关键词:
一、前述
LDA是一种 非监督机器学习 技术,可以用来识别大规模文档集(document collection)或语料库(corpus)中潜藏的主题信息。它采用了词袋(bag of words)的方法,这种方法将每一篇文档视为一个词频向量,从而将文本信息转化为了易于建模的数字信息。但是词袋方法没有考虑词与词之间的顺序,这简化了问题的复杂性,同时也为模型的改进提供了契机。每一篇文档代表了一些主题所构成的一个概率分布,而每一个主题又代表了很多单词所构成的一个概率分布。由于 Dirichlet分布随机向量各分量间的弱相关性(之所以还有点“相关”,是因为各分量之和必须为1),使得我们假想的潜在主题之间也几乎是不相关的,这与很多实际问题并不相符,从而造成了LDA的又一个遗留问题。
二、具体过程
语料库中的每一篇文档与T(通过反复试验等方法事先给定)个主题的一个多项分布 (multinomialdistribution)相对应,将该多项分布记为θ。每个主题又与词汇表(vocabulary)中的V个单词的一个多项分布相对应,将这个多项分布记为φ。
三、案例
假设文章1开始有以下单词:
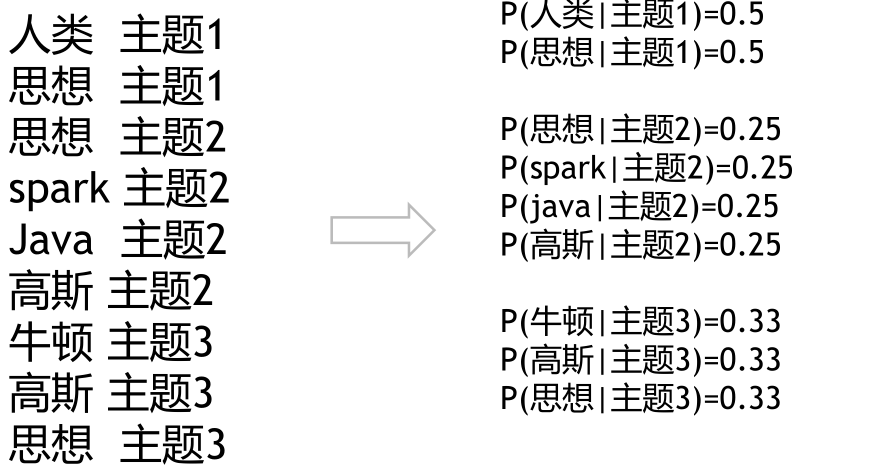

高斯分为主题二,是因为有一定的概率。

如此反复,当各个概率分布不再发生变化时,即完成了收敛和训练过程
训练思想仍然是EM算法(摁住一个,去计算另一个)
对比K-means
实际工程过程中:
每一个主题对每一个词都有一个基本出现次数(人工设定)
每一篇文章在各个主题上都有一个基本出现词数
步骤:
新来一片文章,需要确定它的主题分布:
先随机化主题分布
1.根据主题分布和主题-单词模型,找寻每个
单词所对应的主题
2.根据单词主题重新确定主题分布
1,2反复,直到主题分布稳定 最终得到两个模型:
1.每篇文章的主题分布
2.每个主题产生词的概率
用途:
1.根据文章的主题分布,计算文章之间的相似性
2.计算各个词语之间的相似度
四、代码
# -*- coding: utf-8 -*- import jieba from sklearn.feature_extraction.text import CountVectorizer from sklearn.decomposition import LatentDirichletAllocation for i in range(4): with open(\'./data/nlp_test%d.txt\' % i, encoding=\'UTF-8\') as f: document = f.read() document_cut = jieba.cut(document) result = \' \'.join(document_cut) print(result) with open(\'./data/nlp_test%d.txt\' % (i+10), \'w\', encoding=\'UTF-8\') as f2: f2.write(result) f.close() f2.close() # 从文件导入停用词表 stpwrdpath = "./data/stop_words.txt" stpwrd_dic = open(stpwrdpath, \'r\', encoding=\'UTF-8\') stpwrd_content = stpwrd_dic.read() # 将停用词表转换为list stpwrdlst = stpwrd_content.splitlines() stpwrd_dic.close() print(stpwrdlst) # 向量化 不需要tf_idf corpus = [] for i in range(4): with open(\'./data/nlp_test%d.txt\' % (i+10), \'r\', encoding=\'UTF-8\') as f: res = f.read() corpus.append(res) print(res) cntVector = CountVectorizer(stop_words=stpwrdlst) cntTf = cntVector.fit_transform(corpus) print(cntTf) # 打印输出对应关系 # 获取词袋模型中的所有词 wordlist = cntVector.get_feature_names() # 元素a[i][j]表示j词在i类文本中的权重 weightlist = cntTf.toarray() # 打印每类文本的词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重 for i in range(len(weightlist)): print("-------第", i, "段文本的词语权重------") for j in range(len(wordlist)): print(wordlist[j], weightlist[i][j]) lda = LatentDirichletAllocation(n_components=3,#3个话题 learning_method=\'batch\', random_state=0) docres = lda.fit_transform(cntTf) print("文章的主题分布如下:") print(docres) print("主题的词分布如下:") print(lda.components_)
☀️机器学习入门☀️pca和lda降维算法|附加小练习(文末送书)(代码片段)
🎉粉丝福利送书:《人工智能数学基础》🎉点赞👍收藏⭐留言📝即可参与抽奖送书🎉下周三(9月22日)晚上20:00将会在【点赞区和评论区】抽一位粉丝送这本书~🙉🎉详情请看第三点的介绍嗷~... 查看详情
机器学习&sklearn笔记:lda(线性判别分析)(代码片段)
1介绍1.有监督的降维2.投影后类内方差最小,类间方差最大 2推导我们记最佳的投影向量为w,那么一个样例x到方向向量w上的投影可以表示为:给定数据集令分别表示第i类的样本个数、样本集合、均值向量和协方差... 查看详情
机器学习基础---应用实例(图片文字识别)和总结(代码片段)
一:问题描述和流程图将介绍一种机器学习的应用实例:照片OCR技术,介绍它的原因:(1)首先,展示一个复杂的机器学习系统是如何被组合起来的;(2)接着,介绍一下机器学习流水线的有关概念以及如何分配资源来对下一... 查看详情
我的机器学习/深度学习之路--lda线性判别分析(代码片段)
关于LDA的理论方面,不过多赘述。只写一下我对这个算法的一些感想与验证过程。只说二分分类问题:数据采用(3条消息)史上最好的LDA(线性判别分析)教程_jnulzl的专栏-CSDN博客_lda线性判别分析这篇博客的。这篇博客是用ma... 查看详情
python机器学习《机器学习python实践》整理,sklearn库应用详解(代码片段)
TableofContents1 初始1.1 初识机器学习1.2 python机器学习的生态圈1.3 第一个机器学习项目1.3.1 机器学习中的helloworld项目1.3.2 导入数据1.3.3 概述数据1.3.4 数据可视化1.3.5 评估算法1.3.5.1 分离评估数据集1.3.5.2 创... 查看详情
spark机器学习:lda主题模型算法
...进行,就可以生成一篇文档;反过来,LDA又是一种非监督机器学习技术,可以识别出大规模文档集或语料库中的主题。LDA原始 查看详情
机器学习——降维(主成分分析pca线性判别分析lda奇异值分解svd局部线性嵌入lle)
机器学习——降维(主成分分析PCA、线性判别分析LDA、奇异值分解SVD、局部线性嵌入LLE)以下资料并非本人原创,因为觉得石头写的好,所以才转发备忘(主成分分析(PCA)原理总结)[https://mp.weixin.qq.com/s/XuXK4inb9Yi-4ELCe_i0EA]来源:?... 查看详情
机器学习笔记(代码片段)
机器学习笔记(四)文章目录机器学习笔记(四)线性判别分析多分类学习类别不平衡问题小总结决策树决策树的基本概念决策树的构造ID3算法C4.5算法CART算法线性判别分析线性判别分析(LinearDiscriminantAnalysis&... 查看详情
机器学习笔记(代码片段)
机器学习笔记(四)文章目录机器学习笔记(四)线性判别分析多分类学习类别不平衡问题小总结决策树决策树的基本概念决策树的构造ID3算法C4.5算法CART算法线性判别分析线性判别分析(LinearDiscriminantAnalysis&... 查看详情
机器学习笔记(代码片段)
机器学习笔记(四)文章目录机器学习笔记(四)线性判别分析多分类学习类别不平衡问题小总结决策树决策树的基本概念决策树的构造ID3算法C4.5算法CART算法线性判别分析线性判别分析(LinearDiscriminantAnalysis&... 查看详情
机器学习笔记(代码片段)
机器学习笔记(四)文章目录机器学习笔记(四)线性判别分析多分类学习类别不平衡问题小总结决策树决策树的基本概念决策树的构造ID3算法C4.5算法CART算法线性判别分析线性判别分析(LinearDiscriminantAnalysis&... 查看详情
《机器学习实战》-机器学习基础(代码片段)
目录机器学习基础什么是机器学习机器学习应用场景海量数据机器学习的重要性机器学习的基本术语监督学习和非监督学习监督学习:supervisedlearning非监督学习:unsupervisedlearning机器学习工具介绍Python非PythonNumPy函数库基础测试Nu... 查看详情
机器学习:线性判别式分析(lda)
1.概述 线性判别式分析(LinearDiscriminantAnalysis),简称为LDA。也称为Fisher线性判别(FisherLinearDiscriminant,FLD),是模式识别的经典算法,在1996年由Belhumeur引入模式识别和人工智能领域。&nbs... 查看详情
[python人工智能]三十一.keras实现bilstm微博情感分类和lda主题挖掘分析(上)(代码片段)
...文本挖掘介绍微博情感分类知识,包括数据预处理、机器学习和深度学习的情感分类,后续结合LDA进行主题挖掘。基础性文章,希望对您有所帮助ÿ 查看详情
机器学习入门-文本特征-使用lda主题模型构造标签1.latentdirichletallocation(lda用于构建主题模型)2.lda.components(输出各个词向量的权重值)(代码(代码
函数说明 1.LDA(n_topics,max_iters,random_state) 用于构建LDA主题模型,将文本分成不同的主题 参数说明:n_topics表示分为多少个主题,max_iters表示最大的迭代次数,random_state表示随机种子 2.LDA.components_打印输入特征的权重... 查看详情
机器学习&sklearn笔记:lda(线性判别分析)(代码片段)
1介绍1.有监督的降维2.投影后类内方差最小,类间方差最大 2推导我们记最佳的投影向量为w,那么一个样例x到方向向量w上的投影可以表示为:给定数据集令分别表示第i类的样本个数、样本集合、均值向量和协方差... 查看详情
gradio机器学习和数据科学开源python库(代码片段)
...io是一个开源的Python库,MIT的开源项目,用于构建机器学习和数据科学演示和Web应用。 Gradio的定位类似于Streamlit,但是更轻量,因为它推荐的应用场景都是对“单个函数”进行调用的应用,并且不... 查看详情
gradio机器学习和数据科学开源python库(代码片段)
...io是一个开源的Python库,MIT的开源项目,用于构建机器学习和数据科学演示和Web应用。 Gradio的定位类似于Streamlit,但是更轻量,因为它推荐的应用场景都是对“单个函数”进行调用的应用,并且不... 查看详情