关键词:
1.什么是神经网络
人脑是一个高度复杂的、非线性的和并行的计算机器(信息处理系统)。人脑能够组织他的组成成分,即神经元,以比今天已有的最快的计算机还要快许多倍的速度进行特定的计算(如模式识别、感知和发动机控制)。具体来说,完成一个感知识别任务(例如识别一张被嵌入陌生场景的熟悉的脸)人脑大概需要100~200毫秒,而一台高效的计算机却要花费比人脑多很多的时间才能完成一个相对简单的任务。
一个“进化中”的神经系统是与可塑的大脑同义的。可塑性允许进化中的神经系统适应(adapt)其周边环境。可塑性似乎是人类大脑中作为信息处理单元的神经元功能的关键,同样,它在人工神经元组成的神经网络中亦是如此。最普通形式的神经网络,就是对人脑完成特定任务或感兴趣功能所采用的方法进行建模的机器。
为了获得良好性能,神经网络使用一个很庞大的简单计算单元间的相互连接,这些简单计算单元称为“神经元”或者“处理单元”。据此我们给出将神经网络看作一种自适应机器的定义:
神经网络是由简单处理单元构成的大规模并行分布式处理器,天然地具有存储经验知识和使之可用的特性。神经网络在两个方面与大脑相似:
1.神经网络是通过学习过程从外界环境中获取知识的
2.互连神经元的连接强度,即突触权值,用于存储获取的知识
用于完成学习过程的程序称为学习算法,其功能是以有序的方式改变网络的突触权值以获得想要的设计目标。
神经网络的优点
神经网络的计算能力可通过以下两点得到体现:第一,神经网络的大规模并行分布式结构;第二,神经网络的学习能力以及由此而来的泛化能力。泛化是指神经网络对未在训练(学习)过程中遇到的数据可以得到合理的输出。这两种信息处理能力让神经网络可以找到一些当前难以处理的复杂(大规模)问题的好的近似解。
神经网络具有下列有用的性质和能力:
1.非线性
2.输入输出映射:称之为有教师学习或监督学习
3.自适应性:神经网络具有调整自身突触权值以适应外界环境变化的固有能力。特别是,一个在特定运行环境下接受训练的神经网络,在环境条件不大的时候可以很容易地进行重新训练。而且,当它在一个不稳定环境(即它的统计特性随时间变化)中运行时,可以设计神经网络使得其突触权值随时间实时变化。但是,需要强调的是,自适应性不一定总能导致鲁棒性,实际还可能导致相反结果。
4.证据响应:在模式分类问题中,神经网络可以设计成不仅提供选择哪一个特定模式的信息,还提供关于决策的置信度信息。后者可以用来拒判那些可能出现的过于模糊的模式,从而进一步改善网络的分类性能。
5.上下文信息:神经网络的特定结构和激发状态代表知识。网络中每一个神经元都受网络中其他神经元全局活动的潜在影响。因此,神经网络将很自然地能够处理上下文信息
6.容错性:一个以硬件形式实现地神经网络具有天生的容错性,或者说具有鲁棒计算的能力,在这种意义上其性能在不利的运行条件下是逐渐下降的。
7.VLSI:神经网络的大规模并行性使它具有快速处理某些任务的潜在能力。这一特性使得神经网络很适合使用超大规模集成(very-large-scale-integrated,VLSI)技术来实现。
8.神经生物类比
2.神经元模型
我们在这里给出神经元模型的三种基本元素:
1.突触或连接链集
2.加法器
3.激活函数
激活函数类型
1.阈值函数

2.sigmoid函数
此函数的图像是S型,在构造人工神经网络中是最常用的激活函数。

神经元的统计模型
在一些神经网络的应用中,基于随机神经模型的分析更符合需要。使用一些解析处理方法,McCullochPitts模型的激活函数用概率分布来实现。具体来说,一个神经元允许有两个可能的状态值+1或-1.一个神经元激发(即它的状态开关从关到开)是随机决定的。用x表示神经元的状态,P(v)表示激发的概率,其中v是诱导局部域。我们可以设定
x=+1 概率为P(v)
x=-1概率为1-P(v)
一个标准选择是sigmoid型的函数:
P(v)=1/(exp(-v/T))
其中T是伪温度,用来控制激发中的噪声水平即不确定性。这里T不是物理温度,而将T看作是一个控制表示突触噪声效果的热波动参数。注意当T趋于0时,上面两个形式所描述的随机神经元就变为无噪声(即确定性形式),也就是MP模型。
3.被看作有向图的神经网络
信号流图是一个由在一些特定的称为节点的点之间相连的有向连接(分支)组成的网络。图像中各部分的信号流动遵循三条基本规则:
规则1 信号仅仅沿着定义好的箭头方向在连接上流动
两种不同类型的连接可以区别开来:
1. 突触连接,它的行为由线性输入输出关系决定。节点信号yk由节点信号xj乘以突触权值wkj产生
2.激活连接,它的行为一般由非线性输入输出关系决定。
规则2 节点信号等于经由连接进入的有关节点的所有信号的代数和
规则3 节点信号沿每个外向连接向外传递,此时传递的信号完全独立于外向连接的传递函数。
神经网络是由具有互相连接的突触节点和激活连接构成的有向图,具有4个主要特征:
1.每个神经元可表示为一组线性的突触连接,一个外部应用偏置,以及可能的非线性激活连接。偏置由和一个固定为+1的输入连接的突触连接表示。
2.神经元的突触连接给它们相应的输入信号加权。
3.输入信号的加权和构成该神经元的诱导局部域
4.激活连接压制神经元的诱导局部域产生输出
4.反馈
当系统中一个元素的输出能够部分地影响作用于该元素的输入,从而造成一个或多个围绕该系统进行信号传输的封闭路径时,我们说动态系统中存在着反馈。实际上,反馈存在于所有动物神经系统的几乎每一部分中。

图12表示单环反馈系统的信号流图,输入信号xj(n)、内部信号x′j(n)和输出信号yk(n)是离散时间变量n的函数。这个系统被假定为线性的,由“算子”A表示的前向通道和“算子”B表示的反馈通道组成。特别地,前向通道的输出通过反馈通道来部分地影响自己的输出。由图12可以很容易得到这样的输入输出关系:

其中方括号是为了强调A和B是扮演着算子的角色。在式(16)和式(17)中消去x′j(n),得到

我们把A/(1-AB)称为系统的闭环算子,AB称为开环算子。通常,开环算子没有交换性,即BA≠AB。
例如,考虑图13a中的单环反馈系统。A是一个固定的权值w,B是单位时间延迟算子z-1,其输出是输入延迟一个时间单位的结果。我们可以将这个系统的闭环算子表示为

将![]() 二项式展开,可以把系统的闭环算子重写为
二项式展开,可以把系统的闭环算子重写为

因此,将式(19)代入式(18),我们有
![]()
其中,再次用方括号强调![]() 是算子的事实。特别地,由
是算子的事实。特别地,由![]() 的定义我们有
的定义我们有
![]()
其中xj(n-l)是输入信号延迟l个时间单位的样本。因此,可以用输入xj(n)现在和过去所有样本的无限加权和来表示输出yk(n):


图13 a)一阶无限冲击响应(IIR)滤波器的信号流图;b)图中a)部分的前馈近似,通过切断式(20)得到
我们现在清楚地看到由图13的信号流图表示的反馈系统的动态行为是由权值w控制的。特别是,我们可以识别两种特殊情况:
1.w<1,此时输出信号yk(n)以指数收敛;也就是说,系统是稳定的。如图14a对一个正w值的情况所示。
2.w≥1,此时输出信号yk(n)发散;也就是说,系统是不稳定的。图14b是w=1的情况,发散是线性的;图14c是w>1的情况,发散是指数的。
稳定性是闭环反馈系统研究中的突出特征。
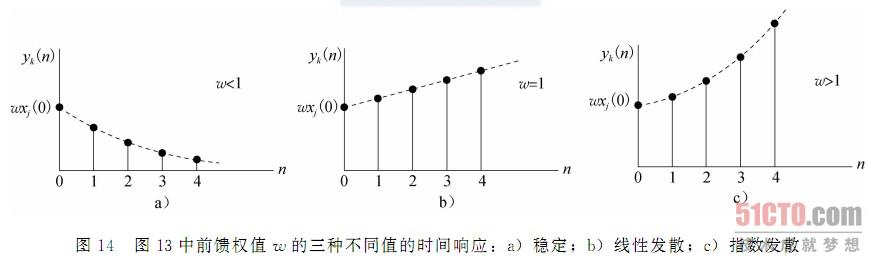
w<1的情况对应于具有无限记忆的系统,这是指系统的输出依赖于无限过去的输入样本。并且,过去的样本对记忆的影响是随时间n呈指数衰减的。假设对任意的幂N,w相对于数1足够小以保证对任何实际目的来说wN是可以忽略的。在这种情况下,可以通过下面的有限和来逼近输出yk:
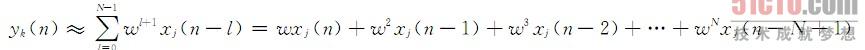
相应地,可以利用图13b所示的前馈信号流图作为图13a的反馈信号流图的逼近。在实现这样的逼近的时候,我们称为反馈系统的“伸展”。然而,必须说明的是,仅在反馈系统稳定的时候伸展操作才有实际价值。
由于用于构造神经网络的处理单元通常是非线性的,因此它所涉及的反馈应用的动态行为分析都很复杂。这一点在本书后面会给出进一步分析。
5.网络结构
一般来说,我们可以区分三种基本不同的网络结构:
1.单层前馈网络
2.多层前馈网络
3.递归网络
递归网络和前馈网络的区别在于它至少有一个反馈环。递归网络可以由单层神经元组成,单层网络的每一个神经元的输出都反馈到所有其他神经元的输入中。这个图中描绘的结构没有自反馈环;自反馈环表示神经元的输出反馈到它自己的输入上。
6.知识表示
知识就是人或机器存储起来以备使用的信息或模型,用来对外部世界做出解释、预测和适当的反应。
知识表示的主要特征有两个方面:(1)什么信息是明确表述的(2)物理上信息是如何被编码和使用的
神经网络的一个主要任务是学习它所依存的外部世界(环境)模型,并且保持该模型和真实世界足够兼容,使之能够实现感兴趣应用的特定目标。有关世界的知识由两类信息组成。
1.已知世界的状态,这种形式的知识称为先验信息
2.对世界的观察(测量),由神经网络中被设计用于探测环境的传感器获得。
知识表示的规则
然而,在人工网络中知识的表示是非常复杂的。这里有关于知识表示的通用的4条规则
规则1 相似类别中的相似输入通常应产生网络中相似的表示,因此,可以归入同一类中
规则2 网络对可分离为不同种类的输入向量给出差别很大的表示
规则3 如果某个特征很重要,那么网络表示这个向量将涉及大量神经元。
规则4 如果存在先验信息和不变性,应该将其附加在网络设计中,这样就不必学习这些信息而简化网络设计。
怎样在神经网络设计中加入先验信息
当然,怎样在神经网络设计中建立先验信息,以此建立一种特定的网络结构,是必须考虑的重要问题。遗憾的是,现在还没有一种有效的规则来实现这一目的;目前我们更多的是通过某些特别的过程来实现,并已知可以产生一些有用的结果。特别是我们使用下面两种技术的结合:
1.通过使用称为接收域(receptive field)的局部连接,限制网络结构
2.通过使用权值共享,限制突触权值的选择
这两种方法,特别是后一种,有很好的附带效益,它能使网络自由参数的数量显著下降。
如何在网络设计中建立不变性
考虑下列物理现象:
1.当感兴趣的目标旋转时,观察者感知到的目标图像通常会产生相应的变化
2.当一个提供它周围环境的幅度和相位信息的相干雷达中,由于目标相对于雷达射线运动造成的多普勒效应,活动目标的回声在频率上会产生偏移
3.人说话的语调会有高低快慢的变化
为了分别建立一个对象识别系统、一个雷达目标识别系统和一个语音识别系统来处理这些现象,系统必须可以应付一定范围内观察信号的变换。相应地,一个模式识别问题地主要任务就是设计对这些变换不变的分类器。也就是说,分类器输出的类别估计不受分类器输入观察信号变换的影响。
至少可用三种技术使得分类器类型的神经网络对变换不变
1.结构不变性
2.训练不变性
3.不变特征空间
7.学习过程
广义上讲,我们可以通过神经网络的功能来对其学习过程进行如下分类:有教师学习和无教师学习。按照同样的标准,后者又可以分为无监督学习和强化学习两个子类。
8.学习任务
1.模式联想
联想记忆是与大脑相似的依靠联想学习的分布式记忆。联想就被看作是人类记忆的一个显著特征,并且认知的所有模型都以各种形式使用联想作为其基本行为。
联想有一种或两种形式:自联想与异联想。在自联想方式中,神经网络被要求通过不断出示一系列模式(向量),给出网络而存储这些模式。其后将某已存模式的部分描述或畸变(噪声)形式出示给网络,而网络的任务就是检索(回忆)出已存储的该模式。异联想与自联想的不同之处在于一个任意的输入模式集合与另一个输出模式集合配对。自联想需要使用无监督学习方式,而异联想采用监督学习方式。
2.模式识别
3.函数逼近
神经网络逼近一个未知输入-输出映射的能力可以从两个重要途径加以利用:
1)系统辨别
2)逆模型
4.控制
5.波束形成
学习《神经网络与机器学习(第3版)》高清英文pdf+中文pdf
神经网络是计算智能和机器学习的重要分支,在诸多领域都取得了很大的成功。在众多神经网络著作中,影响最为广泛的是SimonHaykin的《神经网络原理》(第3版更名为《神经网络与机器学习》)。结合近年来神经网络和机器学习... 查看详情
机器学习--神经网络
...得,没有很深的东西,觉得可以简单的了解一下机器学习与神经网络是什么机器学习所谓机器学习,就是在大量数据的运行下,使得计算机可以进行归纳,预测 机器学习分为三类:监督学习,无监督学习,强化学习 &nbs... 查看详情
14深度学习-卷积
...:是一种实现机器学习的技术,适合处理大数据2.全连接神经网络与卷积神经网络的联系与区别。联系: 全连接神经网络与卷积神经网络都是通过一层 查看详情
机器学习12卷积神经网络(代码片段)
...法,深度学习是一种实现机器学习的技术。 2.全连接神经网络与卷积神经网络的联系与区别。 卷积神经网络也是通过一层一层的节点组织起来的。和全连接神经网络一样,卷积神经网络中的每一个节点就是一个神经元。... 查看详情
分享《神经网络与机器学习(第3版)》+pdf+simonhaykin+申富饶
...Sr1a2pT-r2DCB2v2XcLHQ更多资料分享:http://blog.51cto.com/14087171《神经网络与机器学习(第3版)》高清英文PDF+中文PDF经典的《神经网络与机器学习(第3版)》书籍,讲解详细易懂。中文和英文两版对比学习,带目录书签。中文版如图: 查看详情
神经网络与深度学习——《机器学习及应用》汪荣贵机械工业出版社
...机器学习及应用》汪荣贵 机械工业出版社总结了一些神经网络与深度学习中的一些网络介绍。1.神经元与感知机(1)关于激活函数 (2)MLPMLP模型的网络结构没有环路或回路,故是一类前馈网络模型。MLP模型中隐含层的... 查看详情
14深度学习-卷积(代码片段)
...一种实现机器学习的技术和学习方法。 2. 全连接神经网络与卷积神经网络的联系与区别。解析:卷积神经网络也是通过一层一层的节点组织起来的。和全连接神经网络一样,卷积神经网络中的每一个节 查看详情
人工智能与机器学习
...业链下的一种方法,一种算法,深度学习则是机器学习的神经网络算法的一种延伸,拓展。(2)什么是机器学习? 给机器提出一个你想要完成的任务,并提供给他大量的学习数据,通过这些数据让他学会如何完成这个任务... 查看详情
机器学习(machinelearning)与深度学习(deeplearning)资料汇总
...机器学习历史的文章,介绍很全面,从感知机、神经网络、决策树、SVM、Adaboost到随机森林、DeepLearning.《DeepLearninginNeuralNetworks:AnOverview》介绍:这是瑞士人工智能实验室JurgenSchmidhuber写的最新版本《神经网络与深 查看详情
神经网络与机器学习
什么是神经网络?人工神经网络(ArtificialNeuralNetworks,简写为ANNs)也简称为神经网络(NNs)或称作连接模型(ConnectionModel),通俗来讲,神经网络是在模仿动物神经网络而构成的算法数学模型。它由三部分组成:输入层、隐藏... 查看详情
13.深度学习-卷积
...众多应用,并拓展了人工智能的领域范畴。 2.全连接神经网络与卷积神经网络的联系与区别。联系 查看详情
14深度学习-卷积(代码片段)
...实现机器学习的技术;它适合处理大数据。 2.全连接神经网络与卷积神经网络的联系与区别。联系: 全连接神经网络与卷积神经网络都是通过一层一层的节点组织起来的,和全连接神经网 查看详情
机器学习术语表
FFNN FeedForwardNeuralNetwork 前馈神经网络,神经网络中一般输入向前传递BP Backpropagation 反向传播,一般专指误差反向传播算法,RBM RestrictedBoltzmannMachine 限制波兹曼机 受限波兹曼机监督学习 给出data与lab... 查看详情
14深度学习-卷积
...他们的关系不是互相独立,而是一环套着一环。2.全连接神经网络与卷积神经网络的联系与区别。答:卷积神经网络的输入输出以及训练的流程和全连接神经网络也基本一致。全连接神经网络和卷积神经网络的唯一区别 查看详情
hulu机器学习问题与解答系列|第九弹:循环神经网络
...自己知(shou)道(nue) ~ 今天的内容是【循环神经网络】 场景描述循环神经网络(RecurrentNeuralNetwork)是一种主流的深度学习模型,最早在20世纪80年代被提出,目的是建模序列化的数据。我们知道,传统的前馈神... 查看详情
14深度学习-卷积(代码片段)
...实现众多应用,并拓展了人工智能的领域范畴。2.全连接神经网络与卷积神经网络的联系与区别。联系:(1)全 查看详情
2.深度学习与神经网络基础
1.人工智能、机器学习和深度学习的概念及关系人工智能(ArtificialIntelligence,AI)——为机器赋予人的智能,即计算机能够像人类一样完成更智能的工作。机器学习是实现人工智能的一种手段。何为“学习”?“如果一个程序可... 查看详情
《深度卷积神经网络原理与实践》笔记第一章机器学习基础
本笔记是依据周浦城等教授编著的《深度卷积神经网络原理与实践》的个人笔记(Version:1.0.2)整理作者:sq_csl第一章机器学习基础1.1机器学习概述1.1.1概念概念ML(MachineLearning)是一门发展了比较长时间... 查看详情