关键词:
本次介绍假新闻赛道一第一名的构建思路,大家一起学习下
任务描述
文本是新闻信息的主要载体,对新闻文本的研究有助于虚假新闻的有效识别。虚假新闻文本检测,具体任务为:给定一个新闻事件的文本,判定该事件属于真实新闻还是虚假新闻。该任务可抽象为NLP领域的文本分类任务,根据新闻文本内容,判定该新闻是真新闻还是假新闻。针对该任务,本文采用BERT-Finetune、BERT-CNN-Pooling、BERT-RCN-Pooling的多种结构进行融合,在输入上引入字词结合的形式,另外充分利用假新闻的关键词特征进行优化。在智源&计算所-互联网虚假新闻检测挑战赛的假新闻文本识别这个评测任务上,该文提出的方法在最终的评测数据上达到F1为 0.92664的成绩。
模型介绍
模型结构
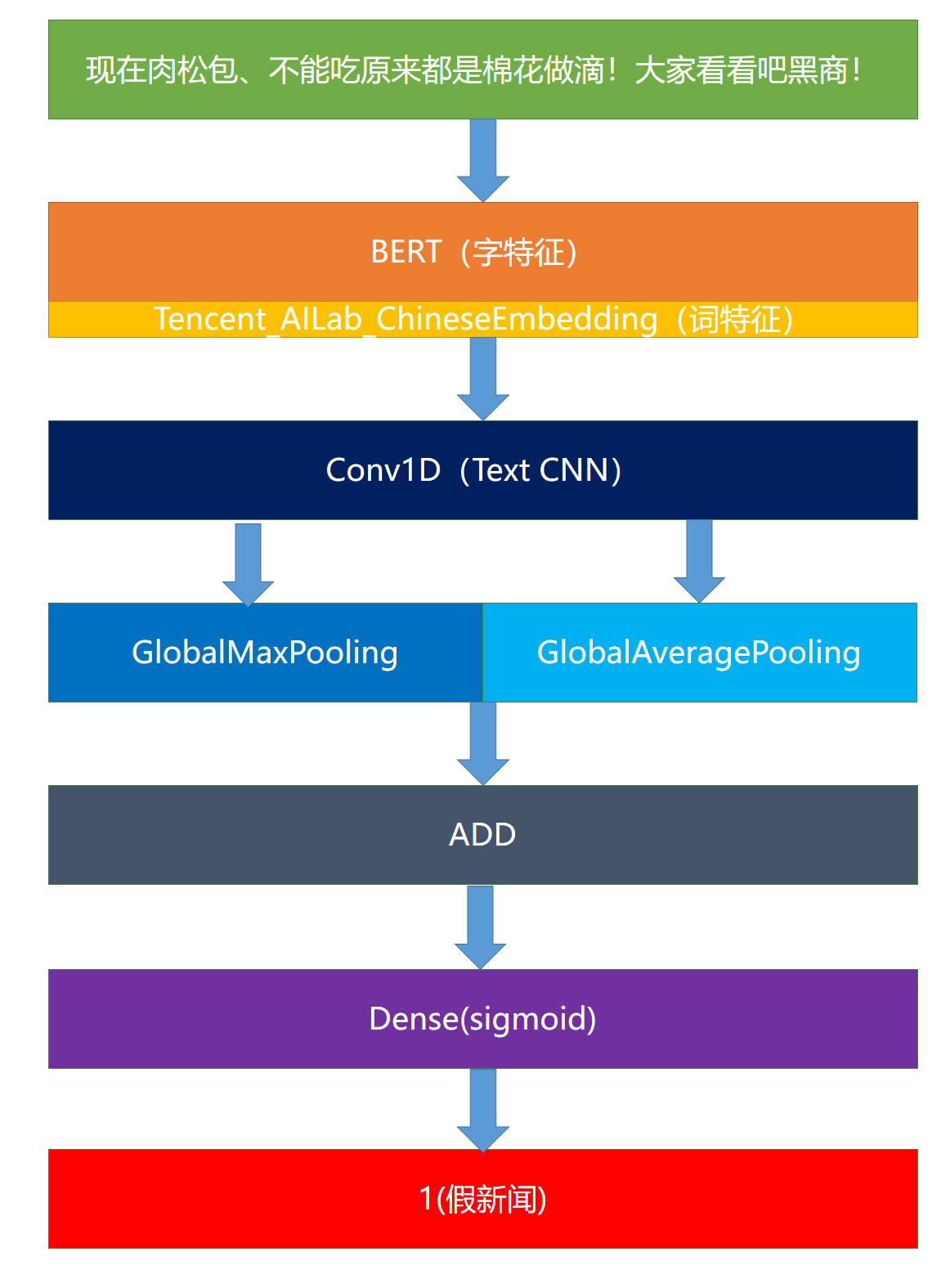
本文采用了多种模型,下以BERT-CNN-Pooling模型为例介绍,见下图。
该模型采用BERT模型提取出字向量(不Finetune),然后结合腾讯词向量,作为最终的词向量输入到1维卷积网络中。在池化过程中同时选择最大池化和平均池化,最后将其结果相加,接入一个Dense层中得到结果。
除了此模型外,本文还是用了BERT-Finetune、BERT-RCN-Pooling模型。
模型参数和融合细节
BERT模型可采用roeberta_zh_L-24_H-1024_A-16,其优点为准确率高,缺点为显存占用率较高。以BERT-Finetune为例,在训练工程中,batch_size选择为4,maxLen选择为164,epoch数选择为3,learning_rate为前两个epoch为1e-5,后一个为1e-6。
本文选择了10折交叉验证,每折中选择召回率较高的模型(一般为第二个epoch或第三个epoch训练出的模型)。另外,由于数据假新闻识别正确率较高,其召回率较低,因此在这10个模型进行融合时,可以将10个模型的直接结果相加,当其大于3认为是假新闻,小于3即为真新闻。
同理,在BERT-CNN-Pooling、BERT-RCN-Pooling模型中也采取以上的融合策略,在BERT-Finetune、BERT-CNN-Pooling、BERT-RCN-Pooling这3个模型间采用该策略(值改为1)。
在模型融合时发现,假新闻喜欢对部分人、地、名词、动词进行造谣。这些词的获取可通过对所有的假新闻和test集合,利用textrank4zh进行关键词获取,最后经过人工筛选,加入到模型融合的评判中,具体为当新闻的关键词含有这些词时,就有假新闻的倾向,此时评判值可以降低,利用这个关键词特征可以发现更多的假新闻,使得假新闻评判效果更好。
实验结果与分析
实验结果见下表,其中评判值即为判断真假新闻的临界值,BERT-RCN-Pooling、BERT-CNN-Pooling的实验结果基本与BERT_Finetune类似。
由表一可知:单模型在真假新闻判定的结果并不是很好,而将单模型进行10折交叉验证后准确率提升很大,说明10折交叉验证还是很有必要的。另外,融合BERT_Finetune+BERT-RCN-Pooling+BERT-CNN-Pooling这三个模型并加上关键词特征也会有不小的提升。
本文使用模型都较为基础,基本是通过交叉验证和模型融合提升测试集得分。在多模型融合上,测试了多种模型,最后处于效果和速度的考虑选择了这三种。

结论
本文介绍了小组参加智源&计算所-互联网虚假新闻检测挑战赛假新闻文本识别评测的基本情况。本文采用BERT-Finetune、BERT-CNN-Pooling、BERT-RCN-Pooling的多种结构进行融合,在每一模型基础上进行10折交叉验证,然后利用假新闻的关键词特征进行优化,最终达到了不错的性能。
代码精华
字词向量结合
def remake(x,num): L = [] for i,each in enumerate(num): L += [x[i]]*each return L words = [t for t in jieba.cut(text)] temp = [len(t) for t in words] x3 = [word2id[t] if t in vocabulary else 1 for t in words] x3 = remake(x3, temp) if len(x3) < maxlen - 2: x3 = [1] + x3 + [1] + [0] * (maxlen - len(x3) - 2) else: x3 = [1] + x3[:maxlen - 2] + [1]
主要思路是把词向量映射到每个字上,如:中国,中国的词向量为a,那么体现在字上即为[a , a],若中国的字向量为[b , c], 相加后即为[a+b, a+c]。此处x3即为对称好的词向量,直接输入到Embedding层即可。
支持mask的最大池化
class MaskedGlobalMaxPool1D(keras.layers.Layer): def __init__(self, **kwargs): super(MaskedGlobalMaxPool1D, self).__init__(**kwargs) self.supports_masking = True def compute_mask(self, inputs, mask=None): return None def compute_output_shape(self, input_shape): return input_shape[:-2] + (input_shape[-1],) def call(self, inputs, mask=None): if mask is not None: mask = K.cast(mask, K.floatx()) inputs -= K.expand_dims((1.0 - mask) * 1e6, axis=-1) return K.max(inputs, axis=-2)
支持mask的平均池化
class MaskedGlobalAveragePooling1D(keras.layers.Layer): def __init__(self, **kwargs): super(MaskedGlobalAveragePooling1D, self).__init__(**kwargs) self.supports_masking = True def compute_mask(self, inputs, mask=None): return None def compute_output_shape(self, input_shape): return input_shape[:-2] + (input_shape[-1],) def call(self, x, mask=None): if mask is not None: mask = K.repeat(mask, x.shape[-1]) mask = tf.transpose(mask, [0, 2, 1]) mask = K.cast(mask, K.floatx()) x = x * mask return K.sum(x, axis=1) / K.sum(mask, axis=1) else: return K.mean(x, axis=1)
Bert Finetune
x1_in = Input(shape=(None,)) x2_in = Input(shape=(None,)) bert_model = load_trained_model_from_checkpoint(config_path, checkpoint_path) for l in bert_model.layers: l.trainable = True x = bert_model([x1_in, x2_in]) x = Lambda(lambda x: x[:, 0])(x) x = Dropout(0.1)(x) p = Dense(1, activation=‘sigmoid‘)(x) model = Model([x1_in, x2_in], p) model.compile( loss=‘binary_crossentropy‘, optimizer=Adam(1e-5), metrics=[‘accuracy‘] )
BERT+TextCNN
x1_in = Input(shape=(None,)) x2_in = Input(shape=(None,)) x3_in = Input(shape=(None,)) x1, x2,x3 = x1_in, x2_in,x3_in x_mask = Lambda(lambda x: K.cast(K.greater(K.expand_dims(x, 2), 0), ‘float32‘))(x1) bert_model = load_trained_model_from_checkpoint(config_path, checkpoint_path) embedding1= Embedding(len(vocabulary) + 2, 200,weights=[embedding_index],mask_zero= True) x3 = embedding1(x3) embed_layer = bert_model([x1_in, x2_in]) embed_layer = Concatenate()([embed_layer,x3]) x = MaskedConv1D(filters=256, kernel_size=3, padding=‘same‘, activation=‘relu‘)(embed_layer ) pool = MaskedGlobalMaxPool1D()(x) ave = MaskedGlobalAveragePooling1D()(x) x = Add()([pool,ave]) x = Dropout(0.1)(x) x = Dense(32, activation = ‘relu‘)(x) p = Dense(1, activation=‘sigmoid‘)(x) model = Model([x1_in, x2_in,x3_in], p) model.compile( loss=‘binary_crossentropy‘, optimizer=Adam(1e-3), metrics=[‘accuracy‘] )
BERT + RNN + CNN
x1_in = Input(shape=(None,)) x2_in = Input(shape=(None,)) x3_in = Input(shape=(None,)) x1, x2,x3 = x1_in, x2_in,x3_in x_mask = Lambda(lambda x: K.cast(K.greater(K.expand_dims(x, 2), 0), ‘float32‘))(x1) bert_model = load_trained_model_from_checkpoint(config_path, checkpoint_path) embedding1= Embedding(len(vocabulary) + 2, 200,weights=[embedding_index],mask_zero= True) x3 = embedding1(x3) embed_layer = bert_model([x1_in, x2_in]) embed_layer = Concatenate()([embed_layer,x3]) embed_layer = Bidirectional(LSTM(units=128,return_sequences=True))(embed_layer) embed_layer = Bidirectional(LSTM(units=128,return_sequences=True))(embed_layer) x = MaskedConv1D(filters=256, kernel_size=3, padding=‘same‘, activation=‘relu‘)(embed_layer ) pool = MaskedGlobalMaxPool1D()(x) ave = MaskedGlobalAveragePooling1D()(x) x = Add()([pool,ave]) x = Dropout(0.1)(x) x = Dense(32, activation = ‘relu‘)(x) p = Dense(1, activation=‘sigmoid‘)(x) model = Model([x1_in, x2_in,x3_in], p) model.compile( loss=‘binary_crossentropy‘, optimizer=Adam(1e-3), metrics=[‘accuracy‘] )
10折交叉训练
for train,test in kfold.split(train_data_X,train_data_Y): model = getModel() t1,t2,t3,t4 = np.array(train_data_X)[train], np.array(train_data_X)[test],np.array(train_data_Y)[train],np.array(train_data_Y)[test] train_D = data_generator(t1.tolist(), t3.tolist()) dev_D = data_generator(t2.tolist(), t4.tolist()) evaluator = Evaluate() model.fit_generator(train_D.__iter__(), steps_per_epoch=len(train_D), epochs=3, callbacks=[evaluator,lrate] ) del model K.clear_session()
关键词特征
def extract(L): return [r.word for r in L] tr4w = TextRank4Keyword() result = [] for sentence in train: tr4w.analyze(text=text, lower=True, window=2) s = extract(tr4w.get_keywords(10, word_min_len=1)) result = result + s c = Counter(result) print(c.most_common(100))
找到词后从其中人工遴选,选出每类的词,另外,在test集合中也运行该代码,同时用jieba辅助分割词的类。
基于tritonserver部署bert模型(代码片段)
背景本文简要介绍如何使用Triton部署BERT模型,主要参考NVIDIA/DeepLearningExamples准备工作下载数据进入到/data/DeepLearningExamples-master/PyTorch/LanguageModeling/BERT/data/squad后,下载数据:bash./squad_download.sh下载模型wget--con 查看详情
2021第五届“达观杯”基于大规模预训练模型的风险事件标签识别3bert和nezha方案(代码片段)
...强4总结和反思5参考资料相关链接【2021第五届“达观杯”基于大规模预训练模型的风险事件标签识别】1初赛Rank12的总结与分析【2021第五届“达观杯”基于大规模预训练模型的风险事件标签识别】2DPCNN、HAN、RCNN等传统深度学习方... 查看详情
基于tritonserver部署bert模型(代码片段)
更多、更及时内容欢迎留意微信公众号:小窗幽记机器学习文章目录背景准备工作下载数据下载模型构建容器模型部署将checkpoint导出为torchscript启动Tritonserver启动自定义的Tritonclient模型部署后的评估:Squad1.1PS:更多、更及... 查看详情
xlnet+bilstm实现菜品正负评价分类(代码片段)
...;包括百度、清华的知识图谱融合,微软在预训练阶段的多任务学习等等,但是这些优化并没有把bert致命缺点进行改进。xlnet作为bert的升级模型,主要在以下三个方面进行了优化采用AR模型替代AE模型,解决mask带来... 查看详情
基于bert模型的文本分类研究:“predictthehappiness”挑战(代码片段)
1.前言在2018年10月,Google发布了新的语言表示模型BERT-“BidirectionalEncoderRepresentationsfromTransformers”。根据他们的论文所言,在文本分类、实体识别、问答系统等广泛的自然语言处理任务上取得了最新的成果。2017年12月,... 查看详情
ros实验笔记之——基于cartographer的多机器人slam地图融合(代码片段)
...仿真笔记之——多移动机器人SLAM地图融合 》已经实现了基于gmapping的多机器人地图融合。实验和仿真都验证过了。本博文通过cartographer来实现SLAM,再做mapmerge先看视频效果two启动的文件#!/bin/bashgnome-terminal--tab-e'bash-c"ro... 查看详情
学习笔记:深度学习——基于pytorch的bert应用实践(代码片段)
学习时间:2022.04.26~2022.04.30文章目录7.基于PyTorch的BERT应用实践7.1工具选取7.2文本预处理7.3使用BERT模型7.3.1数据输入及应用预处理7.3.2提取词向量7.3.3网络建模7.3.4参数准备7.3.5模型训练7.基于PyTorch的BERT应用实践本节着重于将BER... 查看详情
pytorch+huggingface实现基于bert模型的文本分类(附代码)(代码片段)
从RNN到BERT一年前的这个时候,我逃课了一个星期,从澳洲飞去上海观看电竞比赛,也顺便在上海的一个公司联系了面试。当时,面试官问我对RNN的了解程度,我回答“没有了解”。但我把这个问题带回了学校,从此接触了... 查看详情
camera-radar基于ros的多传感器融合感知系统实现(雷达+相机)(代码片段)
实现功能:代码下载地址:下载地址1)基于深度学习的目标检测;2)基于雷达的距离估计和预测;3)多传感器感知结果融合模块。相机感知模块解析4.Runnodes:python3fusion_node/main.pypython3gps_node/main.pypython3radar_node/main 查看详情
camera-radar基于ros的多传感器融合感知系统实现(雷达+相机)(代码片段)
实现功能:代码下载地址:下载地址1)基于深度学习的目标检测;2)基于雷达的距离估计和预测;3)多传感器感知结果融合模块。环境配置、数据下载、节点启动1.InstallROSmelodic:Instructionsareavailableat:http://wiki.ros.org/melodic/Installat... 查看详情
基于空洞卷积的多尺度2d特征融合网络(代码片段)
空洞卷积模块2,来替代编码网络中每一层的卷积,图3.4展示了空洞卷积模块结构,该模块共使用了五个不同尺度的卷积组,分别用扩张率1,2,4,8,16的空洞卷积进行组合,第一组为扩张率为1的3×3卷积,可以得到每一... 查看详情
bert模型解析(代码片段)
...xff0c;即双向Transformer的Encoder表示,是2018年提出的一种基于上下文的预训练模型,通过大量语料学习到每个词的一般性embedding形式,学习到与上下文无关的语义向量表示&# 查看详情
bert模型解析(代码片段)
...xff0c;即双向Transformer的Encoder表示,是2018年提出的一种基于上下文的预训练模型,通过大量语料学习到每个词的一般性embedding形式,学习到与上下文无关的语义向量表示&# 查看详情
模型推理加速系列bert加速方案对比torchscriptvs.onnx(代码片段)
文章目录简介基于ONNX导出ONNX模型示例代码基于TorchScriptJITTorchScript示例代码推理速度评测CPUGPU附录简介本文以BERT-base的为例,介绍2种常用的推理加速方案:ONNX和TorchScript,并实测对比这两种加速方案与原始Pytorch模型... 查看详情
camera-radar基于ros的多传感器融合感知系统实现(雷达+相机)(代码片段)
实现功能:代码下载地址:下载地址1)基于深度学习的目标检测;2)基于雷达的距离估计和预测;3)多传感器感知结果融合模块。雷达感知模块解析4.Runnodes:python3fusion_node/main.pypython3gps_node/main.pypython3radar_node/main.pypython32d_detecti... 查看详情
模型推理加速系列04:bert加速方案对比torchscriptvs.onnx(代码片段)
文章目录简介基于ONNX导出ONNX模型示例代码基于TorchScriptJITTorchScript示例代码推理速度评测CPUGPU附录简介本文以BERT-base的为例,介绍2种常用的推理加速方案:ONNX和TorchScript,并实测对比这两种加速方案与原始Pytorch模型... 查看详情
【论文笔记】融合标签向量到bert:对文本分类进行改进
...,由于其学习情境表示的能力而变得流行起来。这些模型基于多层双向注意机制,并通过MASK预测任务进行训练,这是BERT的两个核心部分。继续研究BERT的潜力仍然很重要,因为新的发现也可以帮助研究BERT的其他变体。在这项工... 查看详情
用tensorflowextended实现可扩展快速且高效的bert部署(代码片段)
...型进行预训练后,数据科学家便可利用这些经过训练的多用途模型来执 查看详情