关键词:
简介
读万卷书不如行万里路,讲了这么多assembly和JVM的原理与优化,今天我们来点不一样的实战。探索一下怎么使用assembly来理解我们之前不能理解的问题。
一个奇怪的现象
小师妹:F师兄,之前你讲了那么多JVM中JIT在编译中的性能优化,讲真的,在工作中我们真的需要知道这些东西吗?知道这些东西对我们的工作有什么好处吗?
um...这个问题问得好,知道了JIT的编译原理和优化方向,我们的确可以在写代码的时候稍微注意一下,写出性能更加优秀的代码,但是这只是微观上了。
如果将代码上升到企业级应用,一个硬件的提升,一个缓存的加入或者一种架构的改变都可能比小小的代码优化要有用得多。
就像是,如果我们的项目遇到了性能问题,我们第一反应是去找架构上面有没有什么缺陷,有没有什么优化点,很少或者说基本上不会去深入到代码层面,看你的这个代码到底有没有可优化空间。
第一,只要代码的业务逻辑不差,运行起来速度也不会太慢。
第二,代码的优化带来的收益实在太小了,而工作量又非常庞大。
所以说,对于这种类似于鸡肋的优化,真的有必要存在吗?
其实这和我学习物理化学数学知识是一样的,你学了那么多知识,其实在日常生活中真的用不到。但是为什么要学习呢?
我觉得有两个原因,第一是让你对这个世界有更加本质的认识,知道这个世界是怎么运行的。第二是锻炼自己的思维习惯,学会解决问题的方法。
就想算法,现在写个程序真的需要用到算法吗?不见得,但是算法真的很重要,因为它可以影响你的思维习惯。
所以,了解JVM的原理,甚至是Assembly的使用,并不是要你用他们来让你的代码优化的如何好,而是让你知道,哦,原来代码是这样工作的。在未来的某一个,或许我就可能用到。
好了,言归正传。今天给小师妹介绍一个很奇怪的例子:
private static int[] array = new int[64 * 1024 * 1024];
@Benchmark
public void test1()
int length = array.length;
for (int i = 0; i < length; i=i+1)
array[i] ++;
@Benchmark
public void test2()
int length = array.length;
for (int i = 0; i < length; i=i+2)
array[i] ++;
小师妹,上面的例子,你觉得哪一个运行的更快呢?
小师妹:当然是第二个啦,第二个每次加2,遍历的次数更少,肯定执行得更快。
好,我们先持保留意见。
第二个例子,上面我们是分别+1和+2,如果后面再继续+3,+4,一直加到128,你觉得运行时间是怎么样的呢?
小师妹:肯定是线性减少的。
好,两个问题问完了,接下来让我们来揭晓答案吧。
两个问题的答案
我们再次使用JMH来测试我们的代码。代码很长,这里就不列出来了,有兴趣的朋友可以到本文下面的代码链接下载运行代码。
我们直接上运行结果:
Benchmark Mode Cnt Score Error Units
CachelineUsage.test1 avgt 5 27.499 ± 4.538 ms/op
CachelineUsage.test2 avgt 5 31.062 ± 1.697 ms/op
CachelineUsage.test3 avgt 5 27.187 ± 1.530 ms/op
CachelineUsage.test4 avgt 5 25.719 ± 1.051 ms/op
CachelineUsage.test8 avgt 5 25.945 ± 1.053 ms/op
CachelineUsage.test16 avgt 5 28.804 ± 0.772 ms/op
CachelineUsage.test32 avgt 5 21.191 ± 6.582 ms/op
CachelineUsage.test64 avgt 5 13.554 ± 1.981 ms/op
CachelineUsage.test128 avgt 5 7.813 ± 0.302 ms/op
好吧,不够直观,我们用一个图表来表示:
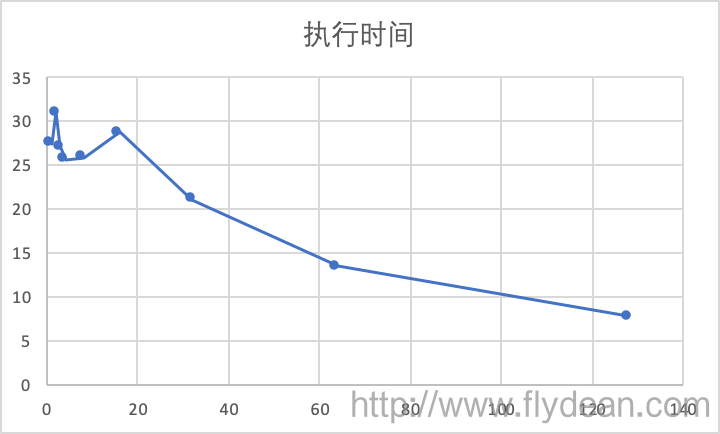
从图表可以看出,步长在1到16之间的时候,执行速度都还相对比较平稳,在25左右,然后就随着步长的增长而下降。
CPU cache line
那么我们先回答第二个问题的答案,执行时间是先平稳再下降的。
为什么会在16步长之内很平稳呢?
CPU的处理速度是有限的,为了提升CPU的处理速度,现代CPU都有一个叫做CPU缓存的东西。
而这个CPU缓存又可以分为L1缓存,L2缓存甚至L3缓存。
其中L1缓存是每个CPU核单独享有的。在L1缓存中,又有一个叫做Cache line的东西。为了提升处理速度,CPU每次处理都是读取一个Cache line大小的数据。
怎么查看这个Cache line的大小呢?
在mac上,我们可以执行:sysctl machdep.cpu
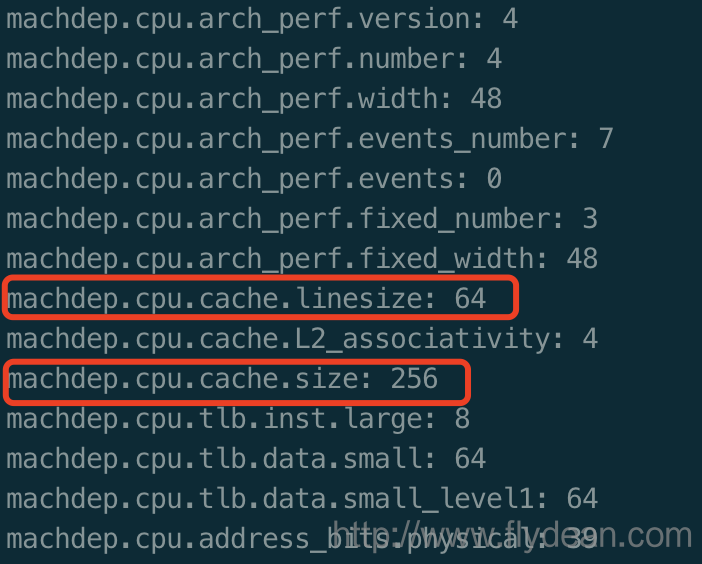
从图中我们可以得到,机子的CPU cache line是64byte,而cpu的一级缓存大小是256byte。
好了,现在回到为什么1-16步长执行速度差不多的问题。
我们知道一个int占用4bytes,那么16个int刚好占用64bytes。所以我们可以粗略的认为,1-16步长,每次CPU取出来的数据是一样的,都是一个cache line。所以,他们的执行速度其实是差不多的。
inc 和 add
小师妹:F师兄,上面的解释虽然有点完美了,但是好像还有一个漏洞。既然1-16使用的是同一个cache line,那么他们的执行时间,应该是逐步下降才对,为什么2比1执行时间还要长呢?
这真的是一个好问题,光看代码和cache line好像都解释不了,那么我们就从Assembly的角度再来看看。
还是使用JMH,打开PrintAssembly选项,我们看看输出结果。
先看下test1方法的输出:

再看下test2方法的输出:

两个有什么区别呢?
基本上的结构都是一样的,只不过test1使用的是inc,而test2方法使用的add。
本人对汇编语言不太熟,不过我猜两者执行时间的差异在于inc和add的差异,add可能会执行慢一点,因为它多了一个额外的参数。
总结
Assembly虽然没太大用处,但是在解释某些神秘现象的时候,还是挺好用的。
本文的例子https://github.com/ddean2009/learn-java-base-9-to-20
本文作者:flydean程序那些事
本文链接:http://www.flydean.com/jvm-jit-cacheline/
本文来源:flydean的博客
欢迎关注我的公众号:程序那些事,更多精彩等着您!
小师妹学jvm之:逃逸分析和tlab(代码片段)
...多线程的环境中,如何提升内存的分配效率呢?快来跟小师妹一起学习TLAB技术吧。逃逸分析和栈上分配小师妹:F师兄,从前大家都说对象是在堆中分配的,然后我就 查看详情
小师妹学jvm之:jvm的架构和执行过程(代码片段)
...个不同操作系统中运行的机器代码并运行。今天我们和小师妹一起走进java的核心JVM,领略java在设计上的哲学。JVM是一种标准小师妹:F师兄,经常听到有人说hotspotVM,这 查看详情
小师妹学jvm之:jit中的printcompilation(代码片段)
...释了LogCompilation日志文件中的内容定义。今天我们再和小师妹一起学习LogCompilation的姊妹篇PrintCompilation,看看都有什么妙用吧。PrintCompilati 查看详情
小师妹学javaio之:文件读取那些事
...读取的方式按字节读取的方式寻找出错的行数总结简介小师妹最新对javaIO中的reader和stream产生了一点点困惑,不知道到底该用哪一个才对,怎么读取文件才是正确的姿势呢?今天F师兄现场为她解答。字符和字节小师妹最近很迷... 查看详情
小师妹学javaio之:trywith和它的底层原理
...用trywithresourcetrywithresource的原理自定义resource总结简介小师妹是个java初学者,最近正在学习使用javaIO,作为大师兄的我自然要给她最给力的支持了。一起来看看她都遇到了什么问题和问题是怎么被解决的吧。IO关闭的问题这一天... 查看详情
小师妹学javaio之:trywith和它的底层原理
...用trywithresourcetrywithresource的原理自定义resource总结简介小师妹是个java初学者,最近正在学习使用javaIO,作为大师兄的我自然要给她最给力的支持了。一起来看看她都遇到了什么问题和问题是怎么被解决的吧。IO关闭的问题这一天... 查看详情
小师妹学javaio之:文件编码和字符集unicode
...件编码解决Properties中的乱码真.终极解决办法总结简介小师妹一时兴起,使用了一项从来都没用过的新技能,没想却出现了一个无法解决的问题。把大象装进冰箱到底有几步?乱码的问题又是怎么解决的?快来跟F师兄一起看看吧... 查看详情
小师妹学javaio之:文件编码和字符集unicode
...件编码解决Properties中的乱码真.终极解决办法总结简介小师妹一时兴起,使用了一项从来都没用过的新技能,没想却出现了一个无法解决的问题。把大象装进冰箱到底有几步?乱码的问题又是怎么解决的?快来跟F师兄一起看看吧... 查看详情
jvm系列之性能调优参考手册(实践篇)(代码片段)
JVM系列之性能调优参考手册(实践篇)系列博客专栏:JVM系列博客专栏SpringBoot系列博客1、前言介绍在前面章节的学习,我们对JVM的体系架构等等有了比较详细的了解,所以可以对这些理论进行实践,当然... 查看详情
零元学expressiondesign4-chapter7使用内建功能「clone」来达成path的影分身之术
...元学ExpressionDesign4-Chapter7使用内建功能「Clone」来达成Path的影分身之术本章所介绍的是便利且快速的内建工具Clone?本章所介绍的是便利且快速的内建工具Clone??为什麽会说像是影分身之术呢??请参照火影忍者(NARUTO):《分身术》会... 查看详情
jvm中栈的frames详解
...的栈到底是怎么工作的呢?快来一起看看吧。JVM中的栈小师妹:F师兄,JVM为每个线程的运行都分配了一个栈,这个栈到底是怎么工作的呢?小师妹,我们先看 查看详情
性能测试之jvm异常说明和分析工具(代码片段)
StackOverflowError和OutOfMemoryError是JVM里的两种Error。每个运行时区域——程序计数器、Java虚拟机栈、本地方法栈、Java堆、方法区、直接内存发生Error的原因和错误信息是不同的。不是所有的StackOverflowError和OutOfMemoryError都需要调整参... 查看详情
jvm优化之调整大内存分页(largepage)
...理,如何调整分页大小两节内容,向你阐述LargePage对JVM的性能有何提升作用,并在文末点明了大内分页的副作用。OK,让我们开始吧!内存分页大小对性能的提升原理首先,我们需要回顾一小部分计算机组成原理,这对理解大内... 查看详情
我给师妹说算法_2插入排序(代码片段)
每次看师妹对着屏幕的算法题憋得满脸通红,总觉得非常可爱,大有小拳拳锤算法胸口的意思,虽然说看师妹真的很疗愈,念在她请我喝的那么多杯喜茶的份上,我打算给师妹写点东西。每篇文章先从实际问... 查看详情
jvm性能调优工具之jstat命令详解
...in目录下,主要利用JVM内建的指令对Java应用程序的资源和性能进行实时的命令行的监控,包括了对Heapsize和垃圾回收状况的监控。命令用法:jstat[-命令选项][vmid][间隔时间/毫秒][查询次数] 注意:使用的jdk版本是jdk8。C: ... 查看详情
性能优化之基础资源cpu&内存(jvm)
...源的一些原理,介绍如何查看资源的数量,使用情况,对性能和整体计算机执行的一些影响。本章很多内容都基于linux,不是特殊说明,就是针对linux的情况。可能在其它操作系统不一定适用。另外还会对jvm之上的一些内容做特... 查看详情
jvm性能优化对象内存分配之虚拟机参数调优分析(代码片段)
内容简介本文主要针对于综合层面上进行分析JVM优化方案总结和列举调优参数计划。主要包含:调优之逃逸分析(栈上分配)调优之线程局部缓存(TLAB)调优之G1回收器栈上分配与逃逸分析-XX:+DoEscapeAnalysis... 查看详情
jvm性能调优实战之:一次系统性能瓶颈的寻找过程
...。性能优化分为好几个层次,比如系统层次、算法层次、代码层次...JVM的性能优化被认为是底层优化,门槛较高,精通这种技能的人比较少。笔者呆过几家技术力量不算弱的公司,每个公司内部真正能够进行JVM性能调优的人寥寥... 查看详情