关键词:
一. Selenium和PhantomJS介绍
Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样。由于这个性质,Selenium也是一个强大的网络数据采集工具,其可以让浏览器自动加载页面,这样,使用了异步加载技术的网页,也可获取其需要的数据。
Selenium模块是Python的第三方库,可以通过pip进行安装:
|
pip3 install selenium |
Selenium自己不带浏览器,需要配合第三方浏览器来使用。通过help命令查看Selenium的Webdriver功能,查看Webdriver支持的浏览器:
|
from selenium import webdriver help(webdriver) |
查看执行后的结果,如下图所示:
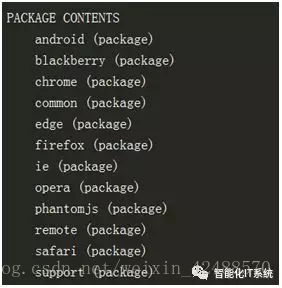
在这个案例中,采用PhantomJS。Selenium和PhantomJS的配合使用可以完全模拟用户在浏览器上的所有操作,包括输入框内容填写、单击、截屏、下滑等各种操作。这样,对于需要登录的网站,用户可以不需要通过构造表单或提交cookie信息来登录网站。
二. 案例介绍
这里所举的案例,是利用Selenium爬取淘宝商品信息,爬取的内容为淘宝网(https://www.taobao.com/)上男士短袖的商品信息,如下图所示:
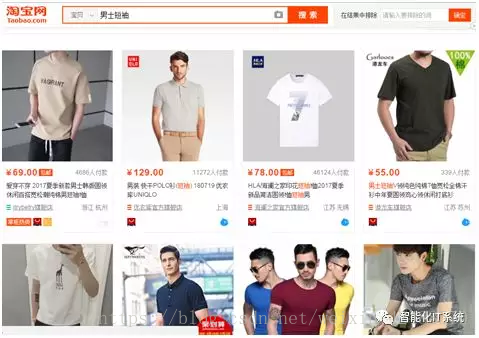
这里可以看到,在用户输入淘宝后,需要模拟输入,在输入框输入“男士短袖”。
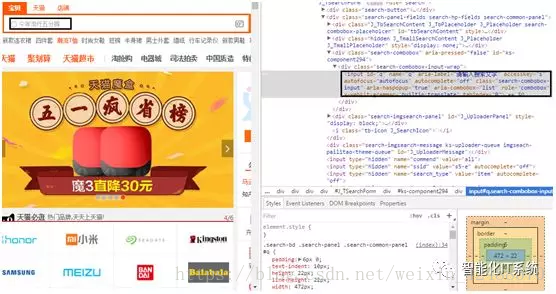
案例中使用Selenium和PhantomJS,模拟电脑的搜索操作,输入商品名称进行搜索,如图所示,“检查”搜索框元素。
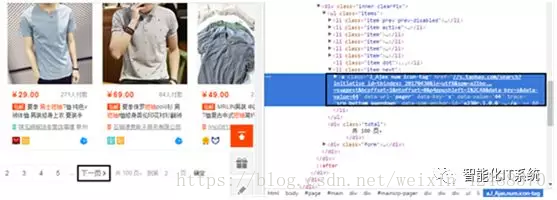
并且如下图所示,“检查”下一页元素:
爬取的内容有商品价格、付款人数、商品名称、商家名称和地址,如下图所示:
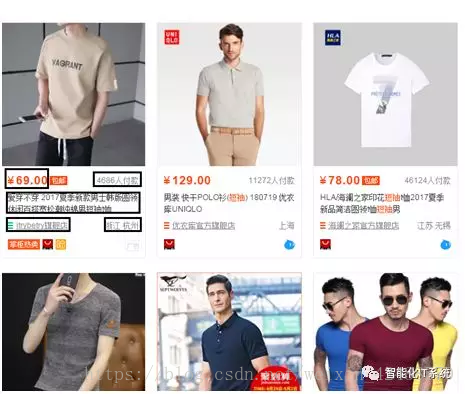
最后把爬取数据存储到MongoDB数据库中。
三. 相关技术
这里把除了selenium之外所需要的知识列一下,这里就不做详细解释了,如果不清楚的话可以百度了解下。
-
mongoDB的使用,以及在python中用mongodb进行数据存储。
-
lxml,爬虫三大方法之一,解析效率比较高,使用难度相比正则表达式要低(上一篇文章的解析方法是正则表达式)。
-
间歇休息的方法:driver.implicitly_wait
四. 源代码
代码如下所示,可复制直接执行:
from selenium import webdriver from lxml import etree import time import pymongo client = pymongo.MongoClient(‘localhost‘, 27017) mydb = client[‘mydb‘] taobao = mydb[‘taobao‘] driver = webdriver.PhantomJS() driver.maximize_window() def get_info(url,page): page = page + 1 driver.get(url) driver.implicitly_wait(10) selector = etree.HTML(driver.page_source) infos = selector.xpath(‘//div[@class="item J_MouserOnverReq"]‘) for info in infos: data = info.xpath(‘div/div/a‘)[0] goods = data.xpath(‘string(.)‘).strip() price = info.xpath(‘div/div/div/strong/text()‘)[0] sell = info.xpath(‘div/div/div[@class="deal-cnt"]/text()‘)[0] shop = info.xpath(‘div[2]/div[3]/div[1]/a/span[2]/text()‘)[0] address = info.xpath(‘div[2]/div[3]/div[2]/text()‘)[0] commodity = ‘good‘:goods, ‘price‘:price, ‘sell‘:sell, ‘shop‘:shop, ‘address‘:address taobao.insert_one(commodity) if page <= 50: NextPage(url,page) else: pass def NextPage(url,page): driver.get(url) driver.implicitly_wait(10) driver.find_element_by_xpath(‘//a[@trace="srp_bottom_pagedown"]‘).click() time.sleep(4) driver.get(driver.current_url) driver.implicitly_wait(10) get_info(driver.current_url,page) if __name__ == ‘__main__‘: page = 1 url = ‘https://www.taobao.com/‘ driver.get(url) driver.implicitly_wait(10) driver.find_element_by_id(‘q‘).clear() driver.find_element_by_id(‘q‘).send_keys(‘男士短袖‘) driver.find_element_by_class_name(‘btn-search‘).click() get_info(driver.current_url,page)
五. 代码解析
(1)1~4行
导入程序需要的库,selenium库用于模拟请求和交互。lxml解析数据。pymongo是mongoDB 的交互库。
(2)6~8行
打开mongoDB,进行存储准备。
(3)10~11行
最大化PhantomJS窗口。
(4)14~33行
利用lxml抓取网页数据,分别定位到所需要的信息,并把信息集成至json,存储至mongoDB。
(5)35~47行
分页处理。
(5)51~57行
利用selenium模拟输入“男士短袖”,并模拟点击操作,并获取到对应的页面信息,调取主方法解析。
———————————————————
公众号-智能化IT系统。每周都有技术文章推送,包括原创技术干货,以及技术工作的心得分享。扫描下方关注。

python--使用selenium模拟登录淘宝,爬取商品信息(代码片段)
目录环境谷歌驱动下载解析结果代码环境windows10python3.7.3selenium谷歌谷歌驱动谷歌驱动下载http://chromedriver.storage.googleapis.com/index.html下载与自己电脑谷歌浏览器版本相应的谷歌驱动解析在这里主要爬去商品的基本信息:结果代... 查看详情
使用selenium模拟浏览器抓取淘宝商品美食信息(代码片段)
1.搜索关键词:利用Selenium驱动浏览器,得到商品列表。2.分析页码并翻页:得到商品页码数,模拟翻页,得到后续页面的商品列表。3.分析提取商品内容:利用PyQuery分析源码,解析得到商品列表。4.存储到MongoDB:将商品列表信息... 查看详情
scrapy+selenium 爬取淘宝商城商品数据存入到mongo中(代码片段)
...机‘,‘华为手机‘]#最大爬取页数MAX_PAGE=2#相应超时设置SELENIUM_TIMEOUT=20ROBOTSTXT_OBEY=False #忽略#中间件DOWNLOADER_MIDDLEWARES=‘taobaoSpider.midd 查看详情
淘宝商品定向爬取(代码片段)
淘宝商品比价定向爬虫功能描述:1、目标:获取淘宝搜索页面的信息,提取其中的商品名称和价格2、理解:淘宝的搜索接口,翻页处理 技术路线:requests+re程序的结构设计:1、提交商品搜索的请求,循环获取页面。2、对于... 查看详情
淘宝商品数据爬取并分析数据(代码片段)
...ord”查找商品2、再解决登录问题(登录时解决网站对selenium的判别,修改浏览器的内部属性,否则被识别出有selenium,需要进行滑动登陆验证。但是在运行时,你手动地去进行滑动登录也是会判别出存在selenium... 查看详情
使用selenium抓取淘宝的商品信息
淘宝的页面大量使用了js加载数据,所以采用selenium来进行爬取更为简单,selenum作为一个测试工具,主要配合无窗口浏览器phantomjs来使用。importrefromseleniumimportwebdriverfromselenium.common.exceptionsimportTimeoutExceptionfromselenium.webdriver.co... 查看详情
爬虫实战--使用selenium模拟浏览器抓取淘宝商品美食信息(代码片段)
fromseleniumimportwebdriverfromselenium.webdriver.common.byimportByfromselenium.common.exceptionsimportTimeoutExceptionfromselenium.webdriver.support.uiimportWebDriverWaitfromselenium.webdriver.suppor 查看详情
利用python自动搜索指定京东商品并爬取商品信息(代码片段)
文章目录前言一、准备工作1.安装相关Python库2. 安装Chrome和ChromeDriver 二、代码说明1.模块引入2.网页分析三、代码四、输出示例前言环境:Ubuntu20.04、Python3.8.10、Spyder4.2.0目标:通过Python自动打开浏览器,搜索指定搜... 查看详情
使用selenium爬取淘宝(代码片段)
使用selenium爬取淘宝一、出现的问题 前段时间在使用selenium对淘宝进行模拟登陆的时候,输入完正好和密码,然后验证码无论如何都不能划过去。找了好久,原来是因为selenium在浏览器中运 ... 查看详情
scrapy+selenium爬取淘宝(代码片段)
#-*-coding:utf-8-*-importscrapyfromscrapyimportRequestfromurllib.parseimportquotefrom..itemsimportScrapyseleniumtestItemclassTaobaoSpider(scrapy.Spider):name=‘tao_bao‘allowed_domains=[‘www.taobao.com‘ 查看详情
爬虫实例之selenium爬取淘宝美食
这次的实例是使用selenium爬取淘宝美食关键字下的商品信息,然后存储到MongoDB。 首先我们需要声明一个browser用来操作,我的是chrome。这里的wait是在后面的判断元素是否出现时使用,第二个参数为等待最长时间,超过该值则... 查看详情
利用selenium爬取淘宝美食内容
1、启动pycharm首先咱们新建一个项目名字大家可以自己设定接着新建一个spider.p文件#author:"xian"#date:2018/5/4importre#导入re库fromseleniumimportwebdriver#导入selenium库fromselenium.common.exceptionsimportTimeoutException#导入超时异常处理模块fromselen 查看详情
爬虫系列之淘宝商品爬取(代码片段)
1importre2importrequests34defgetHTMLText(url):5try:6r=requests.get(url,timeout=30)7r.raise_for_status()8r.encoding=r.apparent_encoding9returnr.text10except:11return""121314defparsePage(ilt,html):15try 查看详情
selenium抓取淘宝商品(代码片段)
...需要耗费大量时间才能找出规律,这时候,我们就可以用selenium,它可以直接模仿浏览器运行,并且抓取在运行时的源码,不用管ajax那些复杂的数,此次我们使用一种无界面的浏览器Phant 查看详情
用selenium爬取淘宝美食
‘‘‘利用selenium爬取淘宝美食网页内容‘‘‘importrefromseleniumimportwebdriverfromselenium.common.exceptionsimportTimeoutExceptionfromselenium.webdriver.common.byimportByfromselenium.webdriver.support.uiimportWebDrive 查看详情
scrapy实战---scrapy对接selenium爬取京东商城商品数据(代码片段)
...:我们以爬取京东商城商品数据为例,展示Scrapy框架对接selenium爬取京东商城商品数据。 背景: 京东商城页面为js动态加载页面,直接使用request请求,无法得到我们想要的商品数据,故需要借助于selenium模拟人的行为发... 查看详情
03selenium实战爬取京东商品(代码片段)
Selenium和Requests都是Python中常用的网络请求库,但是Selenium获取数据的方式与Requests有些差别,Selenium可以直接模拟浏览器操作,获取数据更加方便,但是相应的速度也会慢一些。下面是使用selenium获取京东商品数据的示例代码:首... 查看详情
用python爬取某宝热卖网站商品信息(爬虫之路,永无止境!)(代码片段)
...#xff1a;windows10python3.6开发工具:pycharmchromedriver库:selenium、os、csv代码全解安装插件首先要安装webdriver插件,本文以谷歌浏览器为例 查看详情