的交... 查看详情
focalloss两点理解
博客给出了三个算例。可以看出,focalloss对可很好分类的样本赋予了较小的权重,但是对分错和不易分的样本添加了较大的权重。对于类别不平衡,使用了$alpha_t$进行加权,文章中提到较好的值是0.25,说明在训练过程中仍然需... 查看详情
[repost]focalloss理解
FocalLoss理解对于其中的α\\alphaα取0.25反而降低了正样本权重的解释:通过一系列调参,得到α=0.25,y=2\\alpha=0.25,y=2α=0.25,y=2(在他的模型上)的效果最好。注意在他的任务中,正样本是属于少数样本也就... 查看详情
python实现focalloss(代码片段)
...问题,但仍然无法区分困难和简单的样本。这个问题通过focalloss解决了。focalloss Focalloss关注模型出错的样本,而不是它可以自信预测的样本,确保对困难样本的预测随着时间的推移而改进,而不是对简单的样本变得过于自信... 查看详情
focalloss的理解(代码片段)
论文:《FocalLossforDenseObjectDetection》FocalLoss是何恺明设计的为了解决one-stage目标检测在训练阶段前景类和背景类极度不均衡(如1:1000)的场景的损失函数。它是由二分类交叉熵改造而来的。标准交叉熵其中,p是模型预测属于类... 查看详情
focalloss
...,何凯明和RGB以二分类交叉熵为例提出了一种新的Loss----Focalloss原始的二分类交叉熵形式如下:FocalLoss形式如下: 上式中,相对于原始的二分类交叉熵加入了两个量:1、modulatingfactor:(其中幂称为focusingparameter);2、... 查看详情
目标检测:focalloss
目标检测:FocalLoss前言FocalLossCrossEntropybalancedCrossEntropyFocalLossDefinition前言Focalloss这个idea来源于论文《FocalLossforDenseObjectDetection》,主要是为了解决正负样本、难易样本不平衡的问题。FocalLossCrossEntropy在目标检测任务中,在... 查看详情
损失函数解读之focalloss(代码片段)
前言Focalloss是一个在目标检测领域常用的损失函数,它是何凯明大佬在RetinaNet网络中提出的,解决了目标检测中 正负样本极不平衡 和难分类样本学习 的问题。论文名称:FocalLossforDenseObjectDetection目录什么是正负样... 查看详情
处理样本不平衡的loss—focalloss(代码片段)
0前言FocalLoss是为了处理样本不平衡问题而提出的,经时间验证,在多种任务上,效果还是不错的。在理解FocalLoss前,需要先深刻理一下交叉熵损失,和带权重的交叉熵损失。然后我们从样本权利的角度出发,理解FocalLoss是如何... 查看详情
深度学习方法(十九):一文理解contrastiveloss,tripletloss,focalloss
...录1.ContrastiveLoss(对比loss)2.TripletLoss(三元loss)3.FocalLoss[5]3.1引申讨论:其他形式的FocalLoss参考资料本文记录一下三种常用的lossfunction:ContrastiveLoss,TripletLoss,FocalLoss。其中前面两个可以认为是rankingloss类... 查看详情
睿智的目标检测61——tensorflow2focalloss详解与在yolov4当中的实现(代码片段)
睿智的目标检测61——Tensorflow2Focalloss详解与在YoloV4当中的实现学习前言什么是FocalLoss一、控制正负样本的权重二、控制容易分类和难分类样本的权重三、两种权重控制方法合并实现方式学习前言TF2的也补上咯。其实和Keras的一摸... 查看详情
5分钟理解一致性哈希算法
5分钟理解一致性哈希算法 每天给你诚意满满的干货 来自:cywosp链接:https://blog.csdn.net/cywosp/article/details/23397179 一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为... 查看详情
[论文理解]focallossfordenseobjectdetection(retinanet)
FocalLossforDenseObjectDetectionIntro这又是一篇与何凯明大神有关的作品,文章主要解决了one-stage网络识别率普遍低于two-stage网络的问题,其指出其根本原因是样本类别不均衡导致,一针见血,通过改变传统的loss(CE)变为focalloss,瞬... 查看详情
理解neutronfwaas-每天5分钟玩转openstack(117)
650)this.width=650;"src="http://7xo6kd.com1.z0.glb.clouddn.com/upload-ueditor-image-20161124-1479989223359091731.jpg"/>前面我们学习了安全组,今天学习另一个与安全相关的服务--FWaaS。理解概念FirewallasaService(FWaaS)是Neutron的一个高级服务。用户 查看详情
focalloss分析
1)Classimbalance问题的提出Focalloss的提出就是问了解决Classimbalance问题,在两阶段目标检测算法中,这一问题是通过两阶段级联与启发式采样策略解决的(ClassimbalanceisaddressedinR-CNN-likedetectorsbyatwo-stagecascadeandsamplingheur... 查看详情
focalloss论文笔记(代码片段)
论文:《FocalLossforDenseObjectDetection》论文地址:https://arxiv.org/abs/1708.02002代码地址:官方github:https://github.com/facebookresearch/detectrontensorflow:https://github.com/tensorflow/modelshttps://github.com/fizyr/keras-retinanethttps://github.co... 查看详情
关于elasticsearch6.x及其插件head安装(单机与集群)5分钟解决
第一步,下载es6+headwgethttps://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.3.2.zipwget https://github.com/mobz/elasticsearch-head/archive/master.zip顺便安装一下node.js环境wget http 查看详情