关键词:
摘要:ING集团发表了《Efficient Scheduling Of High Performance Batch Computing For Analytics Workloads With Volcano - Krzysztof Adamski & Tinco Boekestijn, ING》主题演讲。
在KubeCon + CloudNativeCon North America,ING集团发表了《Efficient Scheduling Of High Performance Batch Computing For Analytics Workloads With Volcano - Krzysztof Adamski & Tinco Boekestijn, ING》主题演讲,重点介绍了云原生批量计算项目Volcano如何在数据管理平台中为大数据分析作业提供高性能调度工作。
详情参见:KubeCon + CloudNativeCon North America
ING背景介绍
ING集团(荷兰语:Internationale Nederlanden Groep),亦名荷兰国际集团,是一个国际金融服务私营企业,成立于1991年,由荷兰最大的保险公司Nationale-Nederlanden,与荷兰的第三大银行NMB PostBank Group合并而成。
ING集团的服务遍及全球40多个国家,核心业务是银行、保险及资产管理等。ING集团的全球职员大约56,000人,顾客5320万人,包括自然人、家庭,企业、政府及其他等,例如基金组织。
业务背景介绍
在银行行业有许多法规和限制,如:监管要求在全球范围内各不相同、数据孤岛-全局和本地限制、数据安全、合规创新等,想要快速引入新技术不是一件容易的事情,为此,ING布局符合自身产业的DAP平台(Data Analytics Platform),为全球50%的ING员工提供安全的、自助的端到端分析能力,帮助员工在数据平台之上构建并解决业务问题。

2013年开始我们有了数据平台的概念,2018年通过引入云原生技术打造新一代基础设施平台,从那时起,平台需求有了稳定的增长,采用率也在持续提升,目前数据索引平台上的项目已超过400个。我们所构建的平台目标是在高度安全的自助服务平台中完成所有分析需求,并且具备以下特点:
- 开源工具模型
- 强大的计算能力
- 严格的安全和合规措施
- 所有的分析集中在同一个平台
- 满足全球和本地需求
挑战与方案
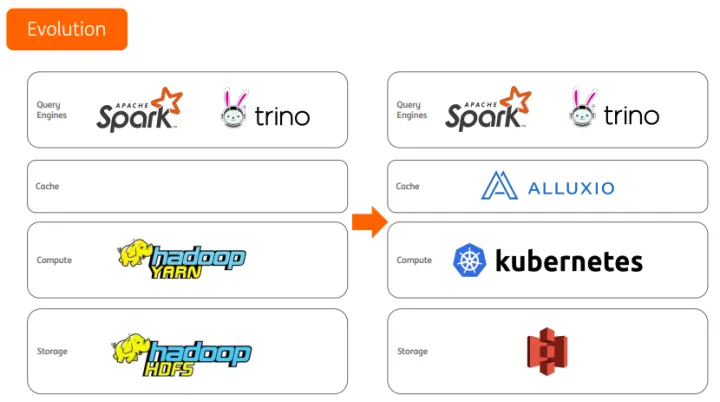
目前我们在由传统的Hadoop平台向Kubernetes过渡,但是对于作业管理和多框架支持方面还存在一些挑战,如下:
1.Job的管理
a.Pod级调度,无法感知上层应用
b.缺乏细粒度的生命周期管理
c.缺乏任务依赖关系,作业依赖关系
2.调度
a.缺少基于作业的调度,如:排序、优先级、抢占、公平调度、资源预定等
b.缺少足够的高级调度算法,如:CPU拓扑、任务拓扑、IO-Awareness,回填等
c.缺少对作业、队列、命名空间之间资源共享机制的支持
3.多框架支持
a.对Tensorflow、Pytorch等框架的支持不足
b.对每个框架部署(资源规划、共享)等管理比较复杂
利用Kubernetes来管理应用服务(无状态应用、甚至是有状态应用)是非常方便的,但是对于批量计算任务的调度管理不如yarn友好,同样yarn也存在一些限制,比如对新框架的支持不够完善,比如TensorFlow、Pytorch等,为此,我们也在寻找新的解决方案。
▍Kubernetes + Hadoop
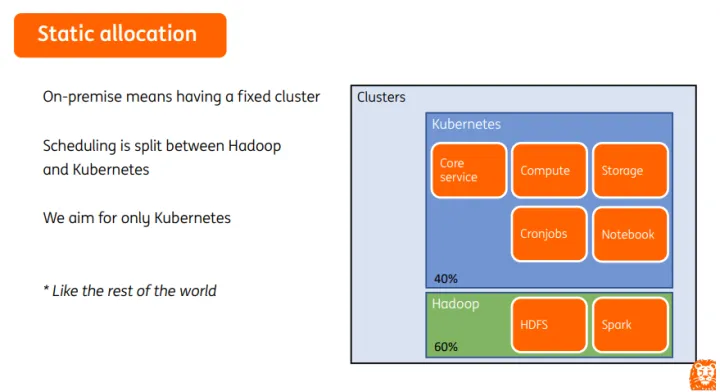
在我们之前的集群管理上,会把Hadoop和Kubernetes的调度分开,基本上所有的spark作业都会运行在Hadoop集群中,其他的一些任务和算法会运行在Kubernetes集群,我们的目标是希望所有的任务全部运行在Kubernetes集群,这样管理起来会更简单。

Kubernetes和YARN共同工作时,由于Kubernetes和Hadoop资源是静态划分的,在正常办公时间,Hadoop应用和Kubernetes各自使用自身分配资源,即便spark任务压力大也无法借用更多资源。夜晚时间,集群中仅有批处理任务,Kubernetes资源全部空闲,却无法分配给Hadoop进行有效利用,对于调度平台来讲,这不是一种最佳的资源分配方式。
▍Kubernetes with Volcano

使用Kubernetes管理整个集群,通过Volcano进行spark任务调度,此时不需要再对资源做静态划分,集群资源可根据Pod、Batch、Interactive任务的优先级、资源压力等进行动态调整,集群整体资源利用率得到极大提升。比如在正常办公时间内,常规服务应用资源空闲的情况下,Batch和Interactive应用资源需求增多时,可以暂时借用常规服务的资源;在假期和夜晚休息时,Batch业务可以使用集群所有资源进行数据计算,集群资源利用率得到极大提升。
比如在正常办公时间内,常规服务应用资源空闲的情况下,Batch和Interactive应用资源需求增多时,可以暂时借用常规服务的资源;在假期和夜晚休息时,Batch业务可以使用集群所有资源进行数据计算,集群资源利用率得到极大提升。

Volcano是专为Kubernetes而生的批处理调度引擎,其提供了以下能力:
- 加权优先级的作业队列
- 如果集群具有备用容量,可提交超过队列资源限制的任务
- 当更多的pod被调度时,具备抢占能力
- 丰富可配置的工作负载调度策略
- 兼容YARN的调度能力
Volcano的引入,补齐了Kubernetes平台对批处理作业的调度管理能力,并且自Apache Spark 3.3版本以来,Volcano被作为Spark on Kubernetes的默认batch调度器,安装使用更方便。
业务常用特性
▍冗余与局部亲和
Volcano保留Kubernetes中pod级别的亲和性反亲和性策略配置,并增加了task级别的亲和性和反亲和性策略。

▍DRF(Dominant Resource Fairness)调度
DRF调度算法的全称是Dominant Resource Fairness,是基于容器组Domaint Resource的调度算法。volcano-scheduler观察每个Job请求的主导资源,并将其作为对集群资源使用的一种度量,根据Job的主导资源,计算Job的share值,在调度的过程中,具有较低share值的Job将具有更高的调度优先级。
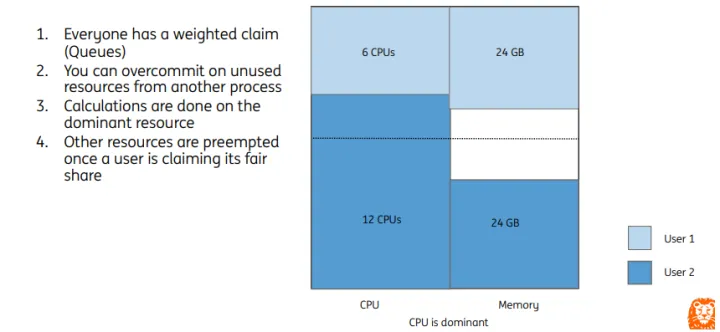
比如集群资源总量为CPU:18C,Memory:72GB,两个用户分别是User1和User2,每个User分配1个队列,在提交作业时会根据主导资源计算job的调度优先级。
- User1: CPU share值为 6/18=0.33,Memory share值为 24 / 72 = 0.33,最终share值为0.33
- User2:CPU share值为 12/18=0.67,Memory share值为 24 / 72 = 0.33,最终share值为0.67
DRF策略在任务调度时,优先分配share值较低的Job,即User1所申请的资源。
集群内队列资源可以通过配置权重值进行划分,但是当本队列提交任务超出队列分配的资源,并且其他队列存在资源空闲时,可以进行队列间资源共享。即User2在使用完本队列CPU资源后,可以使用User1队列内的空闲CPU资源。当User1队列提交新任务需要CPU资源时,将会触发抢占动作,回收User1被其他队列借用的资源。
▍避免资源匮乏
在使用过程中,需要避免批量计算任务与自有服务出现资源抢占与冲突的问题。比如:我们集群中有两个可用节点,集群中需要部署一个统一的服务层对外提供服务,比如Presto,或者类似Alluxio的缓存服务。但是在批量计算调度时,集群的资源空间有可能全部被占用,我们将无法完成自有服务的部署或升级,为此我们增加了空间可用系数相关配置,为集群预留一些备用空间,用于自有服务的部署使用。

▍DRF 仪表盘
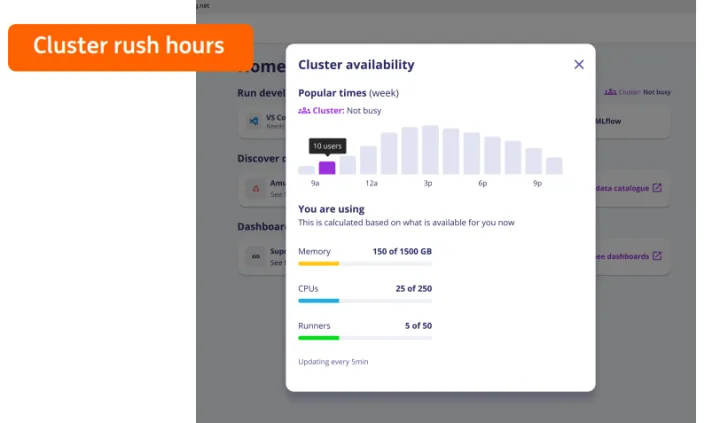
我们根据Volcano的监控数据做了一个drf调度的仪表盘,在不同层次显示更细粒度的调度信息。在业务集群中,我们有一个队列存放交互式用户的任务,另有队列存放平台运行的所有重大项目的计算任务,我们可以为重大项目队列提供一定的资源倾斜,但是此时对交互式用户的任务将不会太友好。
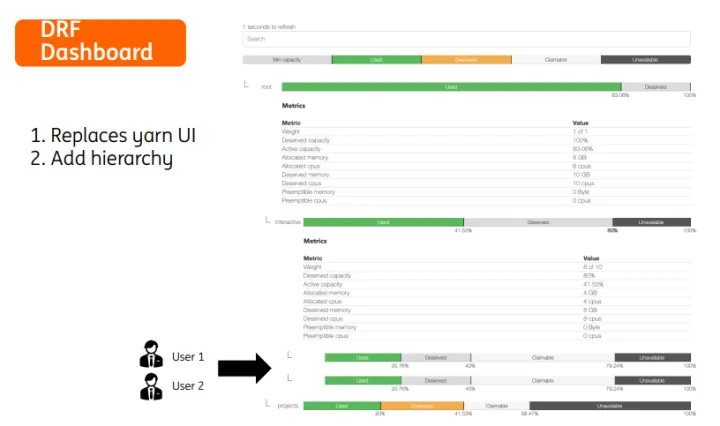
目前我们正在考虑增加集群高峰时段展示的功能,为用户提供更多的集群使用状态和压力等信息,在自助服务平台用户视角来看,用户按照集群的繁忙程度选择自己任务的开始时间,这样可以避免后台复杂的配置就可以获得高性能的运算体验。
总结
Volcano对批处理任务调度做了很好的抽象,使我们在Kubernetes平台能够获得更高的调度性能,后面我们也会将开发的功能逐步回合社区,比如:DRF Dashboard、在每个节点添加空闲空间、自动队列管理、更多的Prometheus监控指标、Grafana仪表盘更新、kube-state-metrics更新和集群角色限制等。
Volcano社区技术交流地址
Volcano官网:https://volcano.sh/en
GitHub : GitHub - volcano-sh/volcano: A Cloud Native Batch System (Project under CNCF)
每周例会: Launch Meeting - Zoom
基于html+echarts实现的大数据可视化平台模板(含源码)
...前国内最流行的前端数据图表插件。下面给大家分享几个基于ECharts实现的数据可视化大屏的通用模板。源码下载地址在文章末尾!效果演示大数据可视化模板1:大数据可视化平台模板2:大数据可视化系统分析平台&#x... 查看详情
基于jsp+ssm的银行报表平台系统
本系统是基于JSP的银行报表平台系统,使用java来实现动态管理以及数据库管理系统采用mysql等共同来完成。管理员可以通过银行报表平台系统进行负债表管理、角色管理、用户管理、部门管理、权限管理、资产表管理、员工... 查看详情
vefx维亿:六大国际银行资金分离存管,全面保障客户存款独立性
...交易更加放心 据了解,VEFX维亿股指期货选择了六大国际知名银行作为资产托管方,所有客户的隔离资产将存放于六大国际知名银行的客户 查看详情
基于智能合约的银行借贷方案设计与实现
摘要 针对银行借贷方式中个人、小微企业借款困难的现象,以及银行承担较高的资金风险,工作人员在借贷审核方面受主观因素影响较大的问题,基于区块链技术,提出一个基于智能合约的银行借贷方案。首先设计EBBI借贷... 查看详情
1-volcano火山:容器与批量计算的碰撞
...。而现在,每天要收集大量的数据,需要spark去做数据分析,甚至需要一些数据湖的产品去建立数据仓库,然后去做分析,产生报表。同时它还会用AI的一些系统,来简化业务流程等。因此 查看详情
2-volcano架构和设计原理解读
2-Volcano架构和设计原理解读随着容器技术的发展,越来越多的批量计算应用正在迁移到Kubernetes平台上,从早期的AI应用到大数据应用,再到近期的基因,转码,科学计算等HPC应用。在迁移过程中,高性能应... 查看详情
如何查询银行swift代码
1、一般情况下拨打银行热线能问到swift代码,2、登录Swift国际网站进行查询以中国银行上海分行为例,登录Swift国际网站查询页面后,根据提示填入您查询的银行信息。BICorinstitutionname中填入民生银行的统一代码:MSBCCNBJ;City中... 查看详情
超级好用的国际汇兑平台--transferwise
一年的CSC留学快结束了,手里还剩了些积攒下来的美元。就国内那点博士的工资,出来一趟好不容易领了点美元可不想都给银行汇兑的手续费给吞了去。这两天英国退欧,英镑大跌,美元有涨,是个把手里的美元寄回国换成人民... 查看详情
淘宝美团滴滴分别如何搭建大数据平台
常规的大数据平台架构方案是基于大数据平台Lamda架构设计的。事实上,业界也基本是按照这种架构模型搭建自己的大数据平台。下面我们来看一下淘宝、美团和滴滴的大数据平台,一方面进一步学习大厂大数据平台的架... 查看详情
volcano社区v1.6.0版本正式发布(代码片段)
摘要:Volcano社区v1.6.0版本正式发布。此次版本增加了弹性作业管理、基于真实负载的动态调度、基于真实负载的重调度、VolcanoJob插件——MPI等多个新特性。本文分享自华为云社区《Volcano社区v1.6.0版本正式发布》,作者&#... 查看详情
1-volcano火山:容器与批量计算的碰撞
1-Volcano火山:容器与批量计算的碰撞Volcano是基于Kubernetes的一个批处理调度系统,它为大数据、机器学习以及HPC等多种工作负载提供了作业生命周期的管理、调度以及资源管理一系列的功能,能够帮助弹性的工作负载... 查看详情
大数据专业学啥?
...论、计算机系统基础、并行体系结构与编程、非结构化大数据分析。大数据专业就业方向1、数据工程方向毕业生能够从事基于计算机、移动互联网、电子信息、电子商务技术、电子金融、电子政务、军事等领域的Java大数据分布... 查看详情
星图金融的银行存款合法吗星图金融的银行存款合法吗?
...eReport起家,目前已成为报表领域的权威者,拥有10年企业数据分析的行业经验。后发布的商业智能自助式BI工具FineBI,提供包括Hadoop、分布式数据库、多维数据库的大数据可视化分析;提供PC端、移动端、大屏的可视化方案,广... 查看详情
中国银行代码怎么查
...入卡号,发送过去;9、直接就可以查到机构代码。银行国际代码是由SWIFT协会提出并被ISO通过的银行识别代码,凡该协会的成员银行都有自己特定的SWIFT代码.在电汇时,汇出行按照收款行的SWIFTCODE发送付款电文,就可将款项汇至... 查看详情
用于医疗保健应用的大数据平台
】用于医疗保健应用的大数据平台【英文标题】:BigDataPlatformforahealthcareapplication【发布时间】:2019-05-2213:40:17【问题描述】:我必须使用大数据平台(NoSQL数据库,例如Elasticsearch)在python中开发一个Web应用程序(用于医疗保健... 查看详情
北京国际大数据交易所数据基于分布式存储技术交易系统上线
近日,北京国际大数据交易所(以下简称“北数所”)基于自主知识产权开发的数据交易平台IDeX系统上线。据了解,北数所IDeX系统是国内首家利用综合数据技术、探索数据交易创新模式的新平台,依托在隐私... 查看详情
“源”来是你-vol.33|浙江大应科技aloudata招聘开源社区运营
...仓架构的先行者,自主研发的AI增强湖仓引擎可实现数据分析性能自适应优化以及数据治理“自动驾驶”,帮助企业实现10倍以上的数据化运营效率提升。目前,Aloudata已顺利完成近亿元的两轮融资,红杉资本领投... 查看详情
干货+赠书|淘宝美团滴滴分别如何搭建大数据平台
...xff1a;核心原理与应用实践》常规的大数据平台架构方案是基于大数据平台Lamda架构设计的。事实上,业界也基本是按照这种架构模型搭建自己的大数据平台。接着我们来看一下淘宝、美团和滴滴的大数据平台,一方 查看详情