关键词:
python实现
分步
- 划分数据子集(注意区分离散特征值和连续特征值)
#获取数据子集,分类与回归的做法相同
#将数据集根据划分特征切分为两类
def split_dataset(data_x,data_y,fea_axis,fea_value):
'''
input:data_x(ndarry):特征值
data_y(ndarry):标签值
fea_axis(int):进行划分的特征编号(列数)
fea_value(int):进行划分的特征对应特征值
output:data_x[equal_Idx],data_y[equal_Idx](ndarry):特征值等于(大于等于)目标特征值的样本与标签
data_x[nequal_Idx],data_y[nequal_Idx](ndarry):特征值不等于(小于)目标特征的样本与标签
'''
if isinstance(fea_value,float):
#如果特征值为浮点数(连续特征值),那么进行连续值离散化
equal_Idx = np.where(data_x[:,fea_axis]>=fea_value) #找出特征值大于等于fea_alue的样本序号
nequal_Idx = np.where(data_x[:,fea_axis]<fea_value) #找出特征值小于fea_alue的样本序号
else:
equal_Idx = np.where(data_x[:,fea_axis]==fea_value) #找出特征值等于fea_alue的样本序号
nequal_Idx = np.where(data_x[:,fea_axis]!=fea_value) #找出特征值不等于fea_alue的样本序号
return data_x[equal_Idx],data_y[equal_Idx],data_x[nequal_Idx],data_y[nequal_Idx]
- 求解基尼系数(在该数据集相下,随机抽取两个样本,标签不同的概率)
#使用决策树进行分类需要用到
#求解基尼系数,即两个样本不属于同一标签的概率(二分类问题)
def cal_gini(data_y):
'''
input:data_y(ndarry):标签值
output:gini(float):基尼指数
'''
m = len(data_y) #全部样本的标签数量
labels = np.unique(data_y) #获得不同种类的标签(去重)
gini = 1.0 #最后返回的基尼指数
for label in labels:
ans = data_y[np.where(data_y[:]==label)].size/m #该标签的出现概率
gini -= ans*ans #累减计算基尼指数(两两不同的总概率)
return gini
- 最优特征选取以及特征值划分(遍历计算每个特征下每个特征值的基尼系数,取最小值(纯度最高)进行划分标准)
#分类方法实现最优特征的选取以及特征值划分
def classify_get_best_fea(data_x,data_y):
'''
input:data_x(ndarry):特征值
data_y(ndarry):标签值
output:best_fea(int):最优特征
best_fea_val(int):最优特征值
'''
m,n = np.shape(data_x) #m,n分别为样本数以及特征属性数
#初始化
best_fea = -1
best_fea_val = -1
min_fea_gini = np.inf
for i in range(n): #遍历所有特征(列)
feas = np.unique(data_x[:,i]) #获得该特征下所有特征值
#分别以每个特征值为中心进行划分求基尼系数,找到使基尼系数最小的划分
for j in feas:
equal_data_x,equal_data_y,nequal_data_x,nequal_data_y = split_dataset(data_x,data_y,i,j)
fea_gini = 0.0
#计算该划分下的基尼系数
fea_gini = len(equal_data_y)/m*cal_gini(equal_data_y)+len(nequal_data_y)/m*cal_gini(nequal_data_y)
#如果该划分方式的基尼系数更小(纯度更高),那么直接进行更新
if fea_gini<min_fea_gini:
min_fea_gini = fea_gini
best_fea = i
best_fea_val = j
return best_fea,best_fea_val
- 创建分类决策树(使用递归的方法构建决策树字典,注意处理特殊情况:只有一类标签的情况,无特征的情况,当基尼系数过低时也可以中断划分)
#创建分类方法的决策树
def classify_create_tree(data_x,data_y,fea_label):
'''
input:data_x(ndarry):特征值
data_y(ndarry):标签值
fea_label(list):特征属性列表
output:my_tree(dict):生成的CART分类树
'''
labels = np.unique(data_y)
#只有一个标签的情况
if len(labels)==1:
return data_y[0]
#特征集为0的情况,采用多数投票的方法
if data_x.shape[1]==0:
best_fea,best_fea_num = 0,0
for label in labels:
num = data_y[np.where(data_y==label)].size
if num>best_fea_num:
best_fea = label
best_fea_num = num
return best_fea
best_fea,best_fea_val = classify_get_best_fea(data_x,data_y)
best_fea_label = fea_label[best_fea]
print(u"此时最优索引为:"+str(best_fea_label))
my_tree = best_fea_label:
#获得划分结果
equal_data_x,equal_data_y,nequal_data_x,nequal_data_y = split_dataset(data_x,data_y,best_fea,best_fea_val)
#删除最优特征
equal_data_x = np.delete(equal_data_x,best_fea,1)
nequal_data_x = np.delete(nequal_data_x,best_fea,1)
fea_label = np.delete(fea_label,best_fea,0)
#递归生成CART分类树
my_tree[best_fea_label]["_".format(1,best_fea_val)] = classify_create_tree(equal_data_x,equal_data_y,fea_label)
my_tree[best_fea_label]["_".format(0,best_fea_val)] = classify_create_tree(nequal_data_x,nequal_data_y,fea_label)
return my_tree
决策树字典格式为“划分属性”:{“含于该划分值中”,划分结果/继续分类,{“不含于该划分值中”,划分结果/继续分类,注意在判断是否含于该划分值中,构建如“1_划分值”, “0 _划分值”这样的字符串,1表示包含,0表示不包含。如下如所示:

-
测试函数
#测试操作 import re #预测一条测试数据结果 def classify(inputTree,xlabel,testdata): ''' input:inputTree(dict):CART分类决策树 xlabel(list):特征属性列表 testdata(darry):一条测试数据特征值 output:classLabel(int):测试数据预测结果 ''' firstStr = list(inputTree.keys())[0] secondDict = inputTree[firstStr] featIndex = xlabel.index(firstStr)#根据key值得到索引 classLabel = '0'#定义变量classLabel,默认值为0 ans = re.findall(r'\\d+\\.\\d+',list(secondDict.keys())[0]) if isinstance(testdata[featIndex],float): if float(testdata[featIndex]) >= float(ans[0]): if type(secondDict['1_'+ans[0]]).__name__ == 'dict':#判断secondDict[key]是否是字典格式 classLabel = classify(secondDict['1_'+ans[0]], xlabel, testdata)#如果是字典格式,进行递归 else: classLabel = secondDict['1_'+ans[0]] else: if type(secondDict['0_'+ans[0]]).__name__ == 'dict':#判断secondDict[key]是否是字典格式 classLabel = classify(secondDict['0_'+ans[0]], xlabel, testdata)#如果是字典格式,进行递归 else: classLabel = secondDict['0_'+ans[0]] return int(classLabel) else: if float(testdata[featIndex]) == float(ans[0]): if type(secondDict['1_'+ans[0]]).__name__ == 'dict':#判断secondDict[key]是否是字典格式 classLabel = classify(secondDict['1_'+ans[0]], xlabel, testdata)#如果是字典格式,进行递归 else: classLabel = secondDict['1_'+ans[0]] else: if type(secondDict['0_'+ans[0]]).__name__ == 'dict':#判断secondDict[key]是否是字典格式 classLabel = classify(secondDict['0_'+ans[0]], xlabel, testdata)#如果是字典格式,进行递归 else: classLabel = secondDict['0_'+ans[0]] return int(classLabel) #预测所有测试数据结果 def classifytest(inputTree, xlabel, testDataSet): ''' input:inputTree(dict):训练好的决策树 xlabel(list):特征值标签列表 testDataSet(ndarray):测试数据集 output:classLabelAll(list):测试集预测结果列表 ''' classLabelAll = []#创建空列表 for testVec in testDataSet:#遍历每条数据 classLabelAll.append(classify(inputTree, xlabel, testVec))#将每条数据得到的特征标签添加到列表 return np.array(classLabelAll)
源代码(全部)
import numpy as np
import re
#获取数据子集,分类与回归的做法相同
#将数据集根据划分特征切分为两类
def split_dataset(data_x,data_y,fea_axis,fea_value):
'''
input:data_x(ndarry):特征值
data_y(ndarry):标签值
fea_axis(int):进行划分的特征编号(列数)
fea_value(int):进行划分的特征对应特征值
output:data_x[equal_Idx],data_y[equal_Idx](ndarry):特征值等于(大于等于)目标特征值的样本与标签
data_x[nequal_Idx],data_y[nequal_Idx](ndarry):特征值不等于(小于)目标特征的样本与标签
'''
if isinstance(fea_value,float):
#如果特征值为浮点数(连续特征值),那么进行连续值离散化
equal_Idx = np.where(data_x[:,fea_axis]>=fea_value) #找出特征值大于等于fea_alue的样本序号
nequal_Idx = np.where(data_x[:,fea_axis]<fea_value) #找出特征值小于fea_alue的样本序号
else:
equal_Idx = np.where(data_x[:,fea_axis]==fea_value) #找出特征值等于fea_alue的样本序号
nequal_Idx = np.where(data_x[:,fea_axis]!=fea_value) #找出特征值不等于fea_alue的样本序号
return data_x[equal_Idx],data_y[equal_Idx],data_x[nequal_Idx],data_y[nequal_Idx]
#使用决策树进行分类需要用到
#求解基尼指数,即两个样本不属于同一标签的概率(二分类问题)
def cal_gini(data_y):
'''
input:data_y(ndarry):标签值
output:gini(float):基尼指数
'''
m = len(data_y) #全部样本的标签数量
labels = np.unique(data_y) #获得不同种类的标签(去重)
gini = 1.0 #最后返回的基尼指数
for label in labels:
ans = data_y[np.where(data_y[:]==label)].size/m #该标签的出现概率
gini -= ans*ans #累减计算基尼指数(两两不同的总概率)
return gini
#分类方法实现最优特征的选取以及特征值划分
def classify_get_best_fea(data_x,data_y):
'''
input:data_x(ndarry):特征值
data_y(ndarry):标签值
output:best_fea(int):最优特征
best_fea_val(int):最优特征值
'''
m,n = np.shape(data_x) #m,n分别为样本数以及特征属性数
#初始化
best_fea = -1
best_fea_val = -1
min_fea_gini = np.inf
for i in range(n): #遍历所有特征(列)
feas = np.unique(data_x[:,i]) #获得该特征下所有特征值
#分别以每个特征值为中心进行划分求基尼系数,找到使基尼系数最小的划分
for j in feas:
equal_data_x,equal_data_y,nequal_data_x,nequal_data_y = split_dataset(data_x,data_y,i,j)
fea_gini = 0.0
fea_gini = len(equal_data_y)/m*cal_gini(equal_data_y)+len(nequal_data_y)/m*cal_gini(nequal_data_y)
#如果该划分方式的基尼系数更小(纯度更高),那么直接进行更新
if fea_gini<min_fea_gini:
min_fea_gini = fea_gini
best_fea = i
best_fea_val = j
return best_fea,best_fea_val
#创建分类方法的决策树
def classify_create_tree(data_x,data_y,fea_label):
'''
input:data_x(ndarry):特征值
data_y(ndarry):标签值
fea_label(list):特征属性列表
output:my_tree(dict):生成的CART分类树
'''
labels = np.unique(data_y)
#只有一个标签的情况
if len(labels)==1:
return data_y[0]
#特征集为0的情况,采用多数投票的方法
if data_x.shape[1]==0:
best_fea,best_fea_num = 0,0
for label in labels:
num = data_y[np.where(data_y==label)].size
if num>best_fea_num:
best_fea = label
best_fea_num = num
return best_fea
best_fea,best_fea_val = classify_get_best_fea(data_x,data_y)
best_fea_label = fea_label[best_fea]
print(u"此时最优索引为:"+str(best_fea_label))
my_tree = best_fea_label:
#获得划分结果
equal_data_x,equal_data_y,nequal_data_x,nequal_data_y = split_dataset(data_x,data_y,best_fea,best_fea_val)
#删除最优特征
equal_data_x = np.delete(equal_data_x,best_fea,1)
nequal_data_x = np.delete(nequal_data_x,best_fea,1)
fea_label = np.delete(fea_label,best_fea,0)
#递归生成CART分类树
my_tree[best_fea_label]["_".format(1,best_fea_val)] = classify_create_tree(equal_data_x,equal_data_y,fea_label)
my_tree[best_fea_label]["_".format(0,best_fea_val)] = classify_create_tree(nequal_data_x,nequal_data_y,fea_label)
return my_tree
#预测一条测试数据结果
def classify(inputTree,xlabel,testdata):
'''
input:inputTree(dict):CART分类决策树
xlabel(list):特征属性列表
testdata(darry):一条测试数据特征值
output:classLabel(int):测试数据预测结果
'''
firstStr = list(inputTree.keys())[0]
secondDict = inputTree[firstStr]
featIndex = xlabel.index(firstStr)#根据key值得到索引
classLabel = '0'#定义变量classLabel,默认值为0
ans = re.findall(r'\\d+\\.\\d+',list(secondDict.keys())[0])
if isinstance(testdata[featIndex],float):
if float(testdata[featIndex]) >= float(ans[0]):
if type(secondDict['1_'+ans[0]]).__name__ == 'dict':#判断secondDict[key]是否是字典格式
classLabel = classify(secondDict['1_'+ans[0]], xlabel, testdata)#如果是字典格式,进行递归
else:
classLabel = secondDict['1_'+ans[0]]
else:
if type(secondDict['0_'+ans[0]]).__name__ == 'dict':#判断secondDict[key]是否是字典格式
classLabel = classify(secondDict['0_'+ans[0]], xlabel, testdata)#如果是字典格式,进行递归
else:
classLabel = secondDict['0_'+ans[0]]
return int(classLabel)
else:
if float(testdata[featIndex]) == float(ans[0]):
if type(secondDict['1_'+ans[0]]).__name__ == 'dict':#判断secondDict[key]是否是字典格式
classLabel = classify(secondDict['1_'+ans[0]], xlabel, testdata)#如果是字典格式,进行递归
else:
classLabel = secondDict['1_'+ans[0]]
else:
if type(secondDict['0_'+ans[0]]).__name__ == 'dict':#判断secondDict[key]是否是字典格式
classLabel = classify(secondDict['0_'+ans[0]], xlabel, testdata)#如果是字典格式,进行递归
else:
classLabel = secondDict['0_'+ans[0]]
return int(classLabel)
#预测所有测试数据结果
def classifytest(inputTree, xlabel, testDataSet):
'''
input:inputTree(dict):训练好的决策树
xlabel(list):特征值标签列表
testDataSet(ndarray):测试数据集
output:classLabelAll(list):测试集预测结果列表
'''
classLabelAll = []#创建空列表
for testVec in testDataSet:#遍历每条数据
classLabelAll.append(classify(inputTree, xlabel, testVec))#将每条数据得到的特征标签添加到列表
return np.array(classLabelAll)
测试集1(鸢尾花集)
全部属性以及部分标签如下:
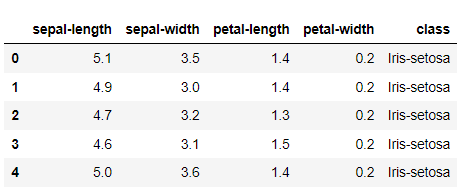 查看详情
查看详情
cart(决策分类树)原理和实现
...很多数量的决策树墩或许我们可以考虑使用更加高级的弱分类器,下面我们看下CART(ClassificationAndRegressionTree)的原理和实现吧CART也是决策树的一种,不过是满二叉树,CART可以是强分类器,就跟决策树一样,但 查看详情
用cart(分类回归树)作为弱分类器实现adaboost
...aboost昨晚集成学习的例子),其后我们分别学习了决策树分类原理和adaboost原理和实现,上两篇我们学习了cart(决策分类树),决策分类树也是决策树的一种,也是很强大的分类器,但是cart的深度太深,我们可以指定cart的深度... 查看详情
课时决策树和随机森林
...单个决策树是如何建造的CARTClassificationAndRegressionTree,即分类回归树算法,简称CART算法,它是决策树的一种实现.CART算法是一种二分递归分割技术,把当前样本划分为两个子样本,使得生成的每个非叶子结点都有两个分支,因此C... 查看详情
决策树(主要针对cart)的生成与剪枝
...、cart的生成。cart的全称是classificationandregressiontree,意为分类回归树。也就是说这类决策树既可以解决分类问题 查看详情
机器学习笔记——cart树
...可以根据特征值的种类生成2个以上的结点。 (2)CART分类树的划分依据是基尼指数(Giniindex)最小化准则,而后两者是根据熵的最小化准则。 (3)CART树可以实现回归和分类两个功能,而后两者只能用作分类。 下面 查看详情
机器学习笔记之三cart分类与回归树
本文结构:CART算法有两步回归树的生成分类树的生成剪枝CART-ClassificationandRegressionTrees分类与回归树,是二叉树,可以用于分类,也可以用于回归问题,最先由Breiman等提出。分类树的输出是样本的类别,回归树的输出是一个实... 查看详情
决策树
CART简介 ClassificationAndRegressionTree,分类回归树,简称CART。通过前面文章的介绍知道了决策树的几种生成方法比如ID3,C4.5等。CART是决策树有一种常见生成方法,既可以用于分类,也可以用于回归。CART假设决策树是二叉树,... 查看详情
cart分类与回归树
...nshu.com/p/b90a9ce05b28本文结构:CART算法有两步回归树的生成分类树的生成剪枝CART-ClassificationandRegressionTrees分类与回归树,是二叉树,可以用于分类,也可以用于回归问题,最先由Breiman等提出。分类树的输出是样本的类别,回归... 查看详情
机器学习决策树理论第二卷
...大家多多指教!本卷的大纲为1CART算法1.1CART回归树1.2CART分类树2CART剪枝3总结1CART算法CART分类与回归树(classificationandregressiontree,CART)模型室友Breiman等人1984年提出,是应用广泛的决策 查看详情
决策树(id3,c4.5,cart)原理以及实现(代码片段)
决策树决策树是一种基本的分类和回归方法.决策树顾名思义,模型可以表示为树型结构,可以认为是if-then的集合,也可以认为是定义在特征空间与类空间上的条件概率分布.[图片上传失败...(image-2e6565-1543139272117)]决策树的中间节点可... 查看详情
数据挖掘十大经典算法--cart:分类与回归树
...策树的类型 在数据挖掘中,决策树主要有两种类型:分类树的输出是样本的类标。回归树的输出是一个实数(比如房子的价格,病人呆在医院的时间等)。术语分类和回归树(CART)包括了上述两种决策树,最先由Breiman等提出.分... 查看详情
决策树算法
...杂的熵来度量,使用了相对较为复杂的多叉树,只能处理分类不能处理回归等。对于这些问题,CART算法大部分做了改进。CART算法也就是我们下面的重点了。由于CART算法可以做回归,也可以做分类,我们分别加以介绍,先从CART... 查看详情
决策树算法
...机器学习中算是很经典的一个算法系列了。它既可以作为分类算法,也可以作为回归算法,同时也特别适合集成学习比如随机森林。本文就对决策树算法原理做一个总结,上篇对ID3,C4.5的算法思想做了总结,下篇重点对CART算法... 查看详情
cart分类与回归树与gbdt(gradientboostdecisiontree)
一、CART分类与回归树资料转载:http://dataunion.org/5771.html ClassificationAndRegressionTree(CART)是决策树的一种,并且是非常重要的决策树,属于TopTenMachineLearningAlgorithm。顾名思义,CART算法既可以用于创建分类树... 查看详情
《机器学习》(周志华)第4章决策树笔记理论及实现——“西瓜树”——cart决策树
CART决策树(一)《机器学习》(周志华)第4章决策树笔记理论及实现——“西瓜树”参照上一篇ID3算法实现的决策树(点击上面链接直达),进一步实现CART决策树。其实只需要改动很小的一部分就可以了,把原先计算信息熵和... 查看详情
基于python实现的决策树模型(代码片段)
决策树模型目录人工智能第五次实验报告1决策树模型1一、问题背景11.1监督学习简介11.2决策树简介1二、程序说明32.1数据载入32.2功能函数32.3决策树模型4三、程序测试53.1数据集说明53.2决策树生成和测试63.3学习曲线评估算法精度... 查看详情
02.基本分类:基于决策树的分类
分类技术主要的分类技术?基于决策树的方法?基于规则的方法?基于实例的方法?贝叶斯信念网络?神经网络?支持向量机分类的两个主要过程训练/学习过程预测/应用过程决策树归纳构建决策树的主要算法-Hunt (最早的决策树归... 查看详情