关键词:
(一)软件功能
实现两个功能:根据主题生成歌词和辅助写歌词
- 根据用户给定的主题生成一段歌词,歌词表达要流畅,语句通顺,押韵
- 提供相关的词语和句子供用户选择,使用户在帮助下完成歌词创作
核心模型
- 主题生成首句模型-相似度计算 + 基于SIF加权的word2vec模型
- 首句生成整段歌词模型-基本的Seq2Seq模型和双向Decoder + beam search的改进模型
(二) 核心模型
A. 主题生成首句模型--基于向量和基于字符的相似度模型 + 基于SIF加权的word2vec模型
事先划定20个主题词,将语料库的歌词人工标注为20类中的一种。将用户输入的主题和20个主题词对比,找到最相近的主题词。每个主题词下有30句预先定义了30句歌词,从这些歌词中随机抽取一句作为生成的首句。使用Dice相似度和基于SIF的word2vec方式。基于向量和基于字符的相似度模型
如果用户输入的字符已经存在的语料库中,那么直接使用输入字符的word embedding和预定义主题的word embedding做余弦相似度比较,余弦相似度可以将文本置于向量空间,解释性强,效果好。
如果用户输入的字符不在语料库中,那么使用基于字符的Dice相似度计算方式如下,这种计算方式可以是直接计算字符之间的相似度,不需要通过字符的向量表示。
Dice系数=$frac2*commmon(S_1,S_2)len(S_1)+len(S_2)$
基于SIF加权的word2vec模型
模型的目标是计算和主题词最相关的30句话。计算语料库每一句歌词中所有关键词的word embedding,使用SIF对所有词的word embedding加权平均。求得句子的embedding表示。计算主题词的embedding和句子embedding之间的相似度,找到相似度最大的30句歌词。word2vec原理
word2vec是个单层的神经网络,包括输入、隐含层和输出层。输入是词语的one hot向量,输出的是词语的在语义上的唯一向量表示embedding。Word2Vec包含两个模型:CBOW和Skip-gram。CBOW是上下文预测当前词的词向量;Skip-gram使用当前词预测上下文的词向量。在模型求解过程中使用分级是softmax和负采样方式加快算法。计算句子的word embedding
- 对句子中所有词的word vector求平均,获得sentence embedding,对不相关的词给太多权重。
- 以每个词的tf-idf为权重,对所有词的word embeddingr加权平均,获得sentence embedding
- 以SIF的方式计算权重,对所有词的word embedding加权平均,最后从中减掉principal component,得到sentence embedding。解决了tf-idf对出现频率过高词的权重的依赖。
SIF加权:类似词频计算权重的方法,但是这种方式多考虑不常见元素的权重。SIF取句中词嵌入的平均权重。每个词嵌入都由a/(a +p(w))进行加权,其中a的值经常被设置为0.01,而p(w)是词语在语料中出现的频率。常见元素删除:接下来,SIF计算了句子的嵌入中最重要的元素。然后它减去这些句子嵌入中的主要成分。这就可以删除与频率和句法有关的变量,他们和语义的联系不大。最后,SIF使一些不重要的词语的权重下降,例如but、just等,同时保留对语义贡献较大的信息。
B. 主题生成首句模型--押韵版模型和不押韵版模型
给定第一句生成一段歌词。输入是第一句歌词的字符形式,输出是几段歌词的字符形式。根据用户要求歌词分成押韵和不押韵两种。不押韵的基本模型是双LSTM+Decoder的Seq2Seq模型 + Attention + Beam Search加强模型效果。押韵和不押韵的区别在于押韵模型是双Decoder和自定义的Beam search方式。Seq2Seq + Attention + Beam search + Techer forcing模型
双向RNN
在经典的循环神经网络中,状态的传输是从前往后单向的。然而,在有些问题中,当前时刻的输出不仅和之前的状态有关系,也和之后的状态相关。我_ _ 想吃羊肉,要预测空格中的词语要同时看前后的词语的意思和时态、词性。这时就需要双向RNN(BiRNN)来解决这类问题。
双向RNN是由两个RNN上下叠加在一起组成的。输入是同时传到来个RNN,输出由这两个RNN的输出共同决定,一般采用均值的方式。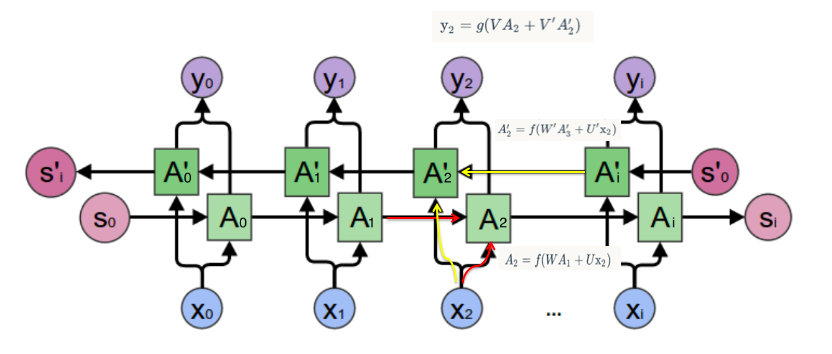
其中,正向计算时,隐藏层的 $s_t$ 与 $s_t-1$ 有关;反向计算时,隐藏层的 $s_t$ 与 $s_t+1$ 有关。
Seq2Seq
模型的目标是输入一句歌词生成下一句歌词。但是传统的LSTM神经网络存在两个问题:1.每个字词的预测和之前的预测结果是独立的。2.输入语句和输出语句的长度必须一致。但这是违反常规的,所以我们使用Seq2Seq模型,分成encoder和decoder模型,可以使输入语句和输出语句的长度不一样。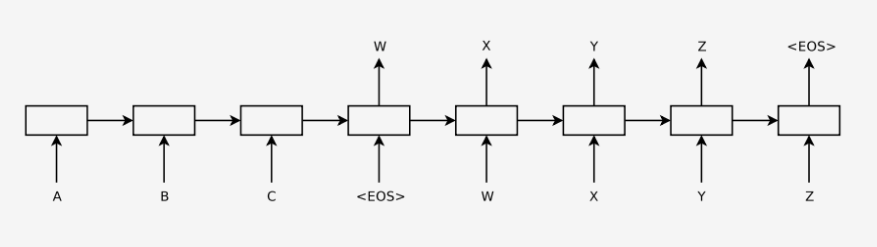
上图是Seq2Seq的总体流程图。
Encoder和Decoder分别是一个传统的RNN,encoder最后一个时刻的cell的hidden state输出到decoder的第一个cell里,通过激活函数和softmax层,得到候选的symbols,筛选出概率最大的symbols,作为下一个cell的输入。汇总所有的decoder的output就是最后的预测结果。
为什么要使用Encoder的最后一个hidden state?
在Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征c再解码,因此, c中包含原始序列中的所有信息。
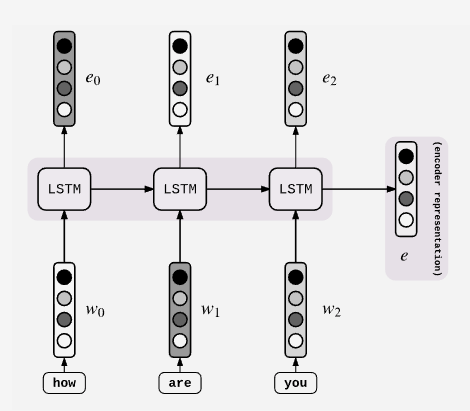
这是Encoder的构造,它和普通的RNN、LSTM没有区别。具体每个细胞接受的是每一个单词word embedding,和上一个时间点的hidden state。输出的是这个时间点的hidden state。
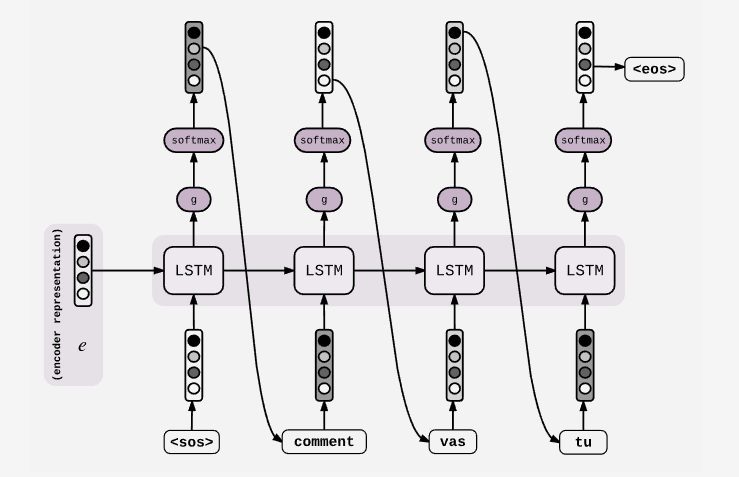
这是Decoder的构造,第一个cell是输入是encode的最后一个cell的hidden state,并且当前的output会输入到下一个cell中。
Attention
设计思想由于Seq2Seq模型中是将encoder的最后一个hidden state输入到decoder,encdoer要将整个序列的信息压缩进一个固定长度的向量中去。这就造成了 (1)语义向量无法完全表示整个序列的信息,(2)最开始输入的序列容易被后输入的序列给覆盖掉,会丢失许多细节信息。在长序列上表现的尤为明显。
引入Attention相比于之前的encoder-decoder模型,attention模型最大的区别就在于它不在要求编码器将所有输入信息都编码进一个固定长度的向量之中。相反,此时编码器需要将输入编码成一个向量的序列,而在解码的时候,每一步都会选择性的从向量序列中挑选一个子集进行进一步处理。这样,在产生每一个输出的时候,都能够做到充分利用输入序列携带的信息。
原理完整流程
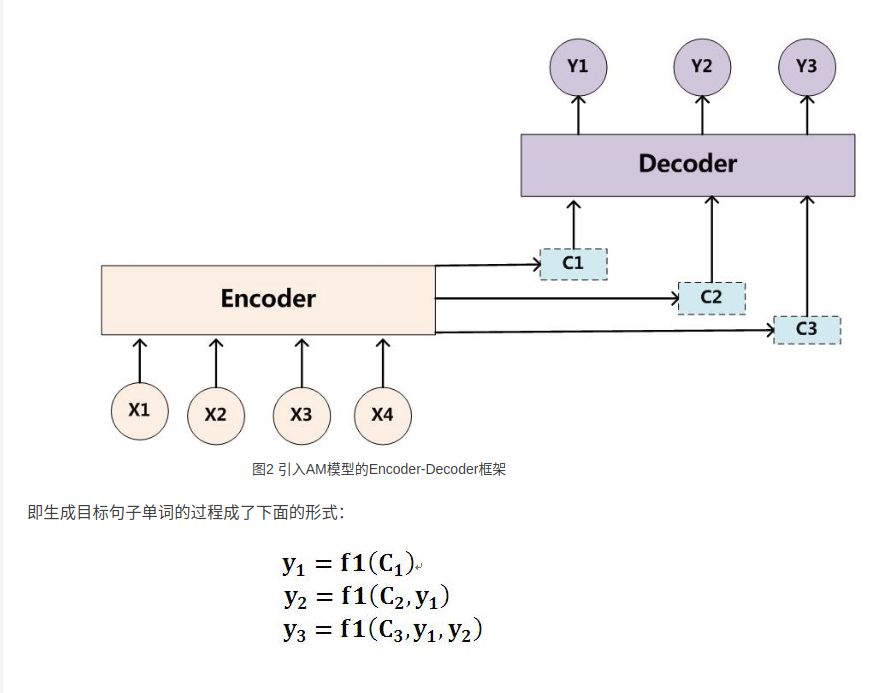
上图是Seq2Seq模型+Attentionmo模型的完整示意图。
现在的解码过程(Decoder)是:
预测当前词$y_i$需要当前时刻的$h_i$和$c_i$上下文向量和上一时刻的输出$y_i$
预测当前词的$h_i$需要上一时刻的$h_i-1,y_i-1$和$C_i$
计算$c_i$

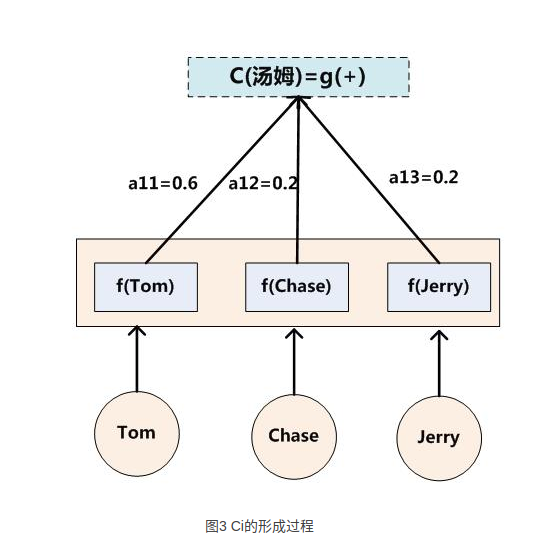
上图是计算$c_i$的完整过程示意图
其中:$c_i=sum_j=1^T_xalpha_ijh_j$,
$T_x$表示Encoder输入文本的长度,
$i$ 表示预测的第i个字符,
$j$ 表示Encoder中第j个字符,
$alpha_ij$ 表示:输入Encoder中的第j个字符对预测第i个字符的影响程度,
$h_j$ 表示输入Encoder的第j个字符的hidden state。
这个计算公式的本质意义就是将输入字符的hidden state加权。重点是权重的计算方式。
上图是计算$c_i$的图形过程示意图,之前的计算过程表示成图形就是这个样子的。
*计算$alpha_i$
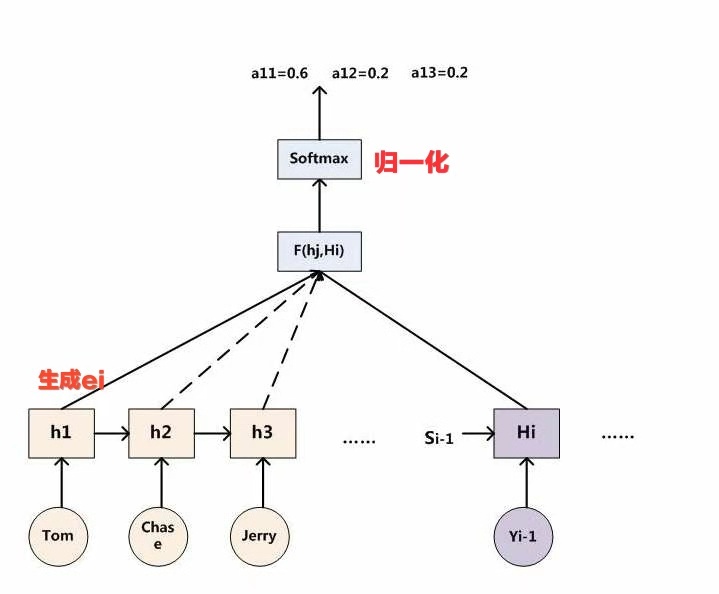
$alpha_ij=fracexp(e_ij)sum_k=1^T_xexp(e_ik) quad$,底下分母的意义就是归一化
$e_ij=a(y_i-1,h_j)$,意义就是将已经得到的预测输出和输入Encoder的文字做匹配计算,得到i时刻的输出和j时刻的输入之间的注意力分配关系。最后带入上一个公式计算$c_i$.
Attention分类- Soft Attention
就是我们刚才举例的模型,使用输入Encoder的所有hidden state加权取平均。我们使用的soft Attention类型。 - Hard Attention
使用概率抽样的方式,选择某个hidden state,估计梯度的时候也采用蒙特卡洛抽样的方法。
teacher forcing
Teacher Forcing是运用在解码过程中加强细胞的学习的方法。细胞接受来自上一个细胞的隐藏状态和细胞状态和上一个细胞的预测值的时候,这里细胞改成不用上一个细胞的预测值作为输出,用真实值作为输入,提高细胞的学习内容。
就拿Seq2Seq模型来举例,我们假设正输出到第三项,准备生成第四项:
input = [A,B,C,D]
output = [X,Y,Z,W]
label = [X,Y,N,W]押韵模型
输入是根据主题词生成的第一句歌词的反序形式和押韵要求(单押、双押、长度)。输出是一段按照符合预定义押韵形式的歌词。使用skip thought模型和改进的beam search模型。skip thought使模型产生的结果更通顺,beam search完成押韵的要求。Skip Thought
skip thought模型是双decoder,可以同时预测当前句子的上一句和下一句,使梯度回传到Encoder,增强encoder的参数学习,更好地捕捉前后文的信息。同时Encode和Decoder之间使用均值的方式连接。
Beam search
Beam Search是运用在inference阶段的加强预测结果的方法。它改进了贪婪解码中只选择一个得分最大的词语作为输出的方式,而是选出得分最大的K个词,在下一步的时候在当前选择的词语的基础上还是选择K个单词,然后不断沿着时间步长走下去,保证整体得到的结果最优。
有了首句之后,不是直接搜索首句韵脚相同的词语,而且先通过skip thought模型得到首句的上一句和下一句和最后一个细胞的输出(语料库的词语的概率分布),用概率最大并且满足韵脚的词语作为歌词末尾的韵脚歌词,使用自定义的beam search方式,使其从最后一个押韵词开始向前搜索每个词语,直至遇到停止符,输出整个语句。
hiphop嘻哈音乐的具体分类?
...,Kurmp,Regge,这些舞蹈所相对应的舞曲都各属于什么类型的嘻哈音乐?我需要专业的Dancer提供关于舞曲的分类以及现流行明星以及起代表作.嘻哈(hiphop)是一种源自非洲原始部落的生活态度。它首先在纽约市市区的非裔及拉丁裔青年... 查看详情
ai自动写代码插件copilot(副驾驶员)(代码片段)
AI自动写代码插件Copilot提示:Copilot单词直译过来就是副驾驶员的意思。介绍:本质上就是基于GitHub开源的亿级别的代码,训练AI模型,自动生成代码。就是数据量(GitHub的数据量就很大!)能够决定你AI模型精度... 查看详情
ai自动写代码插件copilot(副驾驶员)(代码片段)
AI自动写代码插件Copilot提示:Copilot单词直译过来就是副驾驶员的意思。介绍:本质上就是基于GitHub开源的亿级别的代码,训练AI模型,自动生成代码。就是数据量(GitHub的数据量就很大!)能够决定你AI模型精度... 查看详情
智能视觉组参赛总结及体会-西安邮电大学-ai小布丁(代码片段)
§01参赛总结 卓老师您好,我们是西安邮电大学参与16届智能视觉组的代表队,很荣幸拿到了今年全国总决赛一等奖的好成绩。下面我将分享我们的参赛总结。Ⅰ.总体分析 相较于15届的AI电磁以及今年的室外越野... 查看详情
中国有嘻哈——押韵机器人
押韵机器人简介近来群里看到有人谈起押韵机器,突然想起好多年前的回忆。心血来潮写了一个押韵机器人。可以识别韵脚、比较韵脚、词汇列表按韵脚分类。 经测试,目前对多音字支持不好:比如唠嗑,唠叨。这种就识别... 查看详情
浅谈动感歌词-歌词生成篇
1引言在写这生成篇时,我还是在烦恼应该是先写歌词解析篇,还是先写歌词生成篇,后来我想一想,其实还是要先有歌词文件,才有解析嘛,当然,我们也可以通过现有的歌词(krc、trc和ksc等)直接跳过这一步,直接解析歌词... 查看详情
《设计模式》学习总结(上)——八大设计原则(代码片段)
...课一个非常好的地方就是对每个模式讲解前先按照不考虑软件系统扩展性的思路写一份强耦合的代码,然后对其存在的问题进行分析,最后自然而然地引出相应的设计模式,这其实也是我们写代码时的一个过程,一般完美的软件... 查看详情
还在调api写所谓的ai“女友”,唠了唠了,教你基于python咱们“new”一个(深度学习)(代码片段)
...derAttention机制decoder与beamsearch加载驱动Seq2Seq搭建训练预测总结前言诶,标题有 查看详情
用ai写代码--githubcopilot测试(代码片段)
截图为copilot官网要使用copilot,首先要安装vscode。下载copilot插件。下载完了以后,并不能马上使用。还需要申请内测账号,前几天,我终于收到内测账号通过的邮件。趁着今天在家,连忙打开vscode测试一下。... 查看详情
ai-testops——软件测试工程师的一把利剑(代码片段)
写在前面软件测试的前世今生测试工具开始盛行AI-TestOps云平台●AI-TestOps功能模块●AI-TestOps自动化测试流程写在前面最近偶然间看到一句话:“软件测试是整个IT行业中最差的岗位”。这顿时激起了我对软件测试领域的兴趣&#... 查看详情
智能车竞赛视觉ai组总结西南科技大学–西科二队(代码片段)
§01参赛体会与建议一、参赛体会在本次比赛中,我们使用的是NXP公司的RT1064芯片。该芯片具有600M主频以及1M的ram,这样的性能提供了极高的可玩性,实测使用八邻域算法处理原始图像并获得偏差只需要0.3ms。可以很快实... 查看详情
年度总结年度总结(代码片段)
...朱老师看到了,朱老师就提议能不能建立一个校园的特色软件开发组。然后逐渐后期我加入了资源检索、在线视频流、在线电视、以及其他的什么东东。。。。后来项目快结束的时候了,我就开始整合全部的资源,匆匆忙忙写了... 查看详情
免杀思路总结(代码片段)
免杀思路总结1.免杀技术简介2.杀毒软件检测方法3.绕过技术1.免杀技术简介1.免杀的重要性2.免杀的难度3.杀毒软件的排行国外国内1、Bitdefender1、3602、Norton3602、智量安全(没测过,据说很厉害)3、Kaspersky 3、火绒安全4、Webroot 4... 查看详情
2020下半年总结(代码片段)
2020下半年总结文章目录2020下半年总结1.下半年经历回顾2.反思自己的stereotype3.展望20211.下半年经历回顾人的经历总是要总结的,因为总结,人才能在之前的基础上有所进步,才能不忘历史,不惧将来。很惭愧拖到... 查看详情
如何用python写一个贪吃蛇ai(代码片段)
前言这两天在网上看到一张让人涨姿势的图片,图片中展示的是贪吃蛇游戏,估计大部分人都玩过。但如果仅仅是贪吃蛇游戏,那么它就没有什么让人涨姿势的地方了。问题的关键在于,图片中的贪吃蛇真的很贪吃XD,它把矩形... 查看详情
校招实习面试实战,身临其境华为软件开发工程师面试复盘总结(代码片段)
【校招实习面试实战,身临其境】华为软件开发工程师面试复盘总结自我介绍1、是否用过Java、Python做系统的项目2、华为云系统开发js写业务逻辑用的是ES6还是ES5标准3、平时熟练使用哪种语言4、HashMap、HashSet、HashTable、StringB... 查看详情
html写静态页面容易写错总结(代码片段)
html写静态页面容易写错总结写静态页面的注意点,避免页面崩溃1.整个页面在写之前首先应该先把大的框架搭出来,在去写里面小的细节。保证大的框架没有问题,里面有问题,大不了删了重写。(给大的框... 查看详情
这里可以写总结(代码片段)
文章目录前言项目引入项目介绍推荐理由场景展示总结前言提示:可以在这里写项目推荐的初衷,记得删除示例哦。例如:Web开发中几乎的平台都需要一个后台管理,但是从零开发一套后台控制面板并不容易,... 查看详情