关键词:
推荐算法在互联网行业的应用非常广泛,今日头条、美团点评等都有个性化推荐,推荐算法抽象来讲,是一种对于内容满意度的拟合函数,涉及到用户特征和内容特征,作为模型训练所需维度的两大来源,而点击率,页面停留时间,评论或下单等都可以作为一个量化的 Y 值,这样就可以进行特征工程,构建出一个数据集,然后选择一个合适的监督学习算法进行训练,得到模型后,为客户推荐偏好的内容,如头条的话,就是咨询和文章,美团的就是生活服务内容。
可选择的模型很多,如协同过滤,逻辑斯蒂回归,基于DNN的模型,FM等。我们使用的方式是,基于内容相似度计算进行召回,之后通过FM模型和逻辑斯蒂回归模型进行精排推荐,下面就分别说一下,我们做这个电影推荐系统过程中,从数据准备,特征工程,到模型训练和应用的整个过程。
我们实现的这个电影推荐系统,爬取的数据实际上维度是相对少的,特别是用户这一侧的维度,正常推荐系统涉及的维度,诸如页面停留时间,点击频次,收藏等这些维度都是没有的,以及用户本身的维度也相对要少,没有地址、年龄、性别等这些基本的维度,这样我们爬取的数据只有打分和评论这些信息,所以之后我们又从这些信息里再拿出一些统计维度来用。我们爬取的电影数据(除电影详情和图片信息外)是如下这样的形式:

这里的数据是有冗余的,又通过如下的代码,对数据进行按维度合并,去除冗余数据条目:
# 处理主函数,负责将多个冗余数据合并为一条电影数据,将地区,导演,主演,类型,特色等维度数据合并
def mainfunc():
try:
unable_list = []
with connection.cursor() as cursor:
sql='select id,name from movie'
cout=cursor.execute(sql)
print("数量: "+str(cout))
for row in cursor.fetchall():
#print(row[1])
movieinfo = df[df['电影名'] == row[1]]
if movieinfo.shape[0] == 0:
disable_movie(row[0])
print('disable movie ' + str(row[1]))
else:
g = lambda x:movieinfo[x].iloc[0]
types = movieinfo['类型'].tolist()
types = reduce(lambda x,y:x+'|'+y,list(set(types)))
traits = movieinfo['特色'].tolist()
traits = reduce(lambda x,y:x+'|'+y,list(set(traits)))
update_one_movie_info(type_=types, actors=g('主演'), region=g('地区'), director=g('导演'), trait=traits, rat=g('评分'), id_=row[0])
connection.commit()
finally:
connection.close()
之后开始准备用户数据,我们从用户打分的数据中,统计出每一个用户的打分的最大值,最小值,中位数值和平均值等,从而作为用户的一个附加属性,存储于userproex表中:
'insert into userproex(userid, rmax, rmin, ravg, rcount, rsum, rmedian) values(\'%s\', %s, %s, %s, %s, %s, %s)' % (userid, rmax, rmin, ravg, rcount, rsum, rmedium)
'update userproex set rmax=%s, rmin=%s, ravg=%s, rmedian=%s, rcount=%s, rsum=%s where userid=\'%s\'' % (rmax, rmin, ravg, rmedium, rcount, rsum, userid)以上两个SQL是最终插入表的时候用到的,代表准备用户数据的最终步骤,其余细节可以参考文末的github仓库,不在此赘述,数据处理还用到了一些SQL,以及其他处理细节。
系统上线运行时,第一次是全量的数据处理,之后会是增量处理过程,这个后面还会提到。
我们目前把用户数据和电影的数据的原始数据算是准备好了,下一步开始特征工程。做特征工程的思路是,对type, actors, director, trait四个类型数据分别构建一个频度统计字典,用于之后的one-hot编码,代码如下:
def get_dim_dict(df, dim_name):
type_list = list(map(lambda x:x.split('|') ,df[dim_name]))
type_list = [x for l in type_list for x in l]
def reduce_func(x, y):
for i in x:
if i[0] == y[0][0]:
x.remove(i)
x.append(((i[0],i[1] + 1)))
return x
x.append(y[0])
return x
l = filter(lambda x:x != None, map(lambda x:[(x, 1)], type_list))
type_zip = reduce(reduce_func, list(l))
type_dict =
for i in type_zip:
type_dict[i[0]] = i[1]
return type_dict涉及到的冗余数据也要删除
df_ = df.drop(['ADD_TIME', 'enable', 'rat', 'id', 'name'], axis=1)将电影数据转换为字典列表,由于演员和导演均过万维,实际计算时过于稀疏,当演员或导演只出现一次时,标记为冷门演员或导演
movie_dict_list = []
for i in df_.index:
movie_dict =
#type
for s_type in df_.iloc[i]['type'].split('|'):
movie_dict[s_type] = 1
#actors
for s_actor in df_.iloc[i]['actors'].split('|'):
if actors_dict[s_actor] < 2:
movie_dict['other_actor'] = 1
else:
movie_dict[s_actor] = 1
#regios
movie_dict[df_.iloc[i]['region']] = 1
#director
for s_director in df_.iloc[i]['director'].split('|'):
if director_dict[s_director] < 2:
movie_dict['other_director'] = 1
else:
movie_dict[s_director] = 1
#trait
for s_trait in df_.iloc[i]['trait'].split('|'):
movie_dict[s_trait] = 1
movie_dict_list.append(movie_dict)使用DictVectorizer进行向量化,做One-hot编码
v = DictVectorizer()
X = v.fit_transform(movie_dict_list)这样的数据,下面做余弦相似度已经可以了,这是特征工程的基本的一个处理,模型所使用的数据,需要将电影,评分,用户做一个数据拼接,构建训练样本,并保存CSV,注意这个CSV不用每次全量构建,而是除第一次外都是增量构建,通过mqlog中类型为‘c‘的消息,增量构建以comment(评分)为主的训练样本,拼接之后的形式如下:
USERID cf2349f9c01f9a5cd4050aebd30ab74f
movieid 10533913
type 剧情|奇幻|冒险|喜剧
actors 艾米·波勒|菲利丝·史密斯|理查德·坎德|比尔·哈德尔|刘易斯·布莱克
region 美国
director 彼特·道格特|罗纳尔多·德尔·卡门
trait 感人|经典|励志
rat 8.7
rmax 5
rmin 2
ravg 3.85714
rcount 7
rmedian 4
TIME_DIS 15这个数据的actors等字段和上面的处理是一样的,为了之后libfm的使用,在这里需要转换为libsvm的数据格式
dump_svmlight_file(train_X_scaling, train_y_, train_file)模型使用上遵循先召回,后精排的策略,先通过余弦相似度计算一个相似度矩阵,然后根据这个矩阵,为用户推荐相似的M个电影,在通过训练好的FM,LR模型,对这个M个电影做偏好预估,FM会预估一个用户打分,LR会预估一个点击概率,综合结果推送给用户作为推荐电影。
模块列表
- recsys_ui: 前端技术(html5+JavaScript+jquery+ajax)
- recsys_web: 后端技术(Java+SpringBoot+mysql)
- recsys_spider: 网络爬虫(python+BeautifulSoup)
- recsys_sql: 使用SQL数据处理
- recsys_model: pandas, libFM, sklearn. pandas数据分析和数据清洗,使用libFM,sklearn对模型初步搭建
- recsys_core: 使用pandas, libFM, sklearn完整的数据处理和模型构建、训练、预测、更新的程序
- recsys_etl:ETL 处理爬虫增量数据时使用kettle ETL便捷处理数据
为了能够输出一个可感受的系统,我们采购了阿里云服务器作为数据库服务器和应用服务器,在线上搭建了电影推荐系统的第一版,地址是:
www.technologyx.cn
可以注册,也可以使用已有用户:
| 用户名 | 密码 |
|---|---|
| gavin | 123 |
| gavin2 | 123 |
| wuenda | 123 |
欢迎登录使用感受一下。

设计思路
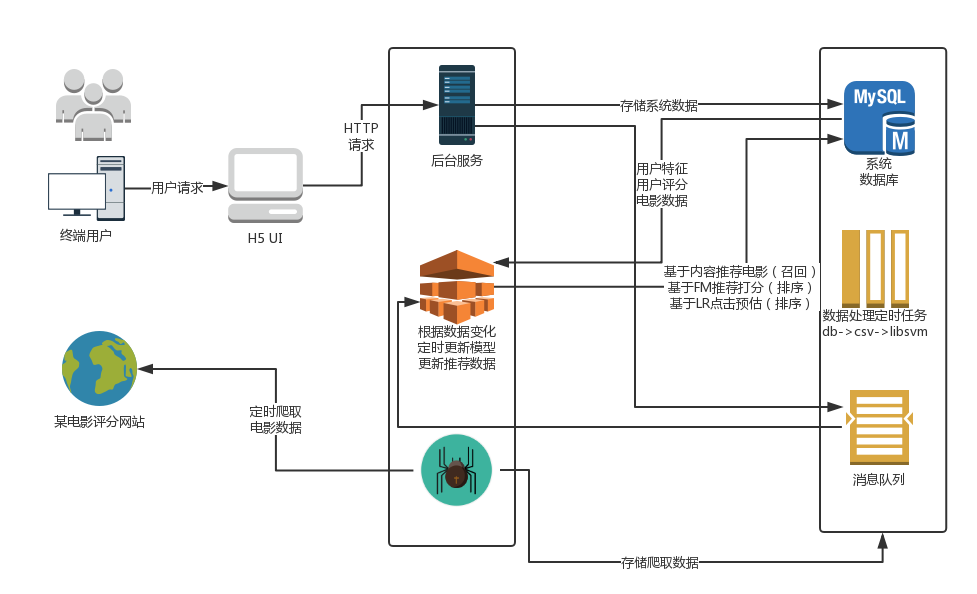
用简单地方式表述一下设计思路,
1.后端服务recsys_web依赖于系统数据库的推荐表‘recmovie’展示给用户推荐内容
2.用户对电影打分后(暂时没有对点击动作进行响应),后台应用会向mqlog表插入一条数据(消息)。
3.新用户注册,系统会插入mqlog中一条新用户注册消息
4.新电影添加,系统会插入mqlog中一条新电影添加消息
5.推荐模块recsys_core会拉取用户的打分消息,并且并行的做以下操作:
a.增量的更新训练样本
b.快速(因服务器比较卡,目前设定了延时)对用户行为进行基于内容推荐的召回
c.训练样本更新模型
d.使用FM,LR模型对Item based所召回的数据进行精排
e.处理新用户注册消息,监听到用户注册消息后,对该用户的属性初始化(统计值)。
f.处理新电影添加消息,更新基于内容相似度而生成的相似度矩阵注:
- 由于线上资源匮乏,也不想使系统增加复杂度,所以没有直接使用MQ组件,而是以数据库表作为代替。
- 项目源码地址: https://github.com/GavinHacker/recsys_core
模型相关的模块介绍
增量的处理用户comment,即增量处理评分模块
这个模块负责监听来自mqlog的消息,如果消息类型是用户的新的comment,则对消息进行拉取,并相应的把新的comment合并到总的训练样本集合,并保存到一个临时目录
然后更新数据库的config表,把最新的样本集合(csv格式)的路径更新上去
运行截图

消息队列的截图

把csv处理为libsvm数据
这个模块负责把最新的csv文件,异步的处理成libSVM格式的数据,以供libFM和LR模型使用,根据系统的性能确定任务的间隔时间
运行截图

基于内容相似度推荐
当监听到用户有新的comment时,该模块将进行基于内容相似度的推荐,并按照电影评分推荐
运行截图
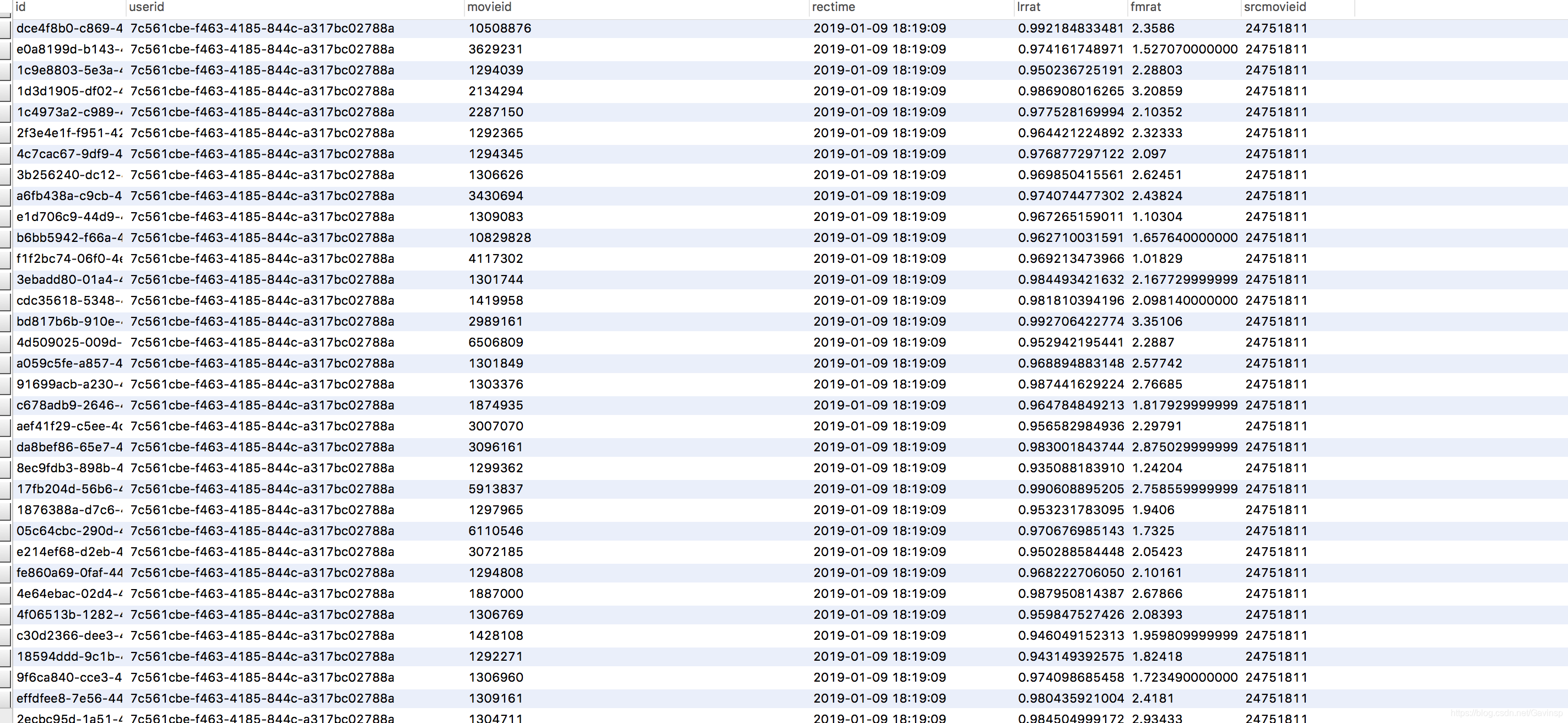
libFM预测
对已有的基于内容推荐召回的电影进行模型预测打分,呈现时按照打分排序
如下图为打分更新

逻辑回归预测
对样本集中的打分做0,1处理,根据正负样本平衡,> 3分为喜欢 即1, <=3 为0 即不喜欢,这样使用逻辑回归做是否喜欢的点击概率预估,根据概率排序
项目源码地址: https://github.com/GavinHacker/recsys_core
python实现基于用户的协同过滤推荐算法构建电影推荐系统
说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后获取。1.项目背景基于用户的协同过滤推荐(User-basedCF)的原理假... 查看详情
机器学习----推荐系统之协同过滤算法
...,评分从0-5,并且为整数,问号处表示没有评分。(二)基于内容的推荐系统给每部电影添加两个features,针对这个问题中分别为romatic和action,范围为1-5,并且给出一部电影这两个参数就已知。这里设,每部电影由xi表示,xi为一... 查看详情
机器学习推荐算法(附例题代码)
...入基于内容的推荐算法协同过滤协同过滤算法均值规范化python实现代码和例题获取推荐算法问题引入现在有一个预测电影评分的问题,共有5部电影,由4个用户进行评分,评分等级为0~5颗星,其中打?号的表示... 查看详情
ml之kg:基于movielens电影评分数据集利用基于知识图谱的推荐算法(networkx+基于路径相似度的方法)实现对用户进行top电影推荐案例(代码片段)
ML之KG:基于MovieLens电影评分数据集利用基于知识图谱的推荐算法(networkx+基于路径相似度的方法)实现对用户进行Top电影推荐案例目录基于MovieLens电影评分数据集利用基于知识图谱的推荐算法(networkx+基于路径相似度的方... 查看详情
[机器学习]电影推荐系统设计
...据项目巩固所学知识,学习的课程是某硅谷的实时推荐和机器学习项目https://www.bilibili.com/video/BV1R4411N78S?p=1以下是我的学习输出:项目框架数据源解析统计推荐模块离线推荐模块实时推荐模块ending:混 查看详情
机器学习---吴恩达---week9_2(推荐系统)
...i,j):用户j给电影i评的分数Content-‐basedrecommendations(基于内容的推荐系统)θ(j):用户j的参数向量x(i):电影i的特征向量(θ(j))Tx(i):用户j对电影i的预测评分m(j):用户j参与评分的电影数量优化目标:优化算法(梯度... 查看详情
基于python的电影数据可视化分析与推荐系统(代码片段)
...进行关键词抽取和情感分析。2.功能组成 基于python的电影数据可视化分析系统的功能组成如下图所示:3.基于python的电影数据可视化分析与推荐系统3.1系统注册登录 系统的其他页面的访问需要注册登录&... 查看详情
推荐系统(recommendersystems):预测电影评分--构造推荐系统的一种方法:基于内容的推荐
如何对电影进行打分:根据用户向量与电影向量的内积我们假设每部电影有两个features,x1与x2。x1表示这部电影属于爱情片的程度,x2表示这部电影是动作片的程度,如Romanceforever里面x1为1.0(说明电影大部分为爱情),x2=0.01(说明里... 查看详情
我的机器学习/数据挖掘的书单
李航的《统计学习方法》这本书开篇第一章写得特别好,各个模型的算法推导也比较全,基本涵盖了比较经典的判别模型和生成模型。 《机器学习实战》这本书代码和应用特别多,了解python用法和机器学习算法的代码实现非... 查看详情
毕业设计-题目:基于协同过滤的电影推荐系统-django在线电影推荐协同过滤(代码片段)
...协同过滤推荐功能去辅助整个系统。学长设计的系统基于Python技术,使用UML建模,采用Django框架组合进行设计,Mysql数据库存储数据。本系统的 查看详情
基于springboot+vue+爬虫实现电影推荐系统(代码片段)
作者主页:编程指南针作者简介:Java领域优质创作者、CSDN博客专家、掘金特邀作者、多年架构师设计经验、腾讯课堂常驻讲师主要内容:Java项目、毕业设计、简历模板、学习资料、面试题库、技术互助文末获取源码... 查看详情
推荐系统案例基于协同过滤的电影推荐(代码片段)
案例--基于协同过滤的电影推荐1.数据集下载2.数据集加载3.相似度计算4.User-BasedCF预测评分算法实现5.Item-BasedCF预测评分算法实现前面我们已经基本掌握了协同过滤推荐算法,以及其中两种最基本的实现方案:User-BasedCF和It... 查看详情
机器学习基础---推荐系统(代码片段)
...:问题规划这一章中将讨论推荐系统的有关内容,它是在机器学习中的一个重要应用。机器学习领域的一个伟大思想:对于某些问题,有一些算法可以自动地学习一系列合适的特征,比起手动设计或编写特征更有效率。这是目前... 查看详情
基于知识图谱的电影推荐问答系统实战
基于知识图谱的电影推荐问答系统实战知识图谱电影推荐系统Demo环境数据集文件结构运行过程声明数据集介绍数据集预处理导入数据库连接数据库驱动清空数据库创建电影实体创建用户实体与评分关系创建电影类型实体加载关... 查看详情
coursera在线学习---第九节.推荐系统
一、基于内容的推荐系统(ContentBasedRecommendations) 所谓基于内容的推荐,就是知道待推荐产品的一些特征情况,将产品的这些特征作为特征变量构建模型来预测。比如,下面的电影推荐,就是电影分为"爱情电影"、“动作电影... 查看详情
java推荐系统-基于用户和物品协同过滤的电影推荐
系统原理该系统使用java编写的基于用户的协同过滤算法(UserCF)和基于物品(此应用中指电影)的协同过滤(ItemtemCF)利用统计学的相关系数经常皮尔森(pearson)相关系数计算相关系数来实现千人千面... 查看详情
微信小程序|基于chatgpt实现电影推荐小程序(代码片段)
文章目录**效果预览**1、根据电影明星推荐2、根据兴趣标签推荐3、根据电影名推荐一、需求背景二、项目原理及架构2.1实现原理(1)根据用户的兴趣标签(2)根据关联类似主题的题材(3)根据特定的电... 查看详情
ng机器学习视频笔记(十四)——推荐系统基础理论
ng机器学习视频笔记(十三)——推荐系统基础理论 (转载请附上本文链接——linhxx) 一、概述 推荐系统(recommendersystem),作为机器学习的应用之一,在各大app中都有应用。这里以... 查看详情